triangulated
male plumage. ashfield flats, western australia.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 320, 220.0 mm, f/4.0, 1/2000
male plumage. ashfield flats, western australia.
SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 320, 220.0 mm, f/4.0, 1/2000
the magpie-lark can sometimes be mistaken for an australian magpie, and indeed they can both be found on short grass. but this species has a smaller body and beak, much lighter coloured iris, and completely black on the back of the head (no white).
males have a black face and white eyebrow, and females have a white face and no eyebrow, so this is a female.
st mary’s cathedral, western australia.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 800, 146.8 mm, f/4.0, 1/2000

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 640, 146.8 mm, f/4.0, 1/2000
reg bond reserve, western australia.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 160, 220.0 mm, f/4.0, 1/500

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 160, 220.0 mm, f/4.0, 1/500

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 160, 220.0 mm, f/4.0, 1/500
reg bond reserve, western australia.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 100, 220.0 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 100, 220.0 mm, f/4.0, 1/800
this magpie mimics a short-billed black cockatoo, a red wattlebird, a silver gull, and more! can you identify any other bird calls in his repertoire?
st mary’s cathedral, western australia.
SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
boorloo, whadjuk noongar boodja.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 2000, 220.0 mm, f/4.0, 0.5
broun park, western australia.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1600, 220.0 mm, f/4.0, 1/1000

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 125, 220.0 mm, f/4.0, 1/1250

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 400, 220.0 mm, f/4.0, 1/2000
broun park, western australia.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 4000, 183.4 mm, f/4.0, 1/1000
broun park, western australia.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 2500, 220.0 mm, f/4.0, 1/1000
broun park, western australia.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 5000, 220.0 mm, f/4.0, 1/1000

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 4000, 220.0 mm, f/4.0, 1/1000

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 4000, 220.0 mm, f/4.0, 1/1000

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 4000, 220.0 mm, f/4.0, 1/1000

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 4000, 220.0 mm, f/4.0, 1/1000
copenhagen, denmark.
københavn, danmark.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 125, 101.6 mm, f/4.0, 1/800
copenhagen, denmark.
københavn, danmark.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 250, 220.0 mm, f/4.0, 1/400
barcelona, catalonia.
barcelona, catalunya.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 500, 220.0 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 400, 220.0 mm, f/4.0, 1/800
brussels park, brussels.
parc de bruxelles, bruxelles.
warandepark, brussel.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 2500, 220.0 mm, f/4.0, 1/400
barcelona, catalonia.
barcelona, catalunya.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1600, 220.0 mm, f/4.0, 1/640

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1600, 220.0 mm, f/4.0, 1/640

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1600, 219.3 mm, f/4.0, 1/640

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1600, 219.3 mm, f/4.0, 1/640
a coruña, galicia.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 500, 220.0 mm, f/4.0, 1/50
a coruña, galicia.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 800, 146.8 mm, f/4.0, 1/50
a coruña, galicia.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 800, 183.4 mm, f/4.0, 1/50
the hobby is a falcon (Falco longipennis), and falcons are more closely related to cockatoos and other parrots than they are to the other raptors (birds of prey). can you see it in their beak? or their tail, which to me has a striking resemblance to that of a female red-tailed black cockatoo?

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 160, 220.0 mm, f/4.0, 1/1600

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1250, 220.0 mm, f/8.0, 1/1600

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1250, 220.0 mm, f/8.0, 1/1600

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1250, 220.0 mm, f/8.0, 1/1600
leopold park, brussels.
parc léopold, bruxelles.
leopoldpark, brussel.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 200, 49.5 mm, f/4.0, 1/500
leopold park, brussels.
parc léopold, bruxelles.
leopoldpark, brussel.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 640, 220.0 mm, f/4.0, 1/500
leopold park, brussels.
parc léopold, bruxelles.
leopoldpark, brussel.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 2500, 220.0 mm, f/4.0, 1/500

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 2500, 220.0 mm, f/4.0, 1/500
leopold park, brussels.
parc léopold, bruxelles.
leopoldpark, brussel.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 5000, 73.2 mm, f/4.0, 1/500
leopold park, brussels.
parc léopold, bruxelles.
leopoldpark, brussel.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1600, 210.2 mm, f/4.0, 1/250

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1600, 210.2 mm, f/4.0, 1/250
leopold park, brussels.
parc léopold, bruxelles.
leopoldpark, brussel.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 250, 220.0 mm, f/4.0, 1/320
leopold park, brussels.
parc léopold, bruxelles.
leopoldpark, brussel.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 2000, 105.8 mm, f/4.0, 1/250

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 2000, 105.8 mm, f/4.0, 1/250
leopold park, brussels.
parc léopold, bruxelles.
leopoldpark, brussel.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 500, 105.8 mm, f/4.0, 1/250
leopold park, brussels.
parc léopold, bruxelles.
leopoldpark, brussel.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1600, 210.2 mm, f/4.0, 1/250

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1600, 210.2 mm, f/4.0, 1/250
brussels park, brussels.
parc de bruxelles, bruxelles.
warandepark, brussel.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 6400, 220.0 mm, f/4.0, 1/1000
brussels park, brussels.
parc de bruxelles, bruxelles.
warandepark, brussel.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 5000, 220.0 mm, f/4.0, 1/100

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 5000, 220.0 mm, f/4.0, 1/100

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 5000, 220.0 mm, f/4.0, 1/100

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 5000, 220.0 mm, f/4.0, 1/100
brussels park, brussels.
parc de bruxelles, bruxelles.
warandepark, brussel.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 2500, 220.0 mm, f/4.0, 1/250
brussels park, brussels.
parc de bruxelles, bruxelles.
warandepark, brussel.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 6400, 220.0 mm, f/4.0, 1/250

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 6400, 220.0 mm, f/4.0, 1/250

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 6400, 220.0 mm, f/4.0, 1/250

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1600, 220.0 mm, f/4.0, 1/1600

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 320, 220.0 mm, f/4.0, 1/1600

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 160, 220.0 mm, f/4.0, 1/1600

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 800, 220.0 mm, f/4.0, 1/1600
SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 200, 110.1 mm, f/4.0, 1/1600
ISO 200, 110.1 mm, f/4.0, 1/1600
ISO 250, 110.1 mm, f/4.0, 1/1600
then the same for the rest

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1600, 220.0 mm, f/4.0, 1/2000

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 500, 220.0 mm, f/4.0, 1/2000

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 800, 117.3 mm, f/4.0, 1/1000

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1250, 220.0 mm, f/4.0, 1/2000

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1250, 97.5 mm, f/4.0, 1/1000

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 3200, 220.0 mm, f/4.0, 1/1000

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 800, 171.9 mm, f/4.0, 1/2000

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 640, 124.9 mm, f/4.0, 1/2000
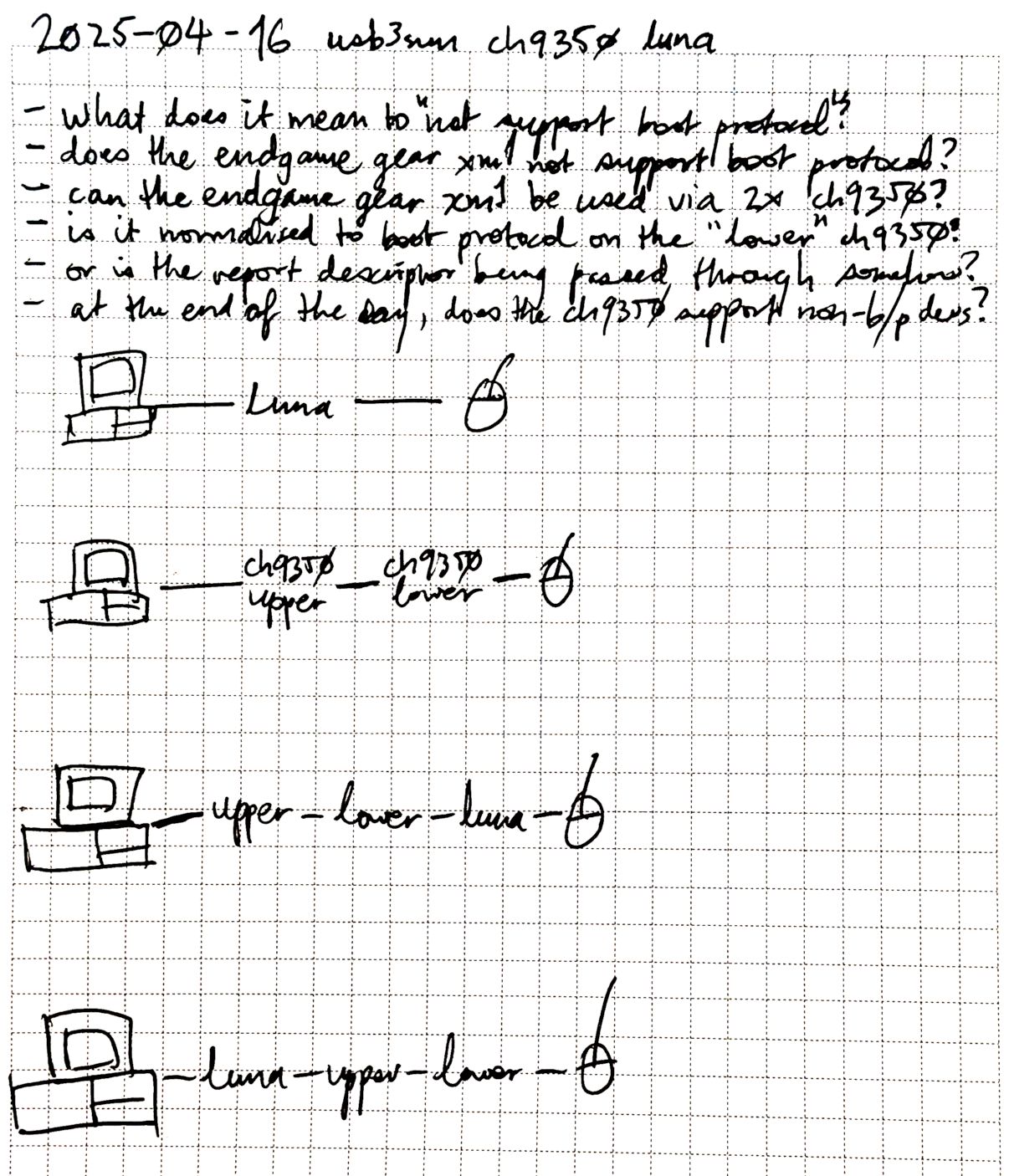
there was a bug in zfs 2.2.0 through 2.2.7, and zfs 2.3.0 through 2.3.1, that can cause data corruption if you use both zpool remove and block cloning (anything that calls ioctl(FICLONE) or copy_file_range(2), including cp --reflink=auto). for more details, see zfs#17180, or these two links.
update to zfs 2.2.8+ or 2.3.2+ as soon as possible. if you are still running an affected zfs version, and you have a pool where feature@device_removal and feature@block_cloning are both active (not just enabled), stop writing to the pool and back up your data now, because the pool may get damaged by further writes.
$ zpool get feature@device_removal,feature@block_cloning
NAME PROPERTY VALUE SOURCE
ocean feature@device_removal active local
ocean feature@block_cloning active local
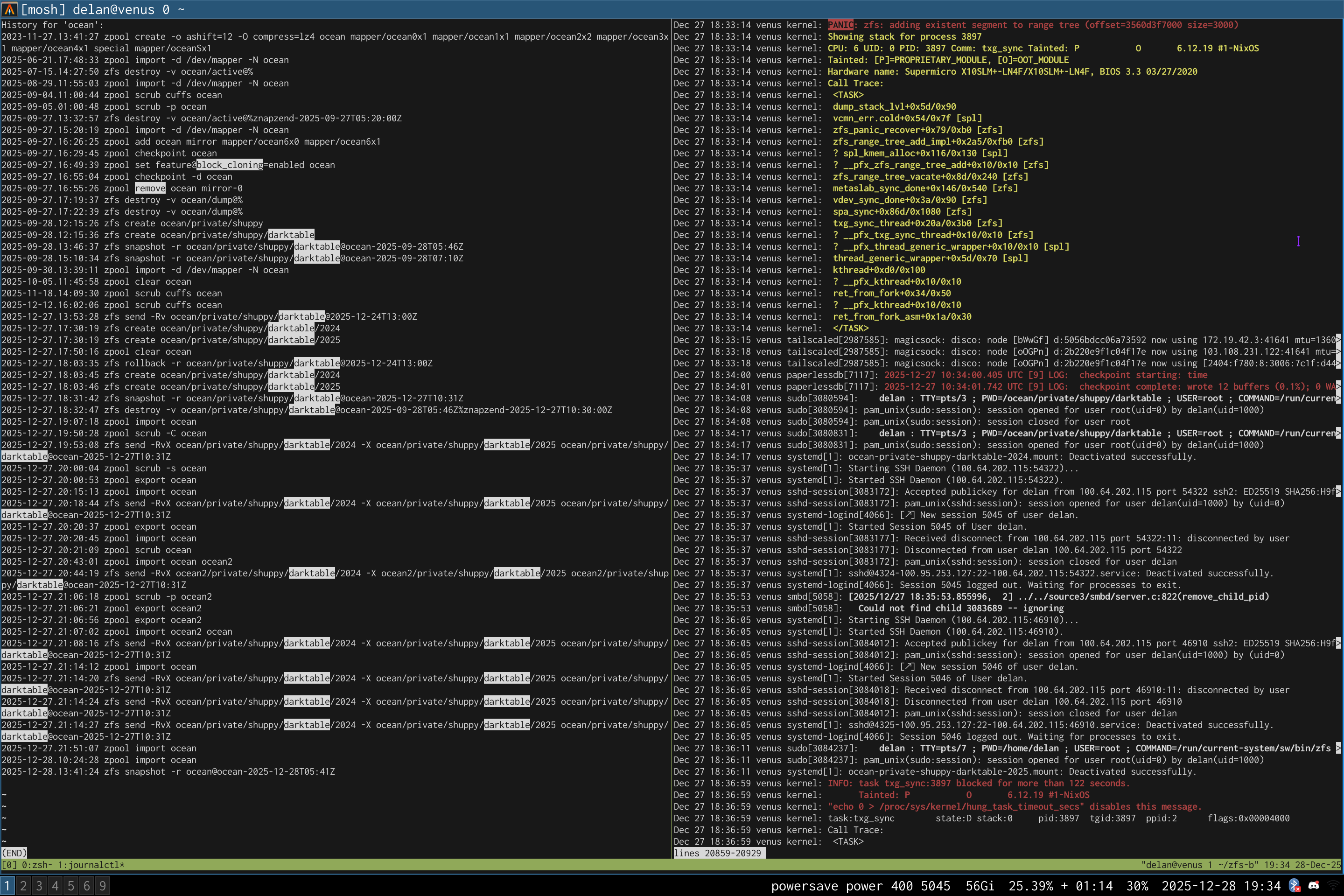
left: zpool history ocean, filtered to the interesting parts.
right: the first PANIC, and the first sign of data corruption.
timeline is as follows:
zpool set feature@block_cloning=enabled oceanzpool remove ocean mirror-0 (mirror ocean0x0 ocean0x1)ocean/private(/delan) to ocean/private/shuppy/darktableocean/private/shuppy/darktable to ocean/private/shuppy/darktable/2024 and .../2025ocean/private/shuppy/darktablePANIC: zfs: adding existent segment to range tree (offset=3560d3f7000 size=3000)i have since had consistent checksum errors when trying to send datasets out of this pool, so this is not theoretical.
on a test pool, albeit only on a machine that still runs zfs 2.3.1:
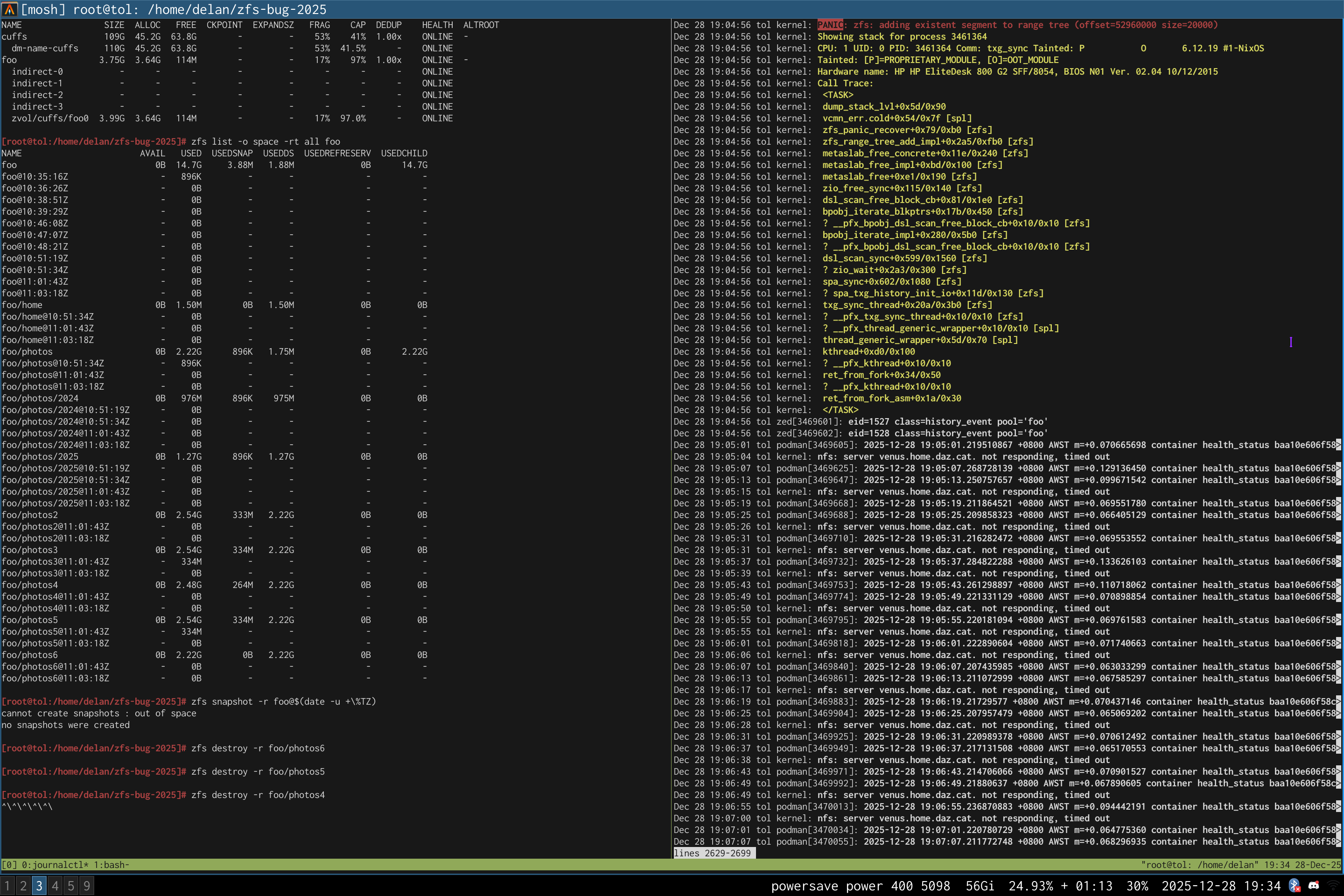
i have a scriptreplay(1) of how i reproduced it, but i would need to clean it up (read: rerecord it) before sharing it publicly. let me know if you need it.
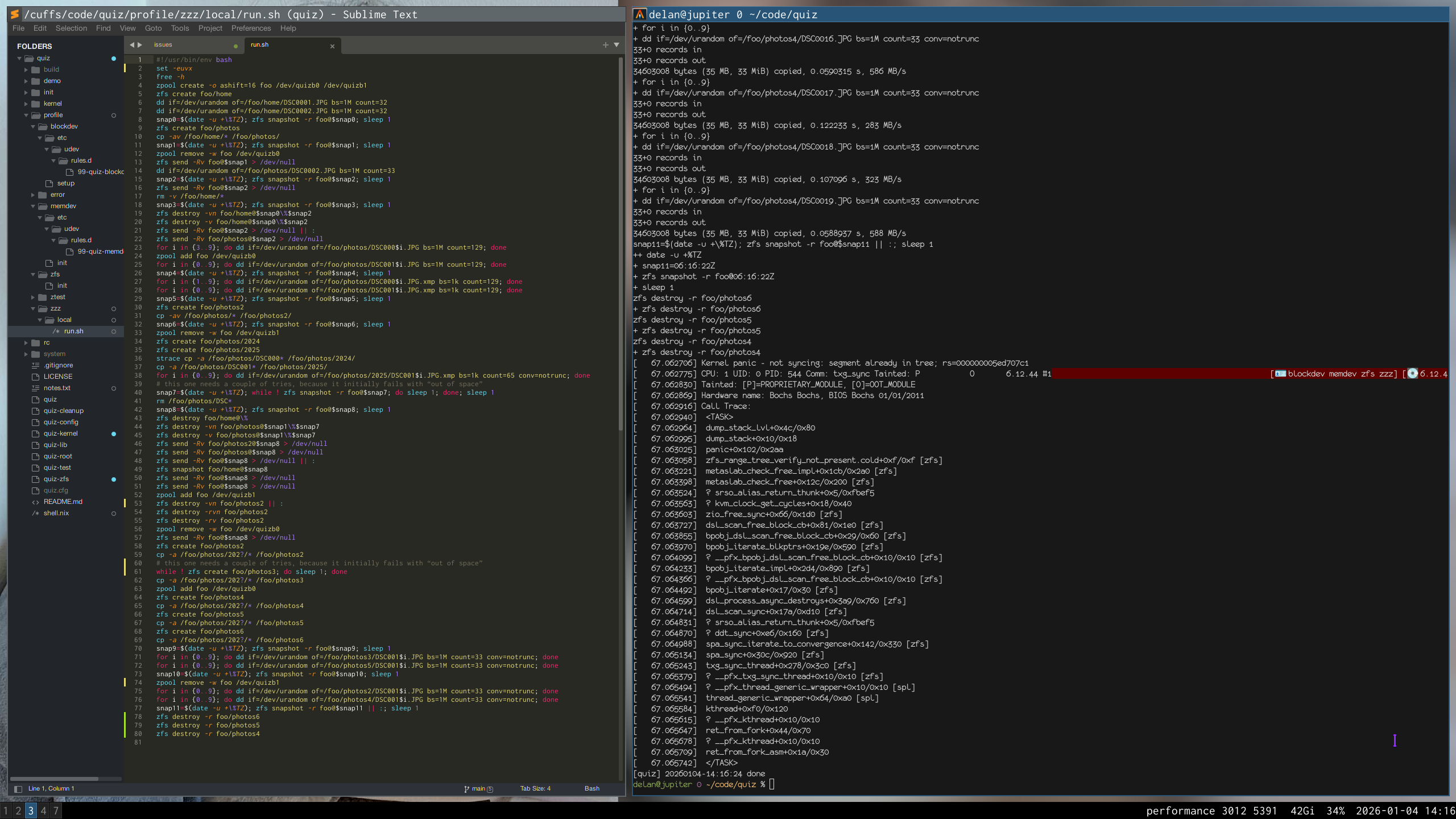
update 2026-01-20: i’ve transcribed the recording and reduced it from over seventy commands to just seven. this is now a regression test in upstream openzfs.
on the whole, zfs has been pretty kind to me. it has kept my data safe since 2015, and i have never truly lost any of my data. but it’s not perfect, and i have run into problems with my Big Pool over the years:
once or twice i had minor repairable corruption after updating freebsd in my old storage vm (2015–2023), though i don’t remember the cause. i think it was something to do with my hypervisor setup?
when migrating my Big Pool from that freebsd vm to the linux host, i went from geli(4) to LUKS2, hitting a gnarly zfs bug that caused tons and tons of minor repairable corruption. this took just over twelve months to fix. many thanks to Rob Norris for getting to the bottom of that one :)
if i were to choose a filesystem to trust, i would choose zfs every time. but no filesystem, no matter how trustworthy it is, can be a substitute for good backup habits and keeping your shit up to date.
this time my backups are older than i would like, so i might lose some of my data. and in general, my approach to computing has been to avoid updating things until i know i need something, because i have too much shit to update and updates often break things, but i could have avoided this by updating to zfs 2.3.2 at any point between may 2025 and september 2025.
you might instead say the lesson is “don’t adopt new features”, because device removal has been around since 2019, but block cloning has only really been around since january 2025 (it first shipped in zfs 2.2.0, but it got killed in 2.2.1). and you probably won’t be surprised to hear that’s what i used to do: as soon as i learned about zpool create -d, i used that whenever i could, carefully deciding which features i wanted on a case-by-case basis and leaving everything else disabled (or even shunning all of those newfangled features with zpool create -o version=28).
but my stance has softened over the last couple years, in part because i now have backups, in part because it turns out solaris-fork-era zfs wasn’t perfect. some bugs took seventeen years to discover and fix!
nothing is perfect. you need backups, and if something is mission critical for you, that something deserves the effort of being kept up to date.
pat o’hara reserve, western australia.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1000, 220.0 mm, f/4.0, 1/2000

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1000, 220.0 mm, f/4.0, 1/2000

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1000, 220.0 mm, f/4.0, 1/2000
if you want to know where black cockatoos hang out, find a marri tree and look down. the shredded remains of its huge woody fruits are a delicacy reserved for only the most powerful of beaks.
pat o’hara reserve, western australia.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 400, 159.7 mm, f/4.0, 1/1000

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1250, 220.0 mm, f/4.0, 1/1000
mckenzie reserve, western australia.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1250, 220.0 mm, f/4.0, 1/1000
mckenzie reserve, western australia.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1250, 128.6 mm, f/4.0, 1/1000
mckenzie reserve, western australia.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1250, 128.6 mm, f/4.0, 1/1000

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 640, 220.0 mm, f/4.0, 1/1000

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 500, 110.1 mm, f/4.0, 1/1000

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 500, 110.1 mm, f/4.0, 1/1000

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 500, 110.1 mm, f/4.0, 1/1000

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 500, 110.1 mm, f/4.0, 1/1000
hoverflies look a bit like bees or wasps from far away, and indeed many of their species hover near flowers, feeding on nectar and pollen. but if you look closer, you notice that they’re actually flies! the easiest tells for me:

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 400, 220.0 mm, f/4.0, 1/1000

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 500, 212.8 mm, f/4.0, 1/1000

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1000, 220.0 mm, f/4.0, 1/2000

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 800, 220.0 mm, f/4.0, 1/3200

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 125, 220.0 mm, f/4.0, 1/1000

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 200, 220.0 mm, f/4.0, 1/3200
offramp to morley drive, tonkin highway northbound, western australia.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 250, 220.0 mm, f/4.0, 1/2000
offramp to morley drive, tonkin highway northbound, western australia.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 200, 220.0 mm, f/4.0, 1/2000

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 200, 220.0 mm, f/4.0, 1/2000
say you wrote a library that provides zero-copy decoding for some protocol by returning checked and typed “views” into packet buffers:
struct Message<'s>(
/* buffer: */ &'s [u8],
/* question_section: */ Range<usize>,
/* answer_section: */ Range<usize>,
/* authority_section: */ Range<usize>,
/* additional_section: */ Range<usize>,
);
struct Question<'s>(&'s [u8], Range<usize>);
struct Name<'s>(&'s [u8], Range<usize>);
impl<'s> Message<'s> {
fn view(buffer: &'s [u8]) -> Result<Self, ()> {
// TODO: check that the message is valid
Ok(Self(buffer, 12..17, 17..28, 28..28, 28..39))
}
}
impl<'s> Question<'s> {
fn view(buffer: &'s [u8], range: Range<usize>) -> Result<Self, ()> {
// TODO: check that the question is valid
Ok(Self(buffer, 12..17))
}
}
impl<'s> Name<'s> {
fn view(buffer: &'s [u8], range: Range<usize>) -> Result<Self, ()> {
// TODO: check that the name is valid
Ok(Self(buffer, 12..13))
}
}
you can read more about the library in this post, but that design goes a long way. like sure, the lifetimes make the types a bit ugly if you have to refer to them^, but they can be used more or less like normal references, as long as you’re careful when projecting from one view to another [playground]:
// BAD: return value bound by lifetimes of both buffer and self
impl Name<'_> {
// equivalent to impl<'s> Name<'s> { fn parent(&'s self) -> Option<Name<'s>> {} }
fn parent(&self) -> Option<Name<'_>> {
// TODO: skip one label, or return None
Some(Name(self.0, 10..14))
}
}
// GOOD: return value only bound by lifetime of the buffer, not self
impl<'s> Name<'s> {
// equivalent to impl<'s> Name<'s> { fn parent(&'s self) -> Option<Name<'s>> {} }
fn parent(&self) -> Option<Name<'s>> {
// TODO: skip one label, or return None
Some(Name(self.0, 10..14))
}
}
fn cat() -> Option<Name<'static>> {
let name = Name::view(b"\x05daria\x03daz\x03cat\0", 0..15).ok()?;
// BAD version won’t compile:
// error[E0515]: cannot return value referencing temporary value
// error[E0515]: cannot return value referencing local variable
Some(name.parent()?.parent()?)
}
^ you should see the types for zero-copy encoding. now those are ugly :)
these views are conceptually just newtypes over subslices of the packet buffer, which may need random access to the full packet buffer due to message compression. what if we could define our views as actual rust references with dipping mustards, but with no lifetimes other than the lifetime of the reference itself?
slices in rust are dynamically sized types (“DST”s), and you can even define a custom DST by defining a struct whose last field is a DST, but what we need is a custom fat pointer. while defining a custom fat pointer requires you to define a custom DST, the values of the fat pointers are not simply the values of the DST.
if we want a newtype U where &U is logically a &[T] with some extra metadata and/or type system assertions, and we want a fn(&[T]) -> &U, the extra metadata needs to go in the fat pointer, not in U. one cool example of that approach is bitvec, which encodes bit-in-byte and byte-in-word indices into newtyped slice fat pointers.
unfortunately… there are
rust provides no stable and officially-sanctioned way to do that, at least until rfc 2580 is stabilised. bitvec relies on the current representation of slice fat pointers, which may change in a future version of rust, requiring a source update.
all fat pointers are currently two pointers wide, so we can only really pack extra metadata into the low-order alignment bits of the pointer, or the second word. there have been ideas for loosening that in this rfc and rfc 1524 and rfc 2594, but for now, two words is all we get.
and if we pack arbitrary metadata into a slice fat pointer, it has to be a [()] pointer internally, not a [T] pointer, otherwise the pointer and length would be invalid. clearly it would require unsafe code, but what’s unclear to me is whether that unsafe code can be sound. for example, miri with stacked borrows rejects the code below (and rejects bitvec), but with tree borrows accepts it. and since the eventual aliasing model will apparently likely fall somewhere “between” stacked borrows and tree borrows, the code below may be unsound.
so if we want a newtype for “subslice” references, the best i can manage is to pack the subslice bounds into the length field, which limits the two indices to u16 each on 32-bit platforms. it currently depends on compiler internals that may change someday, but the only alternative seems to be an unstable feature. and it can’t even fully access the original slice, because there’s no space for the original length.
here’s what that looks like [playground]:
/// conceptually a `&[u8][i..j]` that retains access to the original slice.
pub struct Subslice(#[allow(dead_code)] [()]);
impl Subslice {
pub fn view(source: &[u8], range: impl RangeBounds<usize>) -> &Self {
let range = range.normalise(source);
let range = convert_range_to_u16(range);
let metadata = pack_range_into_slice_pointer_metadata(range);
let result = make_unit_slice_ref(source, metadata);
unsafe { transmute(result) }
}
pub fn range(&self) -> Range<usize> {
let repr: SliceFatPointer = unsafe { transmute(self) };
let range = unpack_range_from_slice_pointer_metadata(repr.len);
range.start.into()..range.end.into()
}
pub fn original_slice(&self) -> &[u8] {
// TODO: can’t get the original len, because we’ve used it for the subslice.
// for now, we just return `&source[0..end]`, which is the best we can do.
let repr: SliceFatPointer = unsafe { transmute(self) };
let source = repr.data as *const u8;
let range = self.range();
unsafe { core::slice::from_raw_parts(source, range.end.into()) }
}
}
fn make_unit_slice_ref(source: &[u8], extra: usize) -> &[()] {
let source = source.as_ptr();
let source: *const () = unsafe { transmute(source) };
// SAFETY: this upholds the invariants of `from_raw_parts`:
// - `data` is non-null, because `source` was a reference, and references are non-null
// - `data` (`source`) is valid for reads for `len * size_of::<T>()` many bytes, because `T`
// is `()`, so the size of `()` is 0, so `len * size_of::<T>()` is 0 for all `len` (`extra`)
// - `data` is properly aligned, because the alignment of `()` is 1
// - ??? does `data` point to `len` consecutive properly initialised values of type `()`?
// it points to properly initialised values of type `T`, which i’m not sure counts?
// - the memory referenced will not be mutated for the duration of the result’s lifetime,
// because the lifetime is set to that of `source` via lifetime elision
// - the total size `len * size_of::<T>()` is not larger than `isize::MAX`, and it will not
// overflow if added to `data`, because it is zero (see above)
unsafe { core::slice::from_raw_parts(source, extra) }
}
fn pack_range_into_slice_pointer_metadata(range: Range<u16>) -> usize {
usize::from(range.start) << 16 | usize::from(range.end)
}
fn unpack_range_from_slice_pointer_metadata(metadata: usize) -> Range<u16> {
let start = u16::try_from(metadata >> 16 & 0xffff).expect("guaranteed by mask");
let end = u16::try_from(metadata & 0xffff).expect("guaranteed by mask");
start..end
}
/// type with identical layout to `&[()]`... for now.
#[repr(C)]
struct SliceFatPointer {
data: *const (),
len: usize,
}
impl AsRef<[u8]> for Subslice {
fn as_ref(&self) -> &[u8] {
let repr: SliceFatPointer = unsafe { transmute(self) };
let source = repr.data as *const u8;
let range = self.range();
let base = unsafe { source.add(range.start.into()) };
let len = range.end - range.start;
unsafe { core::slice::from_raw_parts(base, len.into()) }
}
}
#[test]
fn test() {
let sub: &Subslice = Subslice::view(b"abcdefg", 2..5);
assert_eq!(sub.as_ref(), b"cde");
// TODO: currently fails (see TODO above)
// assert_eq!(sub.original_slice(), b"abcdefg");
assert_eq!(sub.original_slice(), b"abcde");
}


SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 100, 220.0 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1250, 220.0 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1250, 220.0 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1250, 220.0 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1250, 220.0 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1250, 220.0 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 800, 220.0 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 3200, 220.0 mm, f/4.0, 1/1250

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 400, 220.0 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 400, 220.0 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 400, 220.0 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 400, 220.0 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 100, 220.0 mm, f/4.0, 1/800
this bird seems to be a hybrid between the port lincoln parrot (B. z. zonarius) and the twenty-eight parrot (B. z. semitorquatus). notice the presence of both yellow belly and red above the beak respectively.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 125, 220.0 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 200, 220.0 mm, f/4.0, 1/400
SONY DSC-RX10M4 + 8.8-220mm f/2.4-4

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 100, 220.0 mm, f/4.0, 1/200
currently known as baudin’s black cockatoo, but i prefer long-billed because it’s more descriptive and not named after some dead colonist (see also pink cockatoo). i used to have trouble distinguishing them from their short-billed siblings, but now i think that’s because i had only seen the short-billed species.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 100, 219.8 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 250, 220.0 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 250, 220.0 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 200, 220.0 mm, f/4.0, 1/800
silently and effortlessly gliding over woodlands, near victoria dam, western australia.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 200, 220.0 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 100, 174.9 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 200, 220.0 mm, f/4.0, 1/800
male in breeding plumage, near victoria dam, western australia.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 160, 220.0 mm, f/4.0, 1/1000

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 160, 220.0 mm, f/4.0, 1/1000

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 160, 220.0 mm, f/4.0, 1/1000
i never realised our magpies can have a hooked beak, just like butcherbirds. makes sense, they’re closely related and in fact are from the same family.
poor bloke might have lost an eye :(

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1600, 219.8 mm, f/4.0, 1/640

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 2000, 219.3 mm, f/4.0, 1/640

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 640, 220.0 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1000, 220.0 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 160, 220.0 mm, f/4.0, 1/800
what if web servers could serve up a static site where custom headers and/or status code can be prepended just like they are in http? like you could set up a redirect by just having the file be (note no version)
HTTP 301
Location: /some/place/else
or set the charset of a text file with
Content-Type: text/plain; charset=Shift_JIS
your text here
rather than using some web-server-specific config format. you would also need a file extension or similar on disk to signal the presence of a “header”, but that can be hidden with rewrite rules.
has anyone done this? i guess it would only make sense if the format was specified in an interoperable way.
oh sick, this exists!! i don’t know if it caught on outside of apache, but mod_asis lets you take any file with (say) .asis extension and treat it as cgi output. that format is already specified in rfc 3875, including a way to optionally set the status. so you can do a redirect by creating some /var/www/foo.asis with like
Status: 301
Location: /some/place/else
you could even use this to make your own tiny link shortener. currently my solution for this with nginx is a shell script that appends a location rule to a config fragment somewhere like
$ go.sh https://example.com/bar
https://go.example.com/i2jc
$ tail -1 /etc/nginx/go.conf
location = /i2jc { return 303 https://example.com/bar; }
and it has to reload nginx, because it’s a config change. but this would mean the script could just create /var/www/i2jc.asis as above :)
what if web servers could serve up a static site where custom headers and/or status code can be prepended just like they are in http? like you could set up a redirect by just having the file be (note no version)
HTTP 301
Location: /some/place/else
or set the charset of a text file with
Content-Type: text/plain; charset=Shift_JIS
your text here
rather than using some web-server-specific config format. you would also need a file extension or similar on disk to signal the presence of a “header”, but that can be hidden with rewrite rules.
has anyone done this? i guess it would only make sense if the format was specified in an interoperable way.
the largest pardalote, whereas the spotted pardalote is the smallest. but even so, this is not a large bird by any means; it’s probably somewhere between 9 and 15 grams.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 640, 220.0 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 640, 220.0 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 640, 220.0 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 640, 220.0 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 800, 220.0 mm, f/4.0, 1/800
there were so many grey currawongs that morning at the weir. i saw them and heard them calling from every direction the whole time i was there.
most recordings of grey currawong calls are for subspecies that are not found in western australia, and those other subspecies sound completely different to our “leaden crow-shrikes”. these two are the only recordings i’ve found for our subspecies, S. v. plumbea, and only the former was what i heard.
notice the clarity of each note as it falls off, and now imagine how eerie several concurrent currawongs would sound echoing through a valley.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 500, 220.0 mm, f/4.0, 1/400
ohhhhhh my god, a ringneck walked right up to me, flew up onto the dam pipeline, and met me at eye level less than a metre away. they chirped a few times, inspected me, then left. sadly i missed the focus on most of these, but look at how close they got, even before any of that!! 35mm equivalent: 600, 600, 600, 278, 278, 341mm

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 2000, 220.0 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1600, 220.0 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1000, 220.0 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1250, 101.6 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1250, 101.6 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 800, 124.9 mm, f/4.0, 1/800

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 800, 78.4 mm, f/4.0, 1/200
mundaring weir is a good place to see black cockatoos. indeed the first blockies i ever photographed were just down the road from there, and the pipeline itself is decorated with them. while standing on the dam wall, i hear those unmistakable rusty windmills cross the water from afar. i still had my shutter speed set for landscapes. oh well.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 160, 220.0 mm, f/5.6, 1/125

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 100, 220.0 mm, f/5.6, 1/125

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 200, 14.2 mm, f/3.2, 1/400

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 320, 90.5 mm, f/4.0, 1/400
got there like a minute before a water corp guy came out to unlock the gates to the dam wall. that layer of fog, delicately draped over the trees across the water, only stuck around for about an hour.

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 1000, 8.9 mm, f/8.0, 1/125

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 800, 8.8 mm, f/8.0, 1/125

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 400, 8.8 mm, f/8.0, 1/125

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 125, 8.8 mm, f/7.1, 1/125
it’s sunday, and our alarms go off at 3am. my ouppy is going to adelaide, and her flight is in three hours. we hang out in the terminal until the queue for the gate has lost any last crumb of plausible deniability, then we hang out in the queue until her boarding pass gets scanned and we’re forced to part, then i stand there until she rounds the corner, then that familiar feeling washes over me. i’m going home alone.
we have a train line to home and a train line to the airport now, but it was 4am, so we had neither. i send her a picture of the payment terminal in the carpark. omg look, an older lady. it’s an iUC180B. i love her. baby.



the thing about birds is that dawn is by far the best time to find them, but i’m not usually awake until at least 8am. and now i’m leaving the airport right before the sun comes up. so i take this opportunity to head to mundaring weir, hoping to see some black cockatoos.
while i’m on the highway, i see a plane out my driver’s side window, then fly literally overhead, so i pull over as soon as i can and check flightradar24. that’s my ouppy!!
so keep that in mind when you see my photos over the next couple days :)
how do we add caching to a static site generator? quoth last episode:
we need a way to know if a post has changed, or any of its attachments have changed, since it was last rendered or its metadata was last cached, and we also need to know what tag pages will need to be rerendered.
after a bunch of experimentation, i think nix is pretty much what we want, but nix doesn’t really work on windows, so it can’t be nix, so let’s build our own nix :3
none of this has landed on the main branch yet, for good reason. it’s probably buggy as shit, so don’t run it on your real blog yet.
in the autost#54 patch as of 218670e77f08e:
this blog is my cohost archive plus a couple hundred newer posts. that’s 4803 posts (9816 if you count posts referenced by replies), and ~4.7 GB of attachments.
| no cache | cold cache | warm cache | |
|---|---|---|---|
| rendering the site | 828 ms | 1731 ms | 385 ms (−53.5%) |
| rendering after edit | 438 ms | ||
| querying a tag | 236 ms | 1045 ms | 90 ms (−61.8%) |
$ export RUST_LOG=autost=warn
$ time autost render --skip-attachments
9.36s user 1.30s system 1287% cpu 0.828 total
$ time autost render --skip-attachments --use-cache
10.26s user 3.97s system 821% cpu 1.731 total
$ time autost render --skip-attachments --use-cache
1.02s user 1.53s system 661% cpu 0.385 total
$ unset RUST_LOG
$ time autost render --skip-attachments --use-cache
INFO build{function=ReadFile id=b0143e6e233ed...}: autost::cache: building
INFO build{function=RenderMarkdown id=e0c542ce051e2...}: autost::cache: building
INFO build{function=FilteredPost id=5ad850559c540...}: autost::cache: building
INFO build{function=Thread id=799f2c033be6a...}: autost::cache: building
INFO build{function=RenderedThread id=844c6195470bd...}: autost::cache: building
INFO build{function=Thread id=9dda7da0c21ae...}: autost::cache: building
INFO build{function=RenderedThread id=eac9c7f17c6f8...}: autost::cache: building
INFO autost::cache: writing cache pack 5ad
INFO autost::cache: writing cache pack 9dd
INFO autost::cache: writing cache pack 799
INFO autost::cache: writing cache pack e0c
INFO autost::cache: writing cache pack eac
INFO autost::cache: writing cache pack 844
INFO autost::cache: writing cache pack b01
1.27s user 1.72s system 681% cpu 0.438 total
$ unset RUST_LOG
$ time autost cache test --list-threads-in-tag usb3sun --use-cache
37 threads in tag "usb3sun":
- "2023-01-06T18:08:35.092Z", "posts/787278.html", "SPARCstations have a unique serial-like interface "
- "2023-06-23T17:15:54.361Z", "posts/1742287.html", "usb3sun is an adapter that lets you connect usb ke"
- "2023-06-24T17:50:23.538Z", "posts/1650431.html", "SPARCstations have a unique serial-like interface "
[...]
INFO autost::cache: writing cache pack 372
0.49s user 0.93s system 410% cpu 0.347 total
$ rm -R cache
$ export RUST_LOG=autost=warn
$ time autost cache test --list-threads-in-tag usb3sun
1.77s user 0.27s system 864% cpu 0.236 total
$ time autost cache test --list-threads-in-tag usb3sun --use-cache
2.39s user 2.77s system 493% cpu 1.045 total
$ time autost cache test --list-threads-in-tag usb3sun --use-cache
0.07s user 0.30s system 412% cpu 0.090 total
ok but what if i merged the cohost archives of everyone i followed into one very big archive? that’s 146752 posts (309140 if you count posts referenced by replies), and ~64 GB of attachments.
| no cache | cold cache | warm cache | |
|---|---|---|---|
| rendering the site | 24.90 s | 35.75 s | 11.18 s (−55.1%) |
| querying a tag | 5.551 s | 11.67 s | 1.547 s (−72.1%) |
$ export RUST_LOG=autost=warn
$ time autost render --skip-attachments
258.96s user 49.31s system 1237% cpu 24.902 total
$ time autost render --skip-attachments --use-cache
309.85s user 72.00s system 1067% cpu 35.755 total
$ time autost render --skip-attachments --use-cache
33.57s user 44.87s system 701% cpu 11.188 total
$ unset RUST_LOG
$ time autost cache test --list-threads-in-tag usb3sun
37 threads in tag "usb3sun":
- "2023-01-06T18:08:35.092Z", "posts/787278.html", "SPARCstations have a unique serial-like interface "
- "2023-06-23T17:15:54.361Z", "posts/1742287.html", "usb3sun is an adapter that lets you connect usb ke"
- "2023-06-24T17:50:23.538Z", "posts/1650431.html", "SPARCstations have a unique serial-like interface "
[...]
2025-08-28T09:39:27.095295Z INFO autost::cache: writing cache pack 857
14.77s user 18.37s system 381% cpu 8.692 total
$ rm -R cache
$ export RUST_LOG=autost=warn
$ time autost cache test --list-threads-in-tag usb3sun
34.12s user 5.86s system 720% cpu 5.551 total
$ time autost cache test --list-threads-in-tag usb3sun --use-cache
57.26s user 32.47s system 768% cpu 11.673 total
$ time autost cache test --list-threads-in-tag usb3sun --use-cache
1.47s user 5.72s system 464% cpu 1.547 total
anyway! i repeat, how do we add caching to a static site generator?
make is an incremental build system, where “incremental” means it only rebuilds things that have changed. it does this with file timestamps and a dependency graph: a file needs to be rebuilt if any of its dependencies are newer than it.
this is inadequate, because you can easily change the timestamp without changing the contents or change the contents without changing the timestamp. and good luck if you want to simultaneously cache more than one version of a build product.
this is also unnecessarily frugal, except for attachments, as we’ll see shortly.
nowadays reading files is pretty fast, as long as they’re stored on an ssd. let’s write a little microbenchmark to see just how fast it can be. all of these results were taken on my framework 13 with an AMD 7840U and a charger connected.
$ autost cache benchmark <posts|posts-recursive|attachments> sum-paths-len <10..=100>
$ autost cache benchmark <posts|posts-recursive|attachments> sum-read-len <10..=100>
$ autost cache benchmark <posts|posts-recursive|attachments> blake3 <10..=100>
$ autost cache benchmark <posts|posts-recursive|attachments> blake3-mmap-rayon <10..=100>
it looks like reading and hashing all of the posts doesn’t even double the time taken to walk the tree, but doing all of the attachments would incur an over 30x time penalty.
| time to walk | and read | and blake3 | |
|---|---|---|---|
| 4803 posts | 5.62 ms | 9.69 ms | 9.94 ms (1.76x) |
| 9816 posts (recursive) | 11.32 ms | 18.24 ms | 19.21 ms (1.69x) |
| 5520 attachments | 14.48 ms | 458.0 ms | 508.9 ms (35.1x) |
again it’s less than a 2x penalty if we read and hash the posts, but an over 30x penalty for attachments.
| time to walk | and read | and blake3 | |
|---|---|---|---|
| 146752 posts | 197.6 ms | 298.2 ms | 313.5 ms (1.58x) |
| 309140 posts (recursive) | 388.9 ms | 612.6 ms | 630.3 ms (1.62x) |
| 126626 attachments | 326.4 ms | 9417 ms | 11027 ms (33.7x) |
another way of looking at it is, if we’re gonna have to read a bunch of files, we might as well hash them so we can easily check if they’ve changed. again this doesn’t make sense for attachments, whose contents are never actually read by autost render. i’m not sure i have a good solution for attachments yet.
rendering your site involves many steps:
we don’t just want to cache the final build outputs (html pages and atom feeds), because the intermediate build steps are also useful for things like querying metadata. so how do we build a cache for all of the different kinds of build steps without descending into cache invalidation and ad-hoc serialisation hell?
many of these steps are pretty much functions (in the mathematical sense) that take some input and transform it to some output. in fact, all of them are, although some of them are easier to describe that way than others.
nix is a build system and package manager that uses this observation to build the largest ever single repository of software with efficient binary caching. how can we apply its ideas here?
imagine the process of loading a thread, just enough to know its metadata like its tags and what attachments it references:
now let’s say we described each of these steps as a function. note that for the caching to work correctly, it’s very important that aside from readFile(), all of the other functions are pure. they can only use their input arguments, which is why makeThread() can’t take one post and load all of the other posts it references from disk.
each of those functions just Builds The Thing. to make them cacheable and allow us to run them with maximum parallelism, we want to be able to make a “build plan” that completely describes how to Build The Thing without doing all of the work of actually Building The Thing.
let’s describe the build planning as a second set of functions:
one problem we run into with makeThreadPlan() is that we need the metadata of one of the posts to know what other loadPost() calls to include in the result. this is unfortunate, because it means we can’t entirely avoid Building The Thing when doing build planning.
let’s say we’re building the thread for 10000216.md, which replies to 10000215.md. makeThreadPlan(10000216.md) returns the build plan below. it was relatively easy to compute, and it completely describes how to load the thread from the files that make up the thread.
“makeThread(loadPost(renderMarkdown(readFile(10000216.md, 44062ae08bb67…))), loadPost(renderMarkdown(readFile(10000215.md, 8adba2770e58c…))))”
remember the “(more on hash later)” from earlier? if the build plan for a thread includes the hash of each of its posts, then we can hash the build plan and get an ID that changes if and only if any of the posts have changed.
and with that kind of unique ID for each thing we build, caching is easy! since the contents of the build plan for a given ID can’t possibly change (by definition), and the contents of the output really shouldn’t change (if we wrote our build logic correctly), we never need to delete or update anything, except maybe to free up disk space.
to me, this is the essence of nix, and i had great fun capturing that essence in our funny little static site generator. if you wanna see how this ersatz nix works, check out src/cache.rs and src/cache/drv.rs ^w^
that’s the post. but if you’re hungry for even more detail, read on…
processing thousands or even hundreds of thousands of posts is hard work. some things that helped with cache storage bottlenecks:
Vec<u8> until neededautost cache test --list-threads-in-tag builds a “tag index” to more efficiently look up posts having the given tag, but it was hard to do this in a way that wasn’t slower than just computing the metadata from scratch. two things made it possible.
the build plans themselves were expensive, because for each evaluation we had to deserialise a big tree of inputs from ThreadDrv to FilteredPostDrv to RenderMarkdownDrv and finally down to ReadFileDrv. plus load their outputs into the memory cache for no reason. we fixed this by hiding everything other than ReadFileDrv from the build plan, inferring them within the TagIndexDrv builder. idk about this… it feels like cheating or subverting how nix is supposed to work?
the obvious representation of the tag index is a HashMap or BTreeMap, but this has to be deserialised in full on first use without any parallelism, which is a waste unless our query involves the whole dataset. instead we can build a tiny sqlite database and serialise it to Vec<u8>, then serialise that as the build output. since sqlite can obviously query a table without building a whole map in memory, this is much faster.
i’ve started working on autost again, with the hope i can tackle some of the problems i wrote about in april. so far, i’ve been cautiously experimenting with adding a database, which again, seems to be unavoidable if we want autost to be anything more than a Cohost Archive You Can Keep Posting To. but this can solve other problems too!
none of this has landed on the main branch yet, for good reason. it’s probably buggy as shit, so don’t run it on your real blog yet.
to publish a new post, we need to choose a new post id, and our current approach is pretty minimalist (derogatory):
id = 10000000posts/{id}.mdid = id + 1this is obviously inefficient, because it gets slower and slower the more posts you’ve made, and it doesn’t even work correctly if your last post was a .html post.
we could cache the last post id in a text file, and that sounds easy at first, but storing data in text files gets complicated fast. now you have to worry about things like
and all of these are solved problems if we use an actual database. here’s a simple sqlite database that solves our post id problems:
CREATE TABLE "post" (
"post_id" INTEGER PRIMARY KEY AUTOINCREMENT -- e.g. 10000250
, "path" TEXT NOT NULL -- e.g. '10000250.md'
, "rendered_path" TEXT NULL UNIQUE -- e.g. '10000250.html'
);
since the "rendered_path" is UNIQUE, we can’t accidentally create a "path" = '10000250.md' and a "path" = '10000250.html' that both have "rendered_path" = '10000250.html'. and choosing the next post id so we can publish a new post is easy:
BEGIN;
-- no "post_id", so we generate it with AUTOINCREMENT.
-- empty "path", because we don’t know it yet.
INSERT INTO "post" ("path") VALUES ('');
-- now we check the “last insert id”, which is done outside sql.
-- let’s say it’s 10000250.
UPDATE "post" SET "path" = '10000250.md' WHERE "post_id" = 10000250;
COMMIT;
check out autost#53 for the complete patch.
right now, answering questions like “what posts are tagged #birds?” takes about as long as rendering your whole site, because in both cases we have to read all of your posts, parse the html, and extract the metadata. and when you publish or edit a post, we have to render your whole site from scratch.
this is generally how static site generators work, and Computer Touchers like that because having your whole blog be a bunch of text files is (a) elegant and (b) works well with version control. but the average Computer Toucher also has one (1) blog post, titled “New Year, New Blog, or: How I Learned To Stop Worrying and Switch From Twelvety to Sext.js”, so we should take their opinions with a grain of salt.
static site generators do have other benefits though. they’ve got good data portability, and static sites are easy to host on any web server, even web servers that are free because Big Coding is using them as a loss leader.
so maybe we want something in between, where your post files are still the primary source of truth, but we cache the metadata that we extract from them in the database, or we cache the fact that the post has already been rendered.
that will leave us with one of the two hard problems in computer science: now we need a way to know if a post has changed, or any of its attachments have changed, since it was last rendered or its metadata was last cached, and we also need to know what tag pages will need to be rerendered. hmm. is this just nix?
<pebble> i'm gonna buy out ingenico and verifone and i'm gonna make them kiss
top to bottom: female, male

NIKON D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 1800, 300.0 mm, f/5.6, 1/800

NIKON D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 2200, 300.0 mm, f/5.6, 1/800

NIKON D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 1400, 300.0 mm, f/5.6, 1/800

NIKON D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 1400, 300.0 mm, f/5.6, 1/800

NIKON D3200 + AF-S DX Nikkor 55-300mm f/4.5-5.6G ED VR
ISO 800, 300.0 mm, f/5.6, 1/500

NIKON D3200 + AF-S DX Nikkor 55-300mm f/4.5-5.6G ED VR
ISO 2800, 300.0 mm, f/5.6, 1/1000

NIKON D3200 + AF-S DX Nikkor 55-300mm f/4.5-5.6G ED VR
ISO 220, 300.0 mm, f/5.6, 1/1000

NIKON D3200 + AF-S DX Nikkor 55-300mm f/4.5-5.6G ED VR
ISO 200, 300.0 mm, f/5.6, 1/1000

NIKON D3200 + AF-S DX Nikkor 55-300mm f/4.5-5.6G ED VR
ISO 220, 300.0 mm, f/5.6, 1/1000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 500, 250.0 mm, f/5.6, 1/4000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 2000, 250.0 mm, f/5.6, 1/2000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 800, 250.0 mm, f/5.6, 1/2000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 500, 250.0 mm, f/5.6, 1/4000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 1000, 250.0 mm, f/5.6, 1/4000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 400, 250.0 mm, f/5.6, 1/4000

SONY DSC-RX10M4 + 8.8-220mm f/2.4-4
ISO 6400, 97.5 mm, f/4.0, 1/200

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 200, 250.0 mm, f/5.6, 1/1000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 640, 166.0 mm, f/5.6, 1/2000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 12800, 216.0 mm, f/5.6, 1/1000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 640, 250.0 mm, f/5.6, 1/1000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 1000, 250.0 mm, f/5.6, 1/1000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 2000, 250.0 mm, f/5.6, 1/2000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 1250, 250.0 mm, f/5.6, 1/2000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 1000, 250.0 mm, f/5.6, 1/2000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 500, 250.0 mm, f/5.6, 1/2000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 500, 250.0 mm, f/5.6, 1/2000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 640, 250.0 mm, f/5.6, 1/2000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 640, 250.0 mm, f/5.6, 1/2000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 640, 250.0 mm, f/5.6, 1/2000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 640, 250.0 mm, f/5.6, 1/2000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 640, 250.0 mm, f/5.6, 1/2000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 640, 250.0 mm, f/5.6, 1/2000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 1250, 250.0 mm, f/5.6, 1/2000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 5000, 250.0 mm, f/8.0, 1/1250

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 2500, 250.0 mm, f/5.6, 1/1000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 2500, 250.0 mm, f/5.6, 1/1000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 2500, 250.0 mm, f/5.6, 1/1000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 5000, 250.0 mm, f/5.6, 1/2000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 320, 250.0 mm, f/5.6, 1/125

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 5000, 250.0 mm, f/5.6, 1/2000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 12800, 250.0 mm, f/5.6, 1/2000
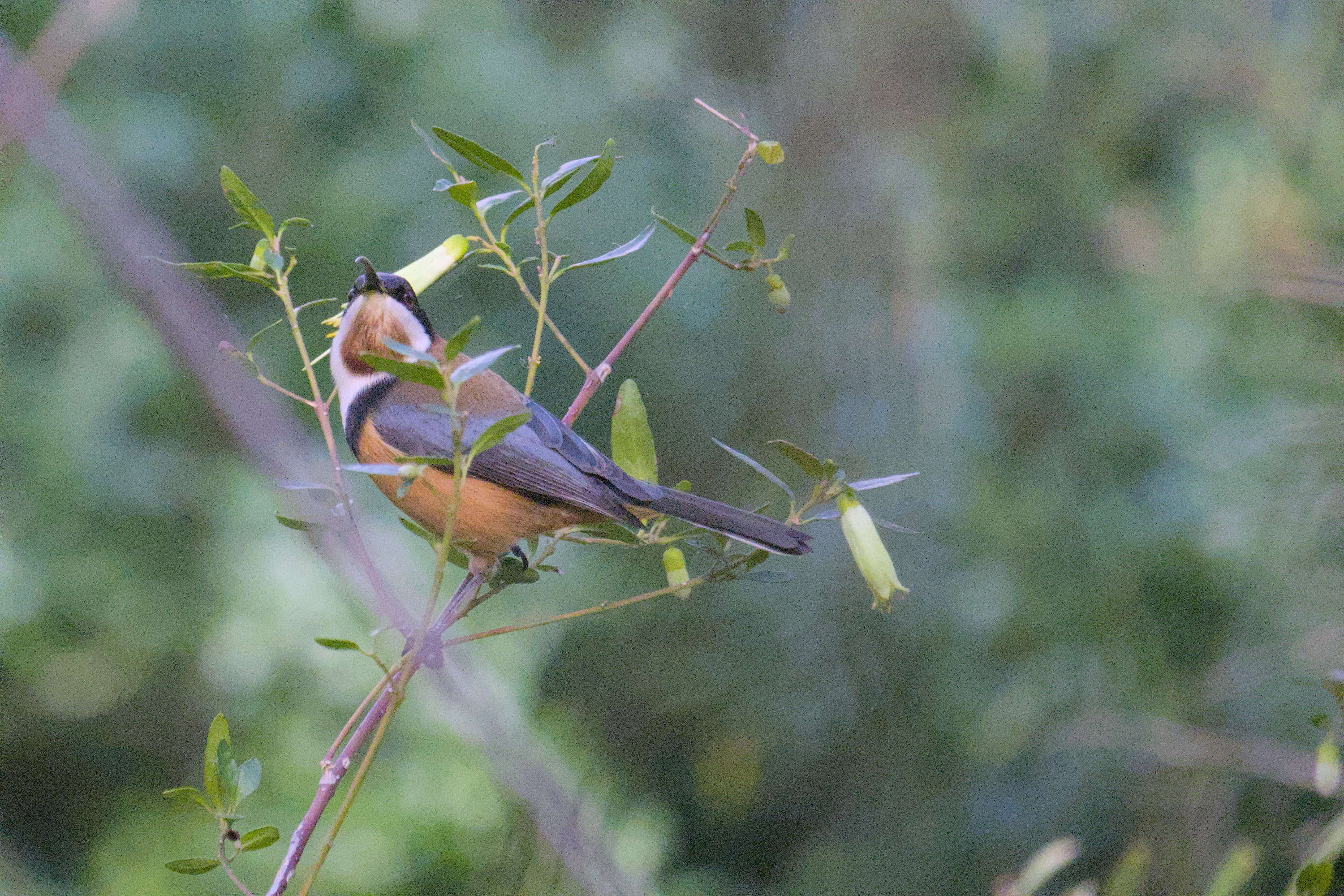
FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 12800, 250.0 mm, f/5.6, 1/2000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 1600, 250.0 mm, f/5.6, 1/2000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 1600, 250.0 mm, f/5.6, 1/2000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 1600, 250.0 mm, f/5.6, 1/2000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 500, 200.0 mm, f/5.6, 1/2000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 6400, 135.0 mm, f/5.6, 1/2000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 1600, 250.0 mm, f/5.6, 1/2000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 1600, 250.0 mm, f/5.6, 1/2000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 1600, 250.0 mm, f/5.6, 1/2000
see also

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 8000, 250.0 mm, f/5.6, 1/1000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 6400, 180.0 mm, f/5.6, 1/1000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 5000, 250.0 mm, f/5.6, 1/1000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 10000, 117.0 mm, f/5.0, 1/1000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 8000, 117.0 mm, f/5.0, 1/1000

FUJIFILM X-T30 II + Canon EF-S 24mm f/2.8 STM
ISO 2500, 24.0 mm, f/2.8, 1/2000

FUJIFILM X-T30 II + Canon EF-S 24mm f/2.8 STM
ISO 160, 24.0 mm, f/2.8, 1/1800

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 2500, 60.0 mm, f/6.3, 1/2500

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 1250, 55.0 mm, f/11.0, 1/500

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 5000, 250.0 mm, f/5.6, 1/2000
by pebble age 24

Canon EOS 1000D + Canon EF 75-300mm f/4-5.6
ISO 400, 110.0 mm, f/5.0, 1/250
FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 5000, 250.0 mm, f/5.6, 1/2000
yellow-billed chough? i think?

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 2500, 250.0 mm, f/6.3, 1/2000
thanks to nina for lending me her short lenses :3

FUJIFILM X-T30 II + Canon EF-S 24mm f/2.8 STM
ISO 160, 24.0 mm, f/5.6, 1/350

FUJIFILM X-T30 II + Canon EF-S 24mm f/2.8 STM
ISO 160, 24.0 mm, f/8.0, 1/140

FUJIFILM X-T30 II + Canon EF-S 24mm f/2.8 STM
ISO 160, 24.0 mm, f/8.0, 1/340

FUJIFILM X-T30 II + Canon EF-S 24mm f/2.8 STM
ISO 160, 24.0 mm, f/8.0, 1/210
per artigo 7 da ordenanza municipal para a protección e tenencia de animais:
- Prohíbese a circulación ou permanencia de cans e outros animais nas praias en período estival, definido este como o comprendido entre o 1 de xuño e o 30 de setembro.

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 320, 250.0 mm, f/6.3, 1/1000
as the wind blows, it carries what looks like hundreds of tiny snowflakes or feathers across the benches and paths. it wasn’t snowing, and these were not feathers, but it was very pretty.

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 3200, 250.0 mm, f/5.6, 1/2500

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 12800, 250.0 mm, f/10.0, 1/2000
FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 5000, 250.0 mm, f/5.6, 1/3200

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 2000, 250.0 mm, f/5.6, 1/1000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 4000, 250.0 mm, f/5.6, 1/1000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 4000, 250.0 mm, f/5.6, 1/1000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 800, 250.0 mm, f/5.6, 1/1000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 5000, 250.0 mm, f/5.6, 1/2500

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 2500, 250.0 mm, f/5.6, 1/1250

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 3200, 166.0 mm, f/6.3, 1/2000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 2500, 250.0 mm, f/6.3, 1/2000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 5000, 250.0 mm, f/6.3, 1/2000

FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 400, 55.0 mm, f/13.0, 1/250






FUJIFILM X-T30 II + Canon EF-S 55-250mm f/4.0-5.6 IS STM
ISO 500, 250.0 mm, f/6.3, 1/2000
check out this series of posts by jasper st. pierre et al about how the x window system works, plus some 2d rasterisation techniques:
https://magcius.github.io/xplain/article/index.html
the figures are demos that use a tiny canvas-based x server they wrote in js!
check out this fascinating post by raph levien about how vsync works (defer swapping until scanout completes, but only block when actually writing to the new backbuffer), how double and triple buffering typically work, and how these techniques improve throughput at the expense of latency, jitter, and/or power consumption.
vsync means rendering and running your updates as early as possible, right after scanout completes. it’s simple, but it makes the frame you present as stale as possible.
“frame pacing” means rendering and running your updates as late as possible, right before the next scanout starts. it makes the frame you present as fresh as possible, but it’s more complicated, because you need to estimate how long your work will take.
see also, how the compositors we have today regress on latency compared to “racing the beam”.
see also, why it’s surprisingly hard to write an app that resizes smoothly on the left edge.
history of the android webview
why webkit on android?
new WPEPlatform API
next steps
“render pacing”
imagine
customElements.define('name', Name, {version: 2})next steps
how does this compare to appending the version to the element name itself?
what is jsr and why does it exist?
cool features
how impls get packages from jsr
future steps
what is wintercg wintertc?
finding a standards body
current work
minimum common api
[Exposed=*], which is in turn the subset allowed in any shadow realmadditional conformance levels
join the meetings!
juicy numbers (output size, mean runtime, mean rss)
hi_bun 97M 55ms 75MBhi_deno 100M 16ms 31MBhi_porffor 20K <1ms 1.4MBhi_javy 1.3M - - (javy is a js to wasm compiler)hi_porffor_wasm 4.0K - -github canadahonk/porffor
current limitations
impl challenges
uh huh.
this seems a little unrealistic
she’s non-threatening (can’t stop sneezing)
latest wtyp taught me about the 1981 patco strike of air traffic controllers in the usa. this strike was broken by the reagan administration:
On August 3, 1981, over 13,000 ATCs went on strike. […] Two days into the strike, the Reagan administration gave the striking ATCs 48 hours to return to their jobs. Only 875 union members returned to work following Reagan’s request. During this time, new ATCs were being trained and replacing the striking union members. […] Only 1,300 of the striking workers were able to retain their jobs, and none of them attained their demands.
see also the 1998 australian port lockout, where the howard government actively helped patrick corporation fire over 1400 unionised dock workers.

NIKON D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 900, 300.0 mm, f/7.1, 1/1000

NIKON D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 4000, 300.0 mm, f/7.1, 1/1000

NIKON D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 280, 210.0 mm, f/7.1, 1/1000

NIKON D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 2200, 170.0 mm, f/7.1, 1/1000

NIKON D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 2200, 170.0 mm, f/7.1, 1/1000
Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
Google Pixel 8
PROBLEM: i want to edit this video to fix the exposure and colour, like i do for my still photos
👼: learn how to use a video editor
😈: convert to png, batch edit the frames in darktable, convert to h264
back on my bullshit (editing frames of a video in darktable)
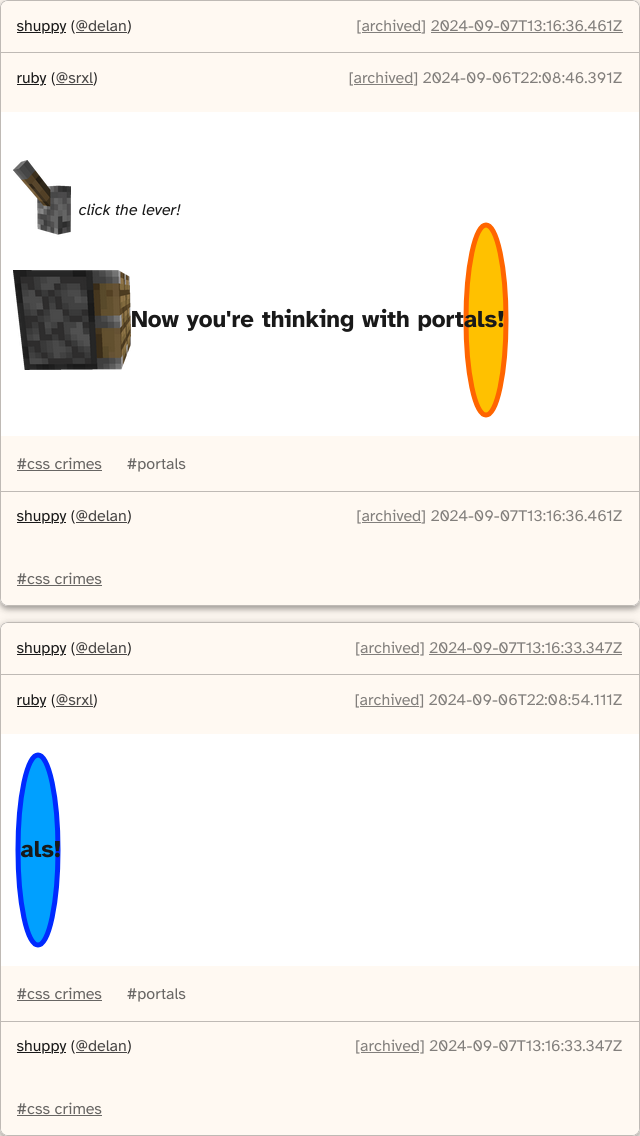
Blackle Mori shows a few of the hacks from Cohost.org before the community shut down for good. Use these if you dare, lest you too get labelled a CSS criminal.
my one contribution to the css criminology was the password protected eggbug. i wish cohost stuck around long enough to see the full potential of <details name> crimes. to my knowledge, the only such crime was this one by ruby, but i’m happy to be corrected!
cohost will be missed, but eggbug lives on in all of us. thanks for keeping it alive @suricrasia@lethargic.talkative.fish and @csstricks@mastodon.social!

the ch9350 is looking viable as a usb host for the next rev of usb3sun!
it’s more reliable than tinyusb, and after today’s stream, we’ve figured out that it won’t come at the expense of non-boot-protocol device support (which we don’t yet have but we want to implement).
writeup soon >:3

NIKON D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 1400, 300.0 mm, f/7.1, 1/1000

ISO 1600, 300.0 mm, f/9.0, 1/1000

ISO 2200, 300.0 mm, f/9.0, 1/1000
got a sparcstation but no keyboard or mouse? tired of having to reprogram your idprom over and over?
usb3sun lets you connect usb keyboards and mice to your sun workstation, and it can reprogram your idprom with just a few keystrokes ☀️
rev B1 now available → https://go.daz.cat/usb3sun



printed more supports for the display. it’s neat that depending on how old your usb3sun is, it would either be in PLA or PETG or ABS, as @ariashark and i gained the ability to print new filaments >:3
After the community feedback Servo TSC would like to share that we have decided to not modify the AI policy and keep it as is.
Future discussions on this topic (if any) will happen on public channels.
More details: https://github.com/servo/servo/discussions/36379#discussioncomment-12898169
they each paint bleak pictures of my industry, but in a way that also motivates me to grow, fight back, and change things.
ed zitron, where’s your ed at
ludic, ludicity
iris meredith, deadSimpleTech
living as if by iris meredith:
Unfortunately, there are those of us who, through a lucky upbringing, hard work in their early adulthood or just being born that way, have developed values that we’re unable to give up. We have that small, very persistent voice in our heads that tells us that if we do certain things we’ll never be able to forgive ourselves. […] I will literally shut down and have a mental breakdown before I do the thing, and I’ve found myself having to resign from jobs before I do something that violates my values. The point is, this isn’t even really a question of morality or choice as we might phrase it: it’s quite simply the fact that there’s something in us that rebels against it with every fibre of our being.
Being this kind of person in our times and our workplaces really bloody sucks. […] So how are those of us who have strong values to live in a situation where we’re likely to be marginal and out in the cold for quite some time?

NIKON D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 2500, 300.0 mm, f/7.1, 1/1000

NIKON D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 4000, 300.0 mm, f/7.1, 1/1000

NIKON D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 1250, 300.0 mm, f/7.1, 1/1000

NIKON D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 450, 270.0 mm, f/7.1, 1/1000

NIKON D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 200, 70.0 mm, f/11.0, 1/160

are you thinking what i’m thinking b1? it’s testing time :)

built a cohost redirect into this site. you can now prepend https://shuppy.org/ to any of my chosts and get the archived version!
for example, https://cohost.org/delan/post/165186-password-protected-e → https://shuppy.org/https://cohost.org/delan/post/165186-password-protected-e
autost was written in a month-long daze after cohost announced their shutdown. it started out as a way for me to archive my own chosts on shuppy.org. since the plan all along was for me to continue chosting from there, that came next. then it gained the ability to import posts from other blogs, archive the chosts of everyone you follow, and archive chosts liked by you and your friends.
buried deep within the core of autost is some gnarly logic that decides which posts should be rendered, which posts should be unlisted or publicly visible (“interesting” posts), and which tags should have their own tag pages (“interesting” tags).
the problems i wanted to solve initially were:
but the way i solved them was a bunch of hardcoded rules:
[self_author] hrefother_self_authorsthere are so many problems with this model:
autost cohost-archive hacks around this by setting the [self_author] href of each archive to a cohost urlautost cohost-archive hacks around this by making a separate site for each project you followwe need to move away from these hardcoded rules. i think it’s time to sit down and actually define what we want autost to be capable of, and design a data model around that. this will require changes to existing sites, but we can build automated migrations or migration tools to upgrade those sites.
when you render your site, we should ask questions like “do we render this post?”, “is this post publicly visible?”, and “which tags have tag pages?”, but let whoever created the post (autost server, autost cohost2autost, autost import, or you) decide the answers.
we’ll probably want to store those answers in a database. it’s all files right now, which is like a database, except harder to extend and harder to safely mix human changes and machine changes. having a database may make it easier to extend autost to do other things with archived chosts, like organise the chosts of everyone you follow into a single browsable archive, or generate a page of your liked chosts.
we may even want to move posts that only exist for rendering replies out of the posts directory and into a separate store, like the attachment store. this will require changes to the <link rel=references> in existing posts though, so it would need to be done with extra care.

NIKON D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 640, 300.0 mm, f/8.0, 1/1000
in darktable, turning the filmic rgb > look > contrast down can help with harshly lit photos. a lot of the improvement seems to come from allowing you to use a much higher latitude %, which would normally go out of bounds if you tried to go that high. compare the following, clockwise from top left:





NIKON D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 100, 300.0 mm, f/6.3, 1/400

NIKON D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 400, 165.0 mm, f/7.1, 1/1000








NIKON D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 400, 300.0 mm, f/7.1, 1/200
ub, ucb, usb, ucsb, uscsb (undefined states of california serial behaviour)
You're probably already aware, but it bears repeating - X1 is a total shitshow. Like, it's bad over there. Even putting aside the ways in which it's just a fundamentally bad design, it's well and truly let itself become a Nazi bar at this point. Disinformation runs rampant, bigotry pervades the entire site's culture - hell, it's owned by the guy in charge of the top-down fascist takeover of the United States' government that's currently happening right now. No wonder anyone with any semblance of principles is hitting da bricks as quickly as possible.
I don't want to deal with that place anymore! So I'm not going to!
I don't really care about what's going on over there anymore, but that doesn't stop me from ending up there somehow, whether it's a friend sharing a link to some artist that's still posting there for some godforsaken reason, or a news page or blog embedding something someone said there in their site. I just don't want to see anything happening there anymore. It's not productive, it doesn't spark joy, I have better things to do with my time. I want it gone from my internet experience.
For the unfamiliar readers, DNS (Domain Name System) is the part of a network that tells your computer where to find the servers for a given domain - the bit between https:// and the first / in a URL (eg. for this website, the domain is srxl.me)2. There's a whole bunch of DNS servers out there - your ISP probably runs one, but there's other publicly usable servers out there, like Quad9 and Cloudflare's. You might even have a DNS server running on your router at home, doing recursive queries - your router probably doesn't have a record of where somerandomwebsite.com lives, but it can ask another server, who can ask another server, who can ask another server, until it eventually gets to someone who does know where it is.
Because of this, it's totally possible to run a DNS server in your own home. The server can give you responses for domains you tell it about, and it can go ask the Internet for all the others. The relevant trick here, is that we can tell the server that we run that it should respond to questions like "where does x.com live?" with "go fuck urself lol". That way, any links to x.com just... don't work! They don't go anywhere so nothing loads! Which is exactly what I want to happen, I want every link to that terrible place to just be broken.
Unfortunately, this is all a lot easier said than done for most. Because I'm one of those people that says words like "VLAN" and "layer 2" and "source NAT" like they mean anything, I use an old Optiplex running OPNsense as my router. That guy already has a DNS server running on it that I can go and configure, which even has a dedicated blocklist option for doing things exactly like this! All I needed to do was log into OPNsense, go to "Services -> Unbound DNS -> Blocklist", and add both x.com and twitter.com (that domain still gets used for some things, lol) to "Wildcard Domains" (not "Blocklist Domains", because I want subdomains, like whatever.x.com to be blocked as well). This makes my DNS server respond to queries for those domains with the IP address 0.0.0.0, which is network speak for "nonsense".
I don't recommend my home network setup for most people. That thing baffles me a lot of the time - I couldn't put in front of a less technical audience in good conscience. It would be really nice if most home routers you get from your ISP or buy from JB Hi-Fi were as configurable as mine, but sadly that's not the case. Companies would rather hide away functionality than put R&D effort into easy to understand interfaces for complex systems, so instead most people have to deal with a worthless hunk of plastic that runs slower than molasses drips off a spoon.
If you want to give it a try, you'll probably want to look for configuring "DNS overrides" in your router. They're all different, so I can't give a simple answer here - consult your search engine of choice for advice. If it turns out that's not a thing your router lets you do (which is quite likely), then you might need to look into setting up a dedicated DNS server. It's not the hardest thing in the world, since there's software like AdGuard Home and Pi-hole that, while being designed with home network enthusiasts in mind, aren't the scariest thing in the world. I might write up a guide on how to set something like that up at some point. They're good for other things too, like blocking all ads across everything on your home network without needing to install adblockers on all your devices.
There's other ways to do it too - if you use uBlock Origin in your browsers (which you really should!), you can add a custom filter like this under the "My filters" tab in uBlock's settings to get it to block X in your browser:
||x.com^
||twitter.com^It won't work everywhere, but it'll at least be something. You can finally be free from that wretched place. It's been a real breath of fresh air, having it be completely gone from my internet experience. At least, it's a lot less musky in here.
Yes, I'm calling it X, not Twitter - Twitter is gone. It doesn't exist anymore. It's X now. The time for facing the music and acknowledging it's devolved far beyond it's pre-Musk days was at least a year ago now, but the second best time is now.
Yeah yeah, it's a lot more complicated than that, I know. Just trying to keep things simple.
as a persistent holdout for calling x “twitter”, it’s time to stop calling it that, and accept it for what it really is. words shape how we see the world, and while that word may have been rejection in 2023, it’s just denial in 2025.
x is a one stop shop for fascists, the worst people in my industry, disinformation, wedging minorities, and a whole lotta psyops.

This article is about the security vulnerability. For the dog breed, see poodle.
casino royale with cheese
I finally got off my ass and did it! After all this time of being like "hmm, yknow, I should start a blog. I should create a nice blogging site for myself" and proceeding to do precisely Nothing to get there, it's finally real! There's a blog! You're reading it! Right now! Yay!
It's taken me quite some time to get to this point. I initially set this domain up to have a website wayyyy back in 2019 - the Internet Archive has a capture of it from 2020 (although it's very broken for some reason). It looked very different back then though, nothing like this site. This iteration of the site starts in 2023, when I made a homepage that looked similar-ish to the current homepage. It had all the same links this one has today in the header, except none of them actually ever went anywhere. The site just kinda... sat there. Dormant. I never really did anything with it. It was forever a somewhat nice-looking homepage (at least on desktop... don't talk to me about the mobile view. shudders) with a handful of links that all said "coming soon". Which like. Yeah. Soon. Sure, mate. When exactly is "soon"?
The blog thing has been getting to me lately. I've been having lots of ideas for blog posts, and I really want somewhere to get them all out. In particular, I have a project planned that I really want to write up on a blog and share with people, because I think a good part of that project will have some really good learning material for not just myself, but other people too. I really wanna get started on it, but my brain is all like "nooooooo you gotta blog about it. you need a blog before you do that. make a blog". Alright, fine brain. Sure. I'll make a blog.
A week or so of hitting the grindstone later, here it is! After throwing out the old site's code due to it being completely unsalvageable (protip: don't ever use Tailwind CSS for anything. That thing is a trap. You put something written using that aside for a year or so, come back to it, and it's just completely incomprehensible. Just write normal CSS. Or Sass. It's fine.), I've come up with a new, improved website that actually has stuff on it! Check out the about me page! That wasn't there before! There's also the blog now, obviously. And it all looks good on mobile too! I actually put some thought into responsive design this time, and now you can actually look at the site on your phone without it dissolving into a incoherent pile of polygons and text. The site, I mean. Not your phone. That would be scary if a site could do that to your phone. Good thing they can only do normal things to your phone, like run Javascript.
Like I said, I've got a few plans for this blog. There's the aformentioned project, which involves NixOS (of course it does, we're talking about a thing I'm making here), Incus, and a handful of machines that won't be running Proxmox for much longer. I've also got a whole bunch of other things, both big and small to write about at some point, so stay tuned for that (RSS helps with that, I've heard)! Aside from the blog, though, there's a few other bits that still need working on. You might have noticed that the "projects" and "gallery" links don't really go anywhere yet. Those are still yet to be picked up. "projects" will go to a little portfolio page of some of the things I've made or worked on (mostly code), which I've still yet to write (or think super hard about what should go there, or what it should look like... bweh. Work). "gallery" will eventually go to a, well, gallery of my photography. I have a lot of photos sitting in my Darktable library, and they're dying to get out somewhere I can share them. That page is probably going to be a while before it becomes reality though. Me and one of my girlfriends are working on memorable, a little self-hosted image gallery for photography collections, and I'd like to use it to power the gallery on my site. Unfortunately, it's nowhere near ready to use at the moment (it doesn't even have a web server, the data models are still WIP), so... yeah. That one will be a little while.
But uhhhhh yeah! That's the new website babey! It's finally here, and I'm really glad I've finally got it done. I've been wanting to have a thing like this for aaaaages now, and it's so nice to finally have it. A website, all of my own, that I can write whatever I want on. Like glorpo. And pleemb. So many things! Aren't blogs wonderful?
Oh, yeah, in case you were one of the very few people who saw me post about an RSS feed on the final days of Cohost and added that to your reader... hi! There's something here now! It took a while, but it's here like I promised!
this month is going to age me a year i swear
avm polony!box
a microplane is what stuart little flies

huh so normally, the canon 55-250 stm only lets you use the focus ring if you’re in mf. if you’re in af, you need to half press the shutter to use the ring.
if you change C.Fn-9 from 0 to 3 on a 1000d, you’ll need to press * to af instead of half shutter, but the focus ring works at all times in af mode!
this makes it easier to af to the subject or something nearby, then use the focus ring. potentially good for birds?
![C.Fn IV: Operation/Others [9]
Shutter/AE lock button
0: AF/AE lock
1: AE lock/AF
2: AF/AF lock, no AE lock
3: AE/AF, no AE lock](/posts/attachments/e9b02d5c-25f3-4d31-999c-639fd2cc1530/PXL_20250321_094610665.jpg)
select distinct with left join
ruby: nah im reworking it
ruby: the old setup is Not Good
ruby: i used t*ilwind
ruby: it’s unsalvageable

Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 100, 70 mm, f/16, 1/80

Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 1600, 70 mm, f/6.3, 1/25

📸: ruby
Fujifilm X-T30 + XF18-55mmF2.8-4 R LM OIS
ISO 800, 55 mm, f/4, 1/20

Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 400, 70 mm, f/8, 1/25

Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 400, 70 mm, f/6.3, 1/40

Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 400, 70 mm, f/6.3, 1/40

📸: ruby
Fujifilm X-T30 + XF18-55mmF2.8-4 R LM OIS
ISO 500, 55 mm, f/4, 1/80

📸: ruby
Fujifilm X-T30 + XF18-55mmF2.8-4 R LM OIS
ISO 640, 55 mm, f/4, 1/80
Dogs are prohibited in
this area of the park.



(a month ago)
this update (full changelog) includes several minor improvements that landed after the big cohost shutdown scramble (rip eggbug). most notably:

autost server now lets you click [+] on any tag to post in itautost server is no longer broken on windows (@ar1a, #39)
so… real talk. a handful of you actually use (or are considering using) autost for more than just archiving your chosts, and i think that’s wonderful. but maybe at this point you’re wondering if the project’s days are numbered.
development has been pretty slow the past couple of months, because i fell in love with a fox, and i needed a break after the last crunch. but i don’t consider autost finished, and i intend to keep working on it, just at a healthier pace.
higher priorities include being able to upload images from the post composer and compose posts from another device. but longer term, i wonder if there’s a niche for autost to be an easier kind of blog engine.
most blogging solutions are either saas, complex self-hosted (wordpress), or require you to be a computer-toucher and have frontend knowledge (static site generators). what if you could just run an app on your computer and get an editor for your blog? what if you could compose posts, follow and reblog your friends, and deploy your blog to neocities or some other host, all without touching the command line?
if that interests you, let me know at autost@shuppy.org or on the league :)
(@ariashark + @bark)
why is your heavy (Hv) weight also medium (Med), but only in one place. do you hate me

Canon EOS 1000D + Canon EF-S 55-250mm f/4-5.6 IS STM
ISO 200, 250 mm, f/5.6, 1/1000

Canon EOS 1000D + Canon EF-S 55-250mm f/4-5.6 IS STM
ISO 200, 250 mm, f/5.6, 1/1600

ISO 200, 250 mm, f/5.6, 1/2000

ISO 200, 250 mm, f/5.6, 1/1600

Canon EOS 1000D + Canon EF-S 55-250mm f/4-5.6 IS STM
ISO 200, 250 mm, f/5.6, 1/1250

Canon EOS 1000D + Canon EF-S 55-250mm f/4-5.6 IS STM
ISO 400, 250 mm, f/6.3, 1/50

Canon EOS 1000D + Canon EF-S 55-250mm f/4-5.6 IS STM
ISO 200, 250 mm, f/5.6, 1/1250
water level gauge in lake gnangara, western australia
750 to 810mm equivalent for under 2^10 grams is fun

Nikon 1 V2 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 800, 280 mm, f/6.3, 1/1600

ISO 1600, 300 mm, f/6.3, 1/640

ISO 1600, 300 mm, f/6.3, 1/800
every youtube sponsored segment i’ve gotten today has been about data broker deletion services. multiple services. what is their deal. what is their business model
play raid shadow legends start now for free switch to didi today ding ding i don’t care i love it ok watch me play this shitty mobile game i gotta get the gun ooh ooh temu ooh ooh temu
every youtube sponsored segment i’ve gotten today has been about data broker deletion services. multiple services. what is their deal. what is their business model

Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 400, 300 mm, f/6.3, 1/500

Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 800, 300 mm, f/6.3, 1/500
Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
edited in darktable and audacity with a workflow like:
$ ffmpeg -i _DSC0774.MOV -an -c:v png 20250221_0_v000/\%05d.png # for darktable
$ ffmpeg -i _DSC0774.MOV -vn -c:a copy 20250221_0_v000/audio.wav # for audacity
$ ffmpeg -i 20250221_0_v000/audio-audacity-hpf-240Hz-48dB.wav -pattern_type glob -i '20250221_0_v000/darktable_exported/*.png' -c:a aac -b:a 192k -c:v libx264 -preset veryslow -crf 16 -pix_fmt yuv420p 20250221_0_v000/20250221_0_v000_crf16.mp4
PROBLEM: i want to edit this video to fix the exposure and colour, like i do for my still photos
👼: learn how to use a video editor
😈: convert to png, batch edit the frames in darktable, convert to h264
is like family jewels but instead of jewels it’s just some qwords you can run cmpxchg8b on when you die
shark: “family atomics” is just what you get when you run “nuclear family” through google translate a dozen times
is like family jewels but instead of jewels it’s just some qwords you can run cmpxchg8b on when you die

Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 400, 300 mm, f/6.3, 1/2000

ISO 200, 300 mm, f/6.3, 1/800

ISO 800, 300 mm, f/6.3, 1/1600

ISO 800, 300 mm, f/6.3, 1/1000

Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 400, 300 mm, f/6.3, 1/640

ISO 400, 200 mm, f/6.3, 1/800

Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 400, 300 mm, f/6.3, 1/2000

calm, comfy, cosy (bell miner)

Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 400, 200 mm, f/6.3, 1/160

ISO 800, 170 mm, f/6.3, 1/500

Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 200, 200 mm, f/6.3, 1/250

ISO 200, 200 mm, f/6.3, 1/200

Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 800, 300 mm, f/6.3, 1/320

Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 200, 200 mm, f/6.3, 1/100

Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 400, 300 mm, f/6.3, 1/1600

Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 800, 300 mm, f/6.3, 1/250
ooo atkinson hyperlegible now has variable weight, variable italic, and mono versions
https://www.brailleinstitute.org/freefont/



Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 800, 300 mm, f/6.3, 1/800

Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 100, 140 mm, f/32, 1/13

ISO 100, 70 mm, f/32, 1/10

Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 400, 300 mm, f/6.3, 1/500

ISO 400, 300 mm, f/6.3, 1/400

Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 400, 260 mm, f/6.3, 1/640

ISO 400, 220 mm, f/6.3, 1/640

ISO 400, 300 mm, f/6.3, 1/160

Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 400, 300 mm, f/5.6, 1/400
this one was pretty much unusable, but they got mobbed by three common mynas just seconds later, and i have no idea when i’ll get to see one again ;-;

Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 400, 300 mm, f/6.3, 1/800

ISO 400, 270 mm, f/6.3, 1/200

Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 400, 300 mm, f/6.3, 1/1000

Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 200, 300 mm, f/6.3, 1/800

Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 800, 250 mm, f/6.3, 1/250

Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 800, 300 mm, f/6.3, 1/4000

Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 1600, 180 mm, f/6.3, 1/1250

Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 1600, 70 mm, f/10, 1/1250


Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 400, 300 mm, f/8, 1/1250


ISO 400, 300 mm, f/8, 1/1600

Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 200, 300 mm, f/8, 1/640

ISO 200, 300 mm, f/8, 1/800

Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 800, 195 mm, f/6.3, 1/500

Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 800, 300 mm, f/7.1, 1/640


Nikon D3200 + AF-S VR Zoom-Nikkor 70-300mm f/4.5-5.6G IF-ED
ISO 400, 155 mm, f/6.3, 1/2500
not to be confused with monkey mia



Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 800, 300 mm, f/5.6, 1/200

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 200, 300 mm, f/6.3, 1/200

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 200, 300 mm, f/6.3, 1/400

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 1600, 300 mm, f/6.3, 1/2500


Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 800, 300 mm, f/8, 1/250

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 800, 300 mm, f/8, 1/2000

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 1600, 300 mm, f/5.6, 1/640


Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 400, 210 mm, f/6.3, 1/640
![figure “Types of using format”[?], column “Cropped circle”, row “3:2”, link “78% FOV, 92% sensor” with tooltip text “File:3-2-circumcised.png”](/posts/attachments/302c8c09-07fa-4b99-a417-ad99233cc10f/9d20bca6fc98b7d44e51a87592418063fee112385fbba0553d694eb6df050bcb.png)

shuppy: what do normal people do
ruby: normal people don’t call out to shell scripts from a rust binary, but that ship has already sailed
only a couple days left until cohost goes down! why not archive the chosts you care about, so you can look back on them without relying on wayback machine?
cohost-dl will do your chosts plus your liked chosts, while autost will do both of those plus chosts by people you follow! here’s how you can use autost for that:
log in to cohost, press F12, then grab your “connect.sid” cookie (see screenshot or consult someone with stickers on their laptop)
if you own more than one page, switch to the one you want to archive
repeat from step 3 until you’ve archived all of your pages
please email me on autost@shuppy.org if you have any questions! good luck ^w^
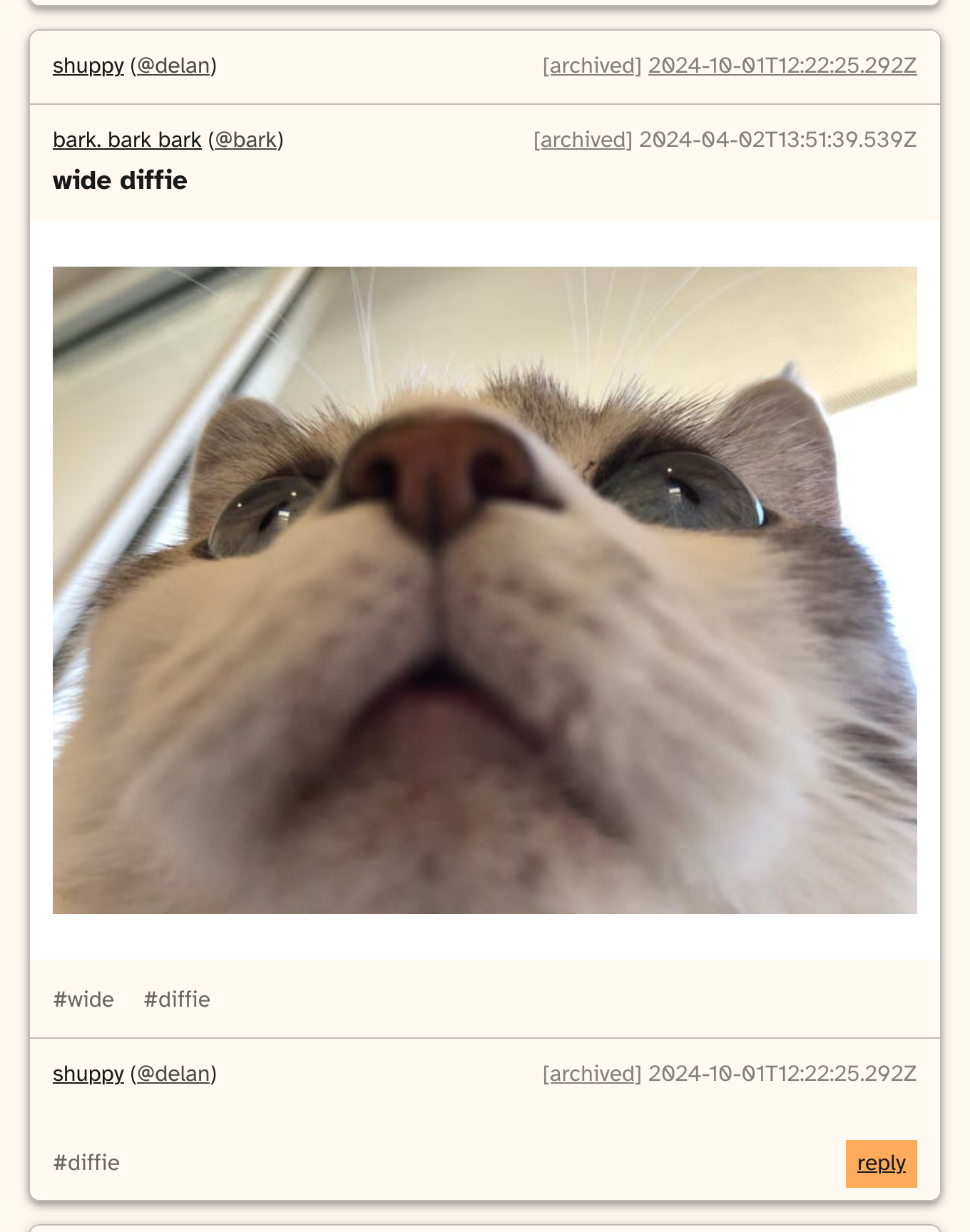
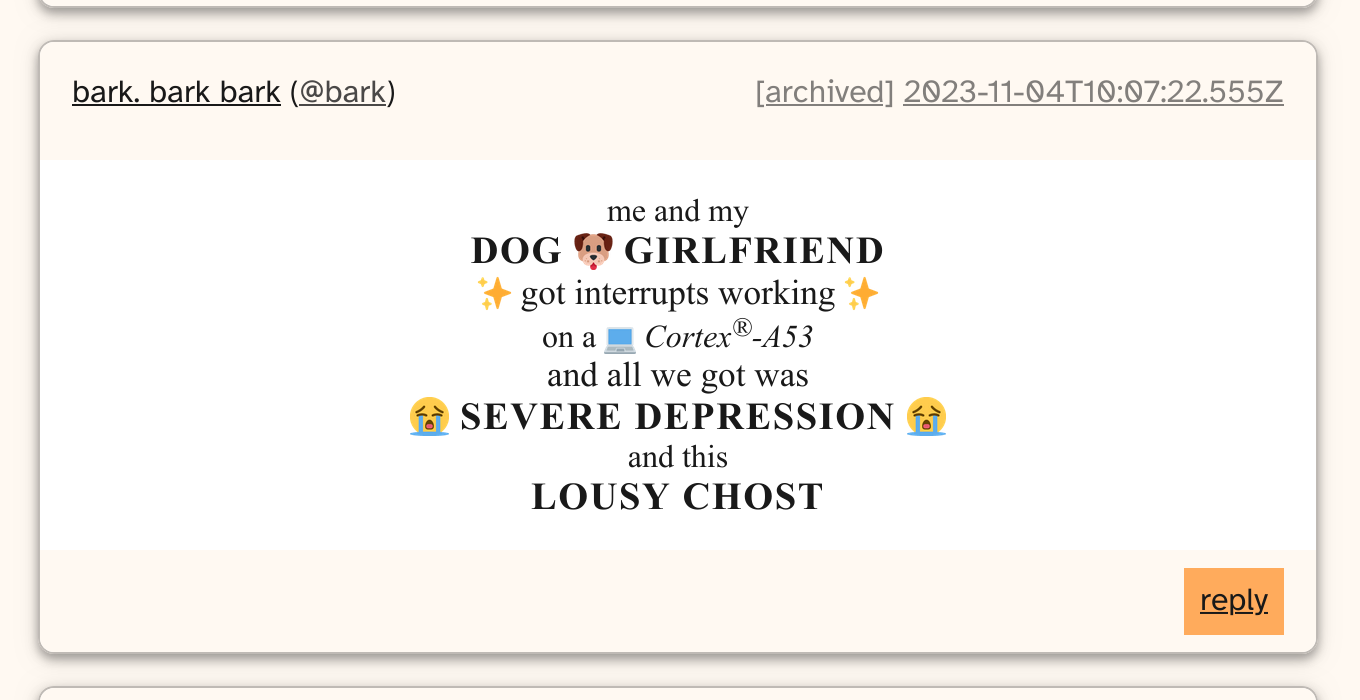
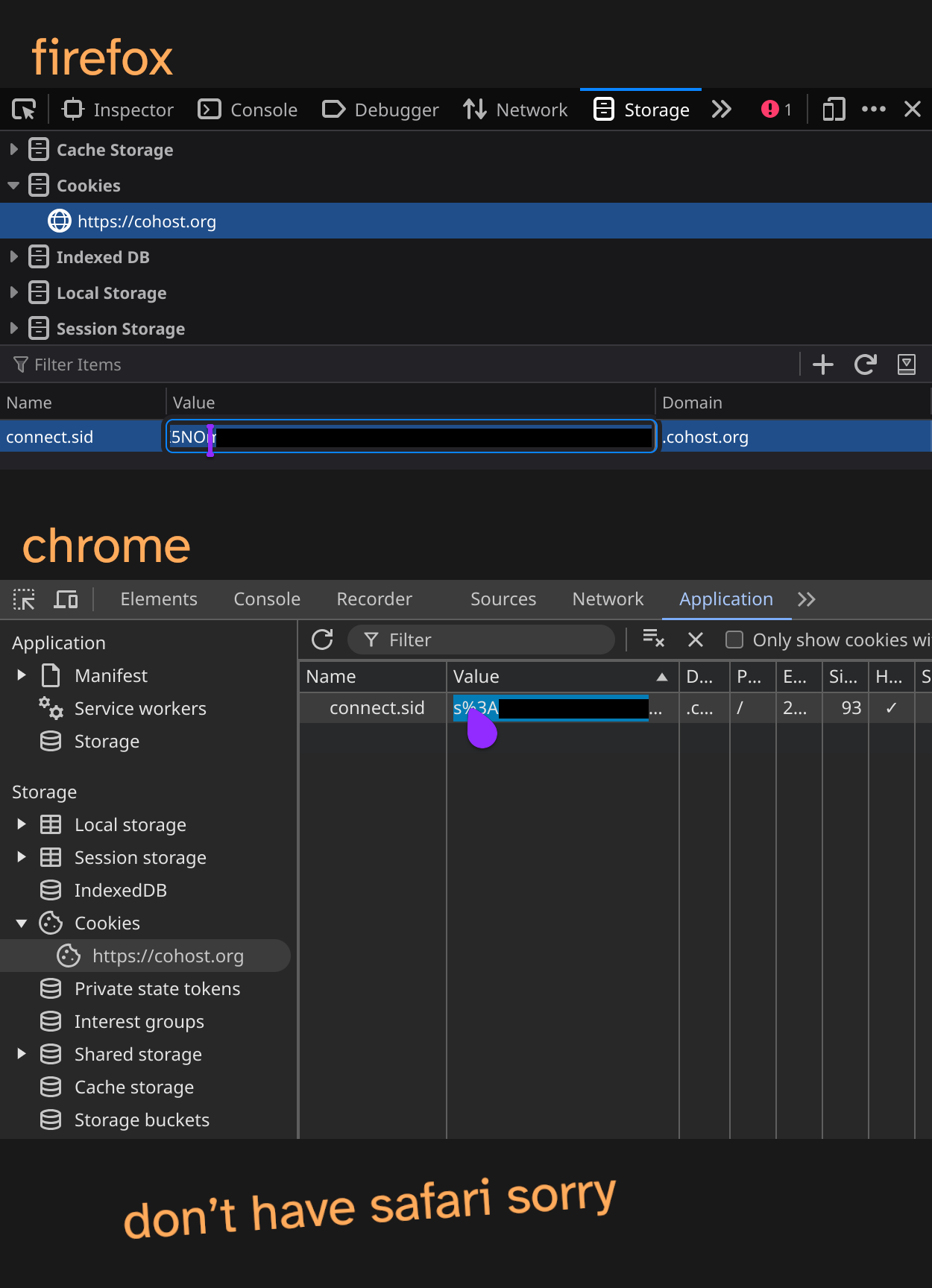
there was another bug in --liked mode, causing your oldest (up to) 20 liked chosts to be lost. more details: https://github.com/delan/autost/releases/tag/1.3.2
only archives of your own cohost projects are affected, not other people’s projects, and you can fix your existing archives by updating to autost 1.3.2, deleting a couple files, and rerunning autost cohost-archive.
anyway let me know if you run into any problems, but also if autost worked for you! and follow me here or there or watch the github repo for updates :)
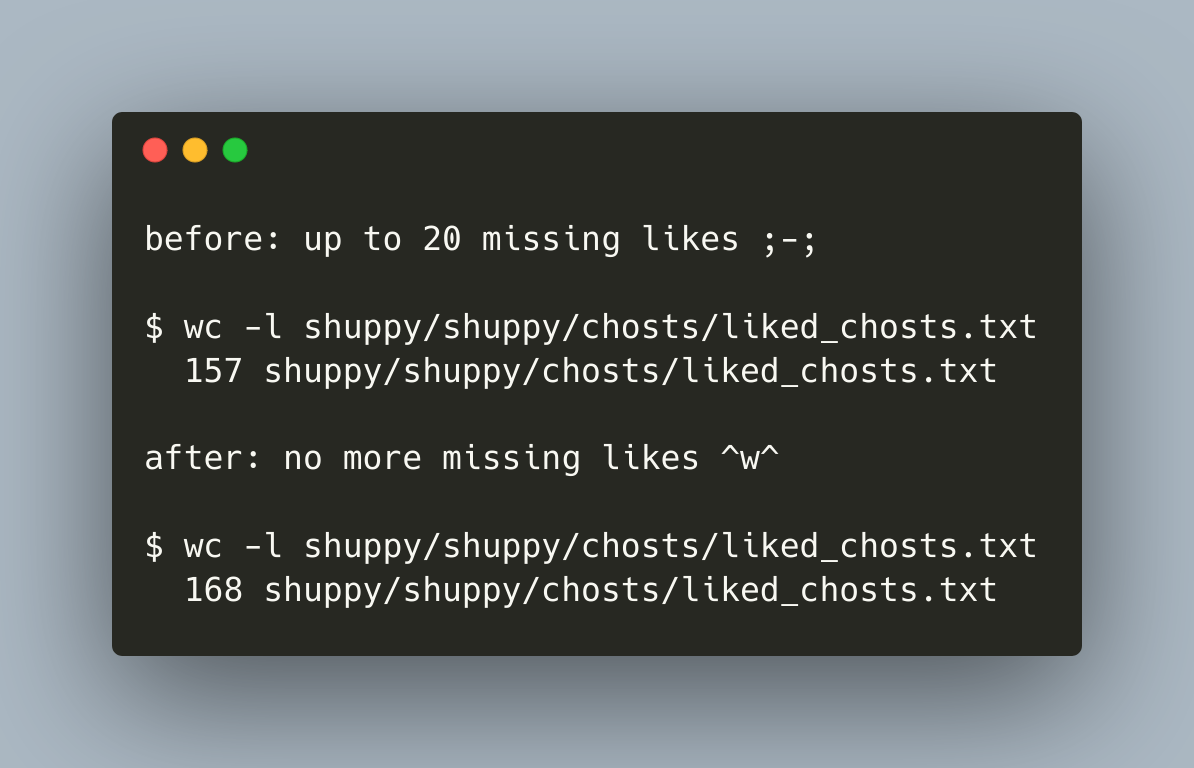
only a couple days left until cohost goes down! why not archive the chosts you care about, so you can look back on them without relying on wayback machine?
cohost-dl will do your chosts plus your liked chosts, while autost will do both of those plus chosts by people you follow! here’s how you can use autost for that:
log in to cohost, press F12, then grab your “connect.sid” cookie (see screenshot or consult someone with stickers on their laptop)
if you own more than one page, switch to the one you want to archive
repeat from step 3 until you’ve archived all of your pages
please email me on autost@shuppy.org if you have any questions! good luck ^w^
update: fixed a bug that makes some chosts archive incorrectly in --liked mode, and fixed a crash on windows (thanks @ysaie@isincredibly.gay!)
only archives of your own cohost projects are affected, not other people’s projects, but you’ll need to rerun autost cohost-archive for the affected projects to fix your archives :(
more details: https://github.com/delan/autost/releases/tag/1.3.1
only a couple days left until cohost goes down! why not archive the chosts you care about, so you can look back on them without relying on wayback machine?
cohost-dl will do your chosts plus your liked chosts, while autost will do both of those plus chosts by people you follow! here’s how you can use autost for that:
log in to cohost, press F12, then grab your “connect.sid” cookie (see screenshot or consult someone with stickers on their laptop)
if you own more than one page, switch to the one you want to archive
repeat from step 3 until you’ve archived all of your pages
please email me on autost@shuppy.org if you have any questions! good luck ^w^

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 1600, 300 mm, f/5.6, 1/640
Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 400, 210 mm, f/6.3, 1/2000




Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 800, 200 mm, f/7.1, 1/800








Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 100, 210 mm, f/7.1, 1/2000

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 100, 210 mm, f/7.1, 1/2000

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 1600, 200 mm, f/8, 1/800

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 400, 200 mm, f/8, 1/800

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 200, 140 mm, f/7.1, 1/2000

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 200, 135 mm, f/7.1, 1/2000

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 100, 210 mm, f/7.1, 1/2000

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 400, 195 mm, f/8, 1/800

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 200, 135 mm, f/7.1, 1/2000

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 1600, 200 mm, f/7.1, 1/800

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 1600, 200 mm, f/8, 1/800

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 1600, 270 mm, f/9, 1/1000

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 1600, 200 mm, f/9, 1/1000

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 1600, 195 mm, f/6.3, 1/640

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 1600, 195 mm, f/6.3, 1/640

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 1600, 300 mm, f/6.3, 1/640

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 200, 300 mm, f/7.1, 1/1000

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 400, 240 mm, f/6.3, 1/1000
fellas is it gay to go to bed, put on the playlist i made with her and crywank bc she’s been 2000 km away for weeks and still not coming back this weekend and i gotta “enjoy” my whole fucking weekend and go back to work for a further two fucking days before i can see her or have coffee with her or watch birds with her or crochet with her or breed her
i think i might be gay. for girls. especially this one
fellas is it gay to go to bed, put on the playlist i made with her and crywank bc she’s been 2000 km away for weeks and still not coming back this weekend and i gotta “enjoy” my whole fucking weekend and go back to work for a further two fucking days before i can see her or have coffee with her or watch birds with her or crochet with her or breed her
ruby saw our macaroni cheese recipe and suggested we add toasted panko breadcrumbs, smoked paprika, and fried carrot and spinach leaves in the pot towards the end. we tried the first two this time, and i think it went pretty well!






(with shark + luca)
i gave it a go today with all of my proposed additions and yeah. this slaps. only problem is that i misread the steps with adding the cornflour - i added it to the pot of milk and went “well what do i do with the reserved milk then?” and just dumped that milk in after, which was probably suboptimal. sauce came out a little grainy. also i scaled the recipe down a little too much and probably didn’t have enough sauce too.
BUT! it is very good. and my additions are also very good.


(with @problemsclown)
ruby saw our macaroni cheese recipe and suggested we add toasted panko breadcrumbs, smoked paprika, and fried carrot and spinach leaves in the pot towards the end. we tried the first two this time, and i think it went pretty well!
(with shark + luca)
i also decided to try toasted panko breadcrumbs with our carbonara recipe, and i quite liked the texture contrast here too.
despite what the photos imply, the breadcrumbs don’t go in the wok with the pancetta. they go on the plate as garnish.




(with shark + luca)
(with @problemsclown)
ruby saw our macaroni cheese recipe and suggested we add toasted panko breadcrumbs, smoked paprika, and fried carrot and spinach leaves in the pot towards the end. we tried the first two this time, and i think it went pretty well!
(with shark + luca)
in current gay parlance, dan presents somewhere between a “wolf” and an “otter”, some would call a “frost otter”. a “frotter”, if you will
so i was excited to have finally fixed printing on my desktop, which was broken for like a year. it even printed a test page!
unfortunately it also printed a test page on the back

an aaaa game is 1/6 of a 9V battery game
an aaaa game is when your single-a game adopts ipv6
an aaaa game is 1/6 of a 9V battery game

getting my hickeys continuously replenished, like a perpetual stew, so they never fade
[thanks to] the psychopaths in treasury and the adam smith institute, the whole british economy — and it’s only more true today — is built around the idea that value comes from the interfaces between the things that do stuff, not from the things that do stuff.

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 800, 300 mm, f/8, 1/400

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 400, 300 mm, f/9, 1/640
Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 400, 300 mm, f/9, 1/640

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 800, 300 mm, f/8, 1/500

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 800, 300 mm, f/6.3, 1/640

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 200, 300 mm, f/8, 1/800

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 400, 300 mm, f/8, 1/640

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 800, 300 mm, f/6.3, 1/400

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 800, 300 mm, f/8, 1/400

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 400, 300 mm, f/8, 1/500

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 400, 300 mm, f/7.1, 1/250

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 400, 300 mm, f/6.3, 1/500

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 800, 300 mm, f/6.3, 1/640

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 800, 300 mm, f/6.3, 1/250

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 800, 300 mm, f/6.3, 1/250

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 800, 300 mm, f/8, 1/400

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 800, 300 mm, f/6.3, 1/250

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 800, 300 mm, f/6.3, 1/250

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 800, 300 mm, f/8, 1/400

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 200, 155 mm, f/8, 1/640

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 400, 300 mm, f/8, 1/800

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 400, 300 mm, f/8, 1/500

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 200, 300 mm, f/8, 1/400

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 400, 135 mm, f/8, 1/500

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 200, 155 mm, f/7.1, 1/500

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 200, 200 mm, f/8, 1/400

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 200, 102 mm, f/8, 1/320

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 400, 105 mm, f/8, 1/1250

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 400, 102 mm, f/8, 1/800

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 200, 300 mm, f/8, 1/500

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 200, 68 mm, f/8, 1/320

apologies for the scuffed photo. too busy gazing at each other in the reflection :3
(see also: https://posting.isincredibly.gay/notice/AnKgX4mwP9vD8PPKk4)

note: currently hard linking saves 1115.40 MiB
35499 store paths deleted, 89914.82 MiB freed
note: currently hard linking saves 18960.09 MiB
73216 store paths deleted, 110851.34 MiB freed
15220.36 MiB freed by hard-linking 908964 files

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 1600, 300 mm, f/5.6, 1/640

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 400, 220 mm, f/7.1, 1/1000

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 800, 300 mm, f/5.6, 1/400

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 800, 300 mm, f/5.6, 1/500

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 200, 300 mm, f/6.3, 1/640

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 1600, 300 mm, f/6.3, 1/320

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 100, 300 mm, f/8, 1/200

ISO 400, 300 mm, f/7.1, 1/800

Although C is not really the "portable assembly language" many want it to be, one function definition in C generally leads to one symbol in an object file, and having access to function bodies after they've been compiled once is unnecessary (although helpful for optimization), and it would be good to retain these properties. A less-trodden path for implementing parametric polymorphism in systems-ish languages, used by Swift and also proposed here in N3212, is to use runtime metadata to handle generic types dynamically. N3212 proposes a new _Type primitive type, which carries some metadata about a type's size and other properties, so that other values can be declared with the type represented by that _Type using the _Var specifier:
void sort(_Type T, size_t N, _Var(T) array[N],
int (*compare)(const _Var(T)*, const _Var(T)*))
{
qsort(array, N, sizeof(_Var(T)), compare);
}
One challenge specifying a language-integrated metadata system is that it needs to provide enough information to serve any possible use that the language supports, even if a particular interface only needs a subset of that metadata. A traditional qsort function only needs the size of the elements to do its work, but other generic functions might want to know a type's alignment, its name, how values of the type interact with the function calling convention, the specifier to use in printf, and so on. The vast body of existing C code uses all sorts of different idioms for ad-hoc polymorphic interfaces, so a language design that prescribes a single metadata mechanism is going to have a tough time finding a balance between providing enough metadata to support a wide range of use cases and not bloating code generation with too much metadata that most clients don't need.
So that's why I'd like to explore a third approach that has the potential to be simpler to understand and implement, more flexible, and I think more in the subjective "spirit of C" than C++ style monomorphization or the proposed N3212 design. I think the combination of type-erased generics, paired with a default argument mechanism to collect situationally-appropriate metadata at call sites, could provide a surprising amount of expressivity, allow for better type checking to be retrofitted to existing C interfaces.
You might also ask, why spend so much time thinking about big new features for C? Isn't C illegal now anyway? Well, I also think it'd be generally good to see more systems languages that don't fall into the well-worn monomorphization rut. Maybe these thoughts will inspire an ambitious systems language designer to try something different.
// T can appear as the pointee of a pointer, be cv-qualified, … void good_generic«T»(const T *a, T *b); // …but can't appear as a parameter type by itself void bad_generic«T»(T a); // error; incomplete generic type TIt may not seem like you'd be able to do much in a generic function in this world, since you can't directly do anything with the value of an incomplete type. However, by passing function pointers with matching pointer argument types down along with a pointer, you can make useful generic functions:
// Traverse a list, given operations to visit each node in the list
// and to advance to the next node
void each_node«Node»(Node *head,
Node *(*next)(Node *),
void (*body)(Node *)) {
for (Node *node = head; node; node = next(node)) {
body(node);
}
}
struct int_node {
struct int_node *next;
int value;
};
struct int_node *next_int_node(struct int_node *node) {
return node->next;
}
void print_int_node(struct int_node *node) {
printf("%d\n", node->value);
}
int main() {
struct int_node list[] = {
{ .next = &list[1], .value = 1 },
{ .next = &list[2], .value = 2 },
{ .next = &list[3], .value = 3 },
{ .next = &list[4], .value = 5 },
{ .next = NULL, .value = 8 },
};
each_node«struct int_node»(&list[0], next_int_node, print_int_node);
}
This is akin to passing a vtable for a generic interface (or a "witness table" as Swift calls them), but entirely under the program's control to indicate what's in that vtable.
// Reduce the values in an array
void reduce«T»(T *out, const T *array, size_t count,
void (*sum)(T *out, const T *element),
size_t element_size = sizeof(T)) {
unsigned i;
const T *element;
for (i = 0, element = array;
i < count;
++i, element = (const T*)((const char *)T + element_size)) {
sum(out, element);
}
}
void sum_int(int *out, const int *value) {
out += value;
}
int main() {
int values[] = {0, 1, 1, 2, 3, 5, 8, 13};
int sum = 0;
// call site implicitly passes element_size = sizeof(int)
reduce«int»(&sum, values, sizeof(values)/sizeof(int), sum_int);
printf("%d\n", sum);
}
(Having to manually advance the element pointer in the reduce loop by casting to char* and back is kinda gross, so maybe there should be a way to associate a size expression with a generic type, just so pointer arithmetic works:)
// Declaring a generic parameter as T[size_expr] expresses that
// sizeof(T) == size_expr
void reduce«T[element_size]»(T *out, const T *array, size_t count,
void (*sum)(T *out, const T *element),
size_t element_size = sizeof(T)) {
unsigned i;
const T *element;
for (i = 0, element = array;
i < count;
// We can use normal pointer arithmetic on a T* if T has a
// size expression
++i, ++element) {
sum(out, element);
}
}
void qsort(void *base, size_t nel, size_t width,
int (*compar)(const void *, const void *));
where base is a pointer to the first element in an array, nel is the number of elements in the array, width is the size of an element, and compar is a three-way comparison function that returns whether the first pointed-to element is considered less than, equal, or greater than the second. We could change this to:
void qsort«T[width]»(T *base, size_t nel, size_t width = sizeof(T),
int (*compar)(const T *, const T *));
Since the generic type declaration itself has no runtime effect, it doesn't need to have any effect on the calling convention of qsort. And we're still passing pointers in all the same places we were passing pointers before. However, one concession to tradition is that the width parameter ought to default to sizeof(T), but it's not the final argument to qsort, so if we follow C++'s default argument rules, this wouldn't be allowed. But we could loosen that restriction, and allow any argument to be defaulted at a generic call site:
int compare_ints(const int *a, const int *b) {
return a - b;
}
int main() {
int array[] = {0, 1, 1, 13, 2, 21, 3, 34, 5, 8};
qsort«int»(array, sizeof(array)/sizeof(int), /*default*/,
compare_ints);
}
To allow existing C code to continue to call qsort after its retroactive genericization, we could say that calling a generic function without generic arguments devolves those arguments back to void. Default arguments that depend on the generic parameters aren't available at a nongeneric call site, and the caller has to be supply an argument manually. Backward compatibility aside, this would also be useful as a way to get back into generic code using runtime metadata that's been stored in a way that can't be statically reasoned about. (Of course, this is also an easy way to escape type safety, though C is full of those already… maybe there should be a more opt-in way to do so?)
struct hashable«Key» {
size_t size = sizeof(Key), alignment = alignof(Key);
uint64_t hash(const Key *value);
bool equal(const Key *a, const Key *b);
};
const struct hashable«int» int_hashable = {
.hash = int_hash,
.equal = int_equal,
};
Incomplete types can also usefully carry generic parameters, to provide some type safety at an interface boundary:
struct hash_table«Key, Value»;
struct hash_table«Key, Value» *hash_table_alloc«Key, Value»( size_t initial_buckets, const struct hashable«Key» *key_type, size_t value_size = sizeof(Value), size_t value_alignment = alignof(Value));
void hash_table_insert«Key, Value»( struct hash_table«Key, Value» *hash, const Key *key, const Value *value);
const Value *hash_table_find«Key, Value»( struct hash_table«Key, Value» *hash, const Key *key);
enum json_tag«T» {
null«struct null»,
boolean«bool»,
number«double»,
string«const char *»,
array«struct json_array»,
object«struct json_object»,
};
struct json«T» {
enum json_tag«T» tag;
union {
struct null null«struct null»;
bool boolean«bool»;
double number«double»;
const char *string«const char *»;
struct json_array array«struct json_array»;
struct json_object object«struct json_object»;
};
};
struct json«double» zero = { .tag = number, .number = 0.0 };
struct json«const char *» greeting = {
.tag = string,
.string = "hello world"
};
struct json«double» bad_number = {
// error, enum constant 'null' has type 'json_tag«struct null»', not
// 'json_tag«double»'
.tag = null,
// error, union field 'string' has type '(anonymous union)«const char *»'
.string = "0.0"
};
struct hash_table«Key, Value» *hash_table_alloc«Key, Value»( size_t initial_buckets, const struct hashable«Key» *key_type, size_t value_size = sizeof(Value), size_t value_alignment = alignof(Value));The Value's size and alignment can be prepopulated using sizeof and alignof, but there isn't a good way to default the key_type parameter to a canonical hashable struct for a given type (aside from maybe using _Generic for a closed set of types). C++-style template specialization is probably not a great idea, since it makes type checking dependent on template instantiation, but one possible design might be to allow a global variable name to be declared as being parametric:
// Declare a compound name _Generic const struct hashable«T» hashable_impl«T»;This wouldn't define any actual global variable itself, but would allow for definitions to be provided for specific types:
// Provide definitions for some common types:
const struct hashable«int» hashable_impl«int» = { ... };
const struct hashable«bool» hashable_impl«bool» = { ... };
const struct hashable«void *» hashable_impl«void *» = { ... };
Other than the common name, each individual global variable definition would behave like an independent variable definition. Trying to access a parametric name for which no definition is visible would be an error:
auto *hashable_char = &hashable_impl«char»; // error, no such definition
const struct hashable«char» hashable_impl«char» = { ... };
auto *hashable_char = &hashable_impl«char»; // OK
but this would give us the open association we need to provide a nice default for our hash table API:
struct hash_table«Key, Value» *hash_table_alloc«Key, Value»( size_t initial_buckets, const struct hashable«Key» *key_type = &hashable_impl«Key», size_t value_size = sizeof(Value), size_t value_alignment = alignof(Value));However, we're still type-erasing everything, so there's no dynamic lookup structure to recover this association at runtime. That would mean that you would not be able to refer to a parametric global generically, which might be weird:
const struct hashable«T» *get_hashable_impl«T»(void) {
// error, can't look up hashable_impl for a generic type T
return &hashable_impl«T»;
}
(highlighted = the last set i’ve gone through properly)
autost is a cohost-compatible archive and blog engine, which i use right here on shuppy.org. for another autost blog, check out LotteMakesStuff dot PINK :D
your posts are now rebloggable, thanks to the microformats2 h-entry format! for the most consistent experience, be sure to set your [self_author] display_handle setting to a domain name.
you can now reblog posts with autost import. for example, to reblog Natalie’s post Reblogging posts with h-entry:
$ autost import https://nex-3.com/blog/reblogging-posts-with-h-entry/
2024-10-03T15:30:33.221087Z INFO run_migrations: autost::migrations: hard linking attachments out of site/attachments
2024-10-03T15:30:33.411823Z INFO autost::command::import: writing RelativePath { inner: "posts/imported/1.html", kind: Other }
2024-10-03T15:30:33.422458Z INFO autost::command::import: click here to reply: http://[::1]:8420/posts/compose?reply_to=imported/1.html
you can now create attachments from local files with autost attach. for example:
$ autost attach ~/Downloads/atom{1,2}.png
2024-10-11T11:47:39.031943Z INFO run_migrations: autost::migrations: hard linking attachments out of site/attachments
2024-10-11T11:47:39.137328Z INFO autost::command::attach: created attachment: <attachments/d9c42006-07ca-4027-8abb-dfa670a7e637/atom1.png>
2024-10-11T11:47:39.137477Z INFO autost::command::attach: created attachment: <attachments/887df41f-a1ce-4e66-8a9f-09ef1f6fedca/atom2.png>
warning: autost attach does not strip any exif data yet, so be careful not to leak your gps location in any photos you upload! use exiftool or a photo editor to check.
the atom output is also way better now! most importantly, threads with multiple posts are no longer an unreadable mess:
note that your subscribers will need to convince their clients to redownload your posts, or unsubscribe and resubscribe, to see these effects on existing posts.
subscribe here for updates, or email me on autost@shuppy.org if you have any questions. enjoy :3
autost is a cohost-compatible archive and blog engine, which i use right here on shuppy.org. for another autost blog, check out LotteMakesStuff dot PINK :D
your posts are now rebloggable, thanks to the microformats2 h-entry format! for the most consistent experience, be sure to set your [self_author] display_handle setting to a domain name.
you can now reblog posts with autost import. for example, to reblog Natalie’s post Reblogging posts with h-entry:
$ autost import https://nex-3.com/blog/reblogging-posts-with-h-entry/
2024-10-03T15:30:33.221087Z INFO run_migrations: autost::migrations: hard linking attachments out of site/attachments
2024-10-03T15:30:33.411823Z INFO autost::command::import: writing RelativePath { inner: "posts/imported/1.html", kind: Other }
2024-10-03T15:30:33.422458Z INFO autost::command::import: click here to reply: http://[::1]:8420/posts/compose?reply_to=imported/1.html
you can now create attachments from local files with autost attach. for example:
$ autost attach ~/Downloads/atom{1,2}.png
2024-10-11T11:47:39.031943Z INFO run_migrations: autost::migrations: hard linking attachments out of site/attachments
2024-10-11T11:47:39.137328Z INFO autost::command::attach: created attachment: <attachments/d9c42006-07ca-4027-8abb-dfa670a7e637/atom1.png>
2024-10-11T11:47:39.137477Z INFO autost::command::attach: created attachment: <attachments/887df41f-a1ce-4e66-8a9f-09ef1f6fedca/atom2.png>
warning: autost attach does not strip any exif data yet, so be careful not to leak your gps location in any photos you upload! use exiftool or a photo editor to check.
the atom output is also way better now! most importantly, threads with multiple posts are no longer an unreadable mess:
note that your subscribers will need to convince their clients to redownload your posts, or unsubscribe and resubscribe, to see these effects on existing posts.
subscribe here for updates, or email me on autost@shuppy.org if you have any questions. enjoy :3
most of the first thirty or so orders have had hand-drawn box art, but now that we’re shipping them more often, i think it’s time to make things a bit more efficient.
at first i drew the new box art on paper, scanned it, then tried tracing it in inkscape, but i spent way too much time cleaning up the paths and it never quite looked right. so i drew this with my tablet in krita instead.



this lemon chicken recipe has a pretty big advantage over our usual recipe (previously, previously): the rice is done in the oven with the chicken, steeped in juices and fond and stock and spare marinade. it’s wonderful.
just be careful to sauté the onions slowly, or you’ll have to fish out a couple dozen blackened pieces like i did.






Natalie wrote:
Once I add the ability to embed arbitrary blog posts from other blogs on here it's over. I'm gonna be reblogging like a wild animal. Y'all are gonna have your eyes blown clean outta your heads.
Thrilled to announce that I now have this up and running, at least in its most basic aspect. The embed above is automatically generated and pulled down directly from the source post. Nothing in this is specific to my blog; I can also do it with someone else's. By way of example, please enjoy this post from my beautiful wife:
Liz wrote:
there is a very specific feeling of relief upon realizing I don’t need to hurry to finish a library book before it’s due, because I definitely will want to buy a copy for future reference and cross-checking.
(the book in question is Gossip Men: J. Edgar Hoover, Joe McCarthy, Roy Cohn, and the Politics of Insinuation by Christopher M. Elias)
Here's what the embed looks like in my blog source right now:
{% genericPost "https://nex-3.com/blog/once-i-add-the/",
time: "2024-09-20T07:06:00Z",
tags: "#meta",
author: "Natalie",
authorUrl: "/",
authorAvatar: "/assets/avatar.webp" %}
<p>
Once I add the ability to embed arbitrary blog posts from other blogs on
here it's over. I'm gonna be reblogging like a wild animal. Y'all are gonna
have your eyes blown clean outta your heads.
</p>
{% endgenericPost %}
I have a template for the embed, some CSS to style it, and a little
custom Liquid tag to bring it all together. But the real magic is in
how I generate the genericPost in the first place.
Here's what the original source looks like before I run my
embed injector
on it:
https://nex-3.com/blog/once-i-add-the/
That's it! Just a URL surrounded by empty lines. The injector pulls
down the webpage, extracts critical information about the blog post,
and replaces the URL with a call to genericPost. My
Letterboxd and Cohost embeds work the same way, with their own
custom templates and metadata that let me match the style of the
original websites.
But I did say that this wasn't specific to my blog. With Letterboxd and Cohost, I've just hard-coded their HTML structure. I can't rely on that if I want to get information from any old blog, though. They all use different HTML structures!
So instead, I'm making use of the h-entry microformat. This is a tiny little specification that defines a way to mark up an existing post to indicate metadata in the existing HTML structure. At its simplest, it's just a few class names annotated with the HTML. Here's the simplified HTML for the post above:
<article class="h-entry">
<p class="attribution">
<a href="/blog/once-i-add-the/" rel="canonical" class="u-url">
Posted
<time datetime="2024-09-20T07:06:00Z" class="dt-published">
20 September 2024
</time>
by
<span class="p-author h-card">
<span class="p-name">Natalie</span>
<data class="u-url" value="/"></data>
<data class="p-logo" value="/assets/avatar.webp"></data>
</span>
</a>
</p>
<div class="e-content">
<p>
Once I add the ability to embed arbitrary blog posts from other
blogs on here it's over. I'm gonna be reblogging like a wild animal.
Y'all are gonna have your eyes blown clean outta your heads.
</p>
</div>
<ol class="tags"><li><a href="/tag/meta" class="p-category">meta</a></li></ol>
</article>Here are the special class names I'm using:
h-entry wraps the entire thing, indicating that it's
a post.
u-url goes on a link and indicates the post's
canonical URL.
dt-published goes on a
<time> element
and indicates when the post was made.
p-author can just be the author's name, but I've made
it into a whole
h-card with the
following metadata:
p-name is my name.u-url is my personal URL, which is to say this
website.
p-logo is the URL of my avatar, so people
reblogging me have something to show by my posts.
p-name isn't used here because this post is untitled,
but if it had a title that would be the class for it.
e-content is the HTML content of the post itself.
p-category is the name of a tag associated with the
post.
Of these, only h-entry, u-url, and
e-content are really critical. There are a
handful of other features defined in the spec, including a way to
indicate which post you're replying to, that you should check out if
you're interested. But these are the most critical.
You should do this too! If you can edit your blog's post layout,
it's extremely easy. Just add those classes to the appropriate
places, and you're off to go. If you don't already have an HTML
element for some piece of information, you can add invisible
<data> tags like I did above to provide the info
to consumers without changing the way your post looks to readers.
Even if your blog doesn't allow you to edit the layout, if you can
add HTML to the posts you can do this by hand. There's no need to
use the specific <article> or
<p> tags I do above... just divs will work. You
can even make your rebloggable content different than the original,
which I'm planning to do to avoid having my embeds look too weird if
they get reblogged.
If you end up adding h-entry support, or even better if you end up making use of mine, drop me a comment and let me know!
i’ve started adding h-entry support to autost! still need to rewrite relative urls and cache embedded images, but i can already import and share/reply to posts:
$ autost import https://nex-3.com/blog/reblogging-posts-with-h-entry/
2024-10-03T15:30:33.221087Z INFO run_migrations: autost::migrations: hard linking attachments out of site/attachments
2024-10-03T15:30:33.411823Z INFO autost::command::import: writing RelativePath { inner: "posts/imported/1.html", kind: Other }
2024-10-03T15:30:33.422458Z INFO autost::command::import: click here to reply: http://[::1]:8420/posts/compose?reply_to=imported/1.html
shoutout @delan for a lovely carbonara


autost is a cohost-compatible archive and blog engine. it’s pretty much a static site generator that can import chosts, but i plan to eventually add a rss/atom feed reader and chronological timeline.
you no longer need to know how to use git or cargo to use it! and now you can write posts and reply to posts in the composer!
cohost is shutting down soon, so go here for updates or email me on autost@shuppy.org if you have any questions. enjoy :3

want to archive your chosts on your website but have too many for the cohost web component? want something like cohost-dl except you can keep posting?
autost is my take on that. you can see what it looks like on shuppy.org:


it’s pretty much a static site generator that can import chosts. some features:
i’ve only had a couple weeks to work on this, so it’s not the most polished, and for now you need a bit of command line knowledge to get it going.
but my goal here is to make a blog engine with the same posting and reading experience as cohost, where you can follow people with rss/atom feeds, see their posts on a chronological timeline, and share their posts on yours.
does that vibe with anyone? should i keep working on this? let me know!
some big usability improvements in this one, plus a couple of breaking changes!
breaking changes: cohost2autost no longer takes the ./posts and site/attachments arguments, and render no longer takes the site argument. these paths were always ./posts, site/attachments, and site (#8).
when viewing your site with the server, there’s a compose button now (#7).
in the server, you also get a link to your site in the terminal now, and you no longer get a NotFound error if your base_url setting is not /.
you no longer have to type RUST_LOG=info to see what’s happening (#5).
attachment filenames containing % and ? are now handled correctly (#4).
questions and contributions are welcome! if you run into any problems, or want to help out, let me know on github or email me on autost@shuppy.org.
oh and go here for updates once cohost noposts :)
rebug for the morning crew! please let me know if autost works or doesn't work for you, and go here for updates ^w^
want to archive your chosts on your website but have too many for the cohost web component? want something like cohost-dl except you can keep posting?
autost is my take on that. you can see what it looks like on shuppy.org:
it’s pretty much a static site generator that can import chosts. some features:
i’ve only had a couple weeks to work on this, so it’s not the most polished, and for now you need a bit of command line knowledge to get it going.
but my goal here is to make a blog engine with the same posting and reading experience as cohost, where you can follow people with rss/atom feeds, see their posts on a chronological timeline, and share their posts on yours.
does that vibe with anyone? should i keep working on this? let me know!
some big usability improvements in this one, plus a couple of breaking changes!
breaking changes: cohost2autost no longer takes the ./posts and site/attachments arguments, and render no longer takes the site argument. these paths were always ./posts, site/attachments, and site (#8).
when viewing your site with the server, there’s a compose button now (#7).
in the server, you also get a link to your site in the terminal now, and you no longer get a NotFound error if your base_url setting is not /.
you no longer have to type RUST_LOG=info to see what’s happening (#5).
attachment filenames containing % and ? are now handled correctly (#4).
questions and contributions are welcome! if you run into any problems, or want to help out, let me know on github or email me on autost@shuppy.org.
oh and go here for updates once cohost noposts :)
:/
awesome ldap is where two buddies get so excited they can barely fumble their new openldap cdrom into their directory server, crush it up, snort it, and bite each oth
want to archive your chosts on your website but have too many for the cohost web component? want something like cohost-dl except you can keep posting?
autost is my take on that. you can see what it looks like on shuppy.org:
it’s pretty much a static site generator that can import chosts. some features:
i’ve only had a couple weeks to work on this, so it’s not the most polished, and for now you need a bit of command line knowledge to get it going.
but my goal here is to make a blog engine with the same posting and reading experience as cohost, where you can follow people with rss/atom feeds, see their posts on a chronological timeline, and share their posts on yours.
does that vibe with anyone? should i keep working on this? let me know!


oh and i’ve updated my contact details!! say hi and send me stuff :3
i had an old website, but for a variety of reasons it really didn’t feel like a good successor to my cohost page. i feel like what i really want is to Continue Chosting next month, just on my own website? (well no, what i really want is cohost, but failing that…)
so i made this! and many of my old chosts are there now too! i’ll need a bit more time to figure out how to actually make new posts (lol) and have them play nice with my old chosts, but hey, now you know where to find me once i do o/
i gotta pay down this tech debt asafp or this thing is gonna burst into treats.
also, clicking “publish” in the composer redirects you to the post now, but i figured this would be funnier than posting a screenshot of a redirect.
oh and i’ve updated my contact details!! say hi and send me stuff :3
i had an old website, but for a variety of reasons it really didn’t feel like a good successor to my cohost page. i feel like what i really want is to Continue Chosting next month, just on my own website? (well no, what i really want is cohost, but failing that…)
so i made this! and many of my old chosts are there now too! i’ll need a bit more time to figure out how to actually make new posts (lol) and have them play nice with my old chosts, but hey, now you know where to find me once i do o/
I use (fluent-reader)[https://github.com/yang991178/fluent-reader]
thanks, i’ve fixed that now!
fluent-reader seems to need a <base> tag in each <content> to tell it how to resolve relative urls. it doesn’t support xml:base, which i’ve now reported to the devs, but it turns out my feeds didn’t have that either. my bad!

late update
“clearly, aliens is derivative of the work of the great joseph staten” — halo player watching aliens (1986) for the first time
One of my main goals with my new blog is to preserve the concept of "reposting" that's both a successful and, I think, desirable aspect of the "social network" model. It's a great way to spread visibility of other people's work and engage in conversation across different blogs. It's a big part of why I'm putting so much work into the concept of "embeds", as for Cohost and Letterboxd.
These embeds are quite automated: I just drop a link in my blog and as long as it's one of the supported sites, a little post-processing tool automatically fetches the information and adds it as template params. All in all, I'm pretty happy with this flow, but there's one critical problem: it requires me to write a separate scraper for every website.
The great strength of independent websites for social interaction is that everyone's can be as different as they'd like, but that also means that there's no standard way to understand or interact with them. Even something as simple as "what is the text of the post at this URL" is difficult to answer in general. We'd all hope that everyone would use semantic HTML so perfectly that you could just read the contents of the outermost <article> tag on the page, but the real world is never so pristine. We need a more explicit way to indicate the critical prose and metadata for something that's considered a "post".
I've been rolling this problem around in my head for the past week, and I have what is at least the germ of an idea. The core observation is that RSS and Atom feeds already have all the metadata that's strictly necessary for something like this, but they suffer from being time-limited—their use-case is focused on syndication, so a website can only be expected to have its most recent posts available in such a nice format.
So imagine if we co-opted this format for use in something more persistent. Something like:
<link rel="somens:reblog" href="post.xml">where the XML file looks like
<?xml version="1.0" encoding="utf-8"?>
<reblog xmlns="https://nex-3.com/somens" xmlns:atom="http://www.w3.org/2005/Atom">
<atom:link href="https://nex-3.com/blog/once-i-add-the/post.xml" rel="self"/>
<atom:link href="https://nex-3.com/"/>
<atom:entry>
<atom:link href="https://nex-3.com/blog/once-i-add-the/" rel="alternate"/>
<atom:id>https://nex-3.com/blog/once-i-add-the/</atom:id>
<atom:published>2024-09-20T07:06:00Z</atom:published>
<atom:updated>2024-09-20T07:06:00Z</atom:updated>
<atom:author>
<atom:name>Natalie</atom:name>
<atom:uri>https://nex-3.com/</atom:uri>
</atom:author>
<atom:category>meta</atom:category>
<atom:content type="html"><p>Once I add the ability to embed arbitrary blog posts from other blogs on here it's over. I'm gonna be reblogging like a wild animal. Y'all are gonna have your eyes blown clean outta your heads.</p></atom:content>
</atom:entry>
</reblog>
Do you see my vision? This is mostly just stealing structure from Atom, but with the explicit guarantee that any logical "entries" on the page in question will also exist in the "reblog" XML. Maybe there should be some sort of way to explicitly link the two as well, idk. But in the general case, a page with one post would link to a single-post XML file which could then be used as the source for a reblog. Wouldn't that be neat?
Edit: Something like this already exists! Hooray!
i’ve been working on something similar that will rely on this (see #shuppy.org, autost). my posts are in an html-fragment-based format, which looks something like this:
<link rel="references" href="7801740/7742758.html">
<link rel="references" href="7801740/7800234.html">
<meta name="title" content="the post hole works">
<meta name="published" content="2024-09-22T14:24:07.963Z">
<link rel="author" href="https://cohost.org/delan" name="shuppy (@delan)">
<meta name="tags" content="shuppy.org">
[post content in markdown or html here]this is not the best interchange format for others to reblog, though, because it relies on you rendering markdown the same way as me, and you would need to fetch the posts i’m replying to separately. your idea would really help with that!
one suggestion: it would be nice if the format you came up with was also usable in the “whole blog” feed, where each <atom:entry> is a post, including the posts it replies to. i started thinking about atom-compatible ways of doing that in this chost.
oh and i’ve updated my contact details!! say hi and send me stuff :3
i had an old website, but for a variety of reasons it really didn’t feel like a good successor to my cohost page. i feel like what i really want is to Continue Chosting next month, just on my own website? (well no, what i really want is cohost, but failing that…)
so i made this! and many of my old chosts are there now too! i’ll need a bit more time to figure out how to actually make new posts (lol) and have them play nice with my old chosts, but hey, now you know where to find me once i do o/
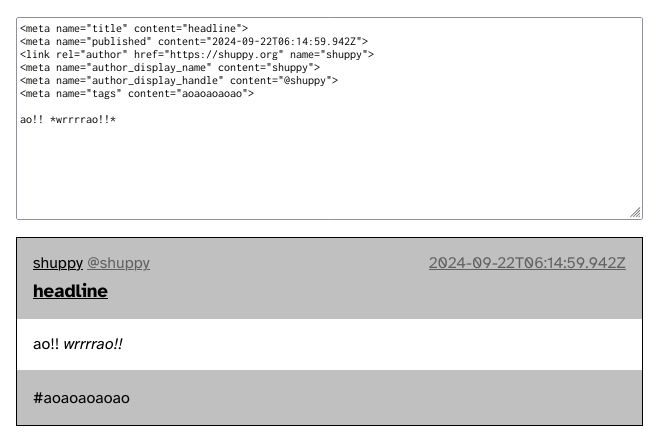
is this thing on?
oh and i’ve updated my contact details!! say hi and send me stuff :3
i had an old website, but for a variety of reasons it really didn’t feel like a good successor to my cohost page. i feel like what i really want is to Continue Chosting next month, just on my own website? (well no, what i really want is cohost, but failing that…)
so i made this! and many of my old chosts are there now too! i’ll need a bit more time to figure out how to actually make new posts (lol) and have them play nice with my old chosts, but hey, now you know where to find me once i do o/

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 200, 300 mm, f/7.1, 1/500

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 200, 300 mm, f/7.1, 1/800

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 200, 300 mm, f/7.1, 1/800

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 200, 300 mm, f/8, 1/800

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 200, 300 mm, f/6.3, 1/500

oh and i’ve updated my contact details!! say hi and send me stuff :3
i had an old website, but for a variety of reasons it really didn’t feel like a good successor to my cohost page. i feel like what i really want is to Continue Chosting next month, just on my own website? (well no, what i really want is cohost, but failing that…)
so i made this! and many of my old chosts are there now too! i’ll need a bit more time to figure out how to actually make new posts (lol) and have them play nice with my old chosts, but hey, now you know where to find me once i do o/
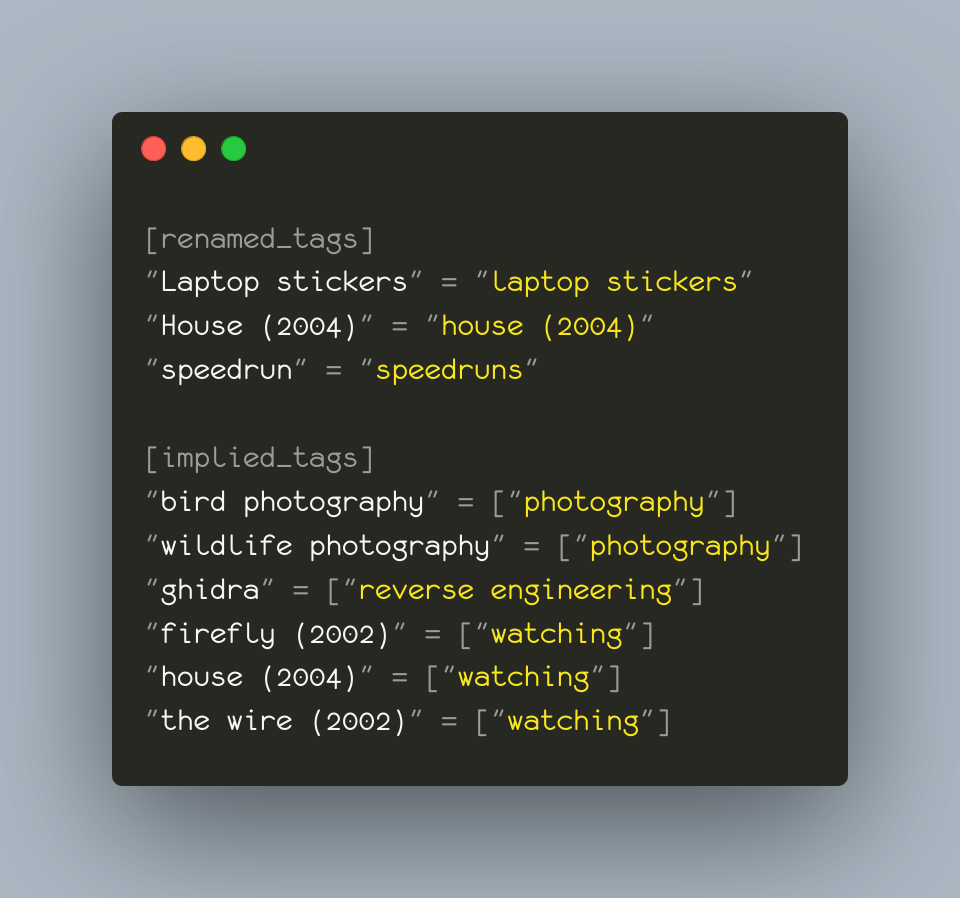

to better curate my chosts even after cohost shuts down, i can not only tag chosts without editing them, but also rename tags and add related tags automatically. for example:
(the blog software is here, if you wanna play around with it)

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 400, 300 mm, f/13, 1/800

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 200, 300 mm, f/7.1, 1/640

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 200, 300 mm, f/8, 1/640
Just thought I would let you know that your rss page uses relative urls for the photos, which prevents my rss reader from being able to display them. I am not sure if this is an issue with my own rss reader or if this is something that affects all rss readers.
thanks for the heads up! i've been testing with freshrss so far, if you can tell me what reader you use that would be really helpful


Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 1600, f/6.3, 1/320, 300 mm

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 1600, f/6.3, 1/640, 300 mm
oh and i’ve updated my contact details!! say hi and send me stuff :3
i had an old website, but for a variety of reasons it really didn’t feel like a good successor to my cohost page. i feel like what i really want is to Continue Chosting next month, just on my own website? (well no, what i really want is cohost, but failing that…)
so i made this! and many of my old chosts are there now too! i’ll need a bit more time to figure out how to actually make new posts (lol) and have them play nice with my old chosts, but hey, now you know where to find me once i do o/
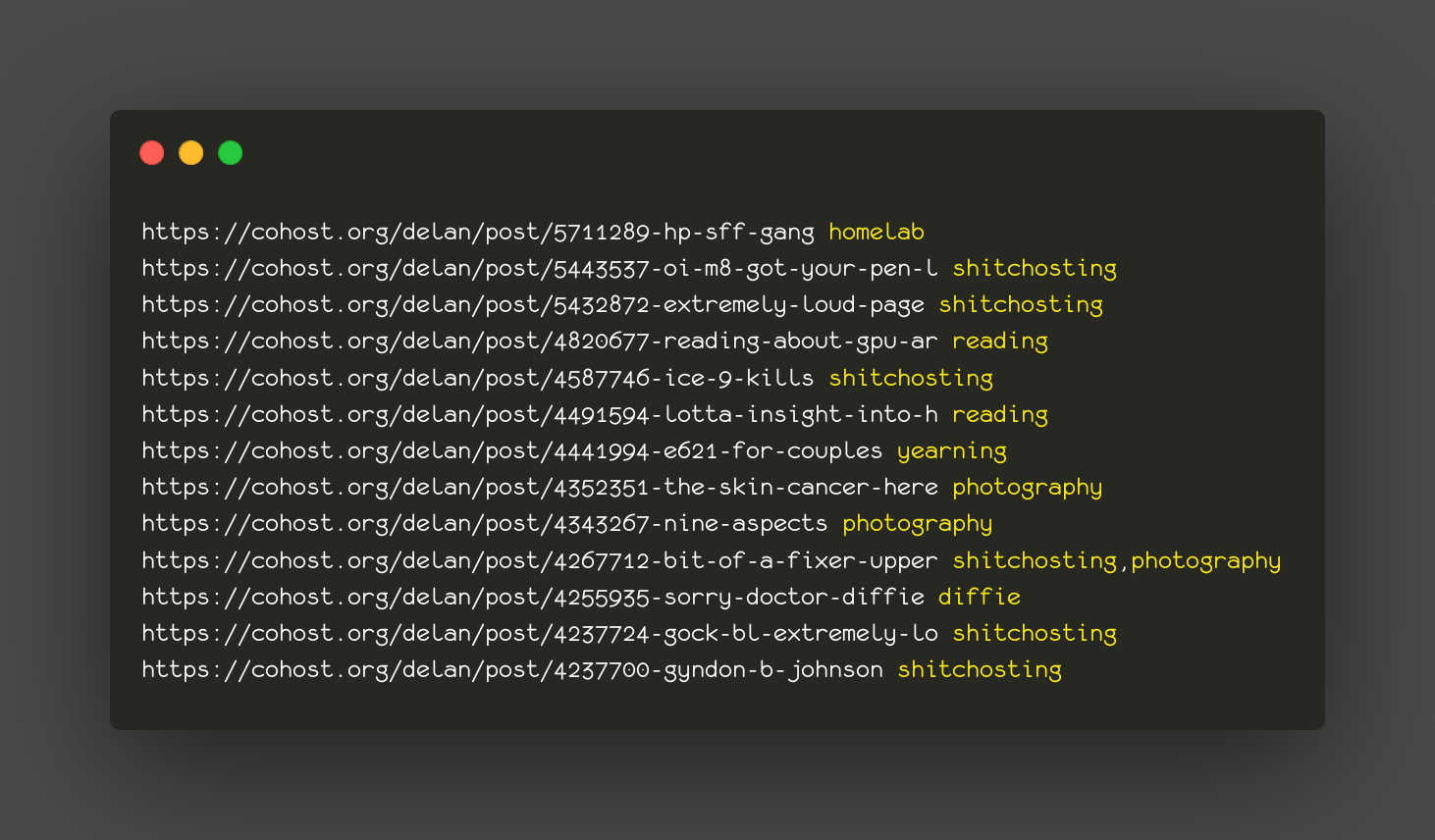

next stop: tag synonyms and tag implications
what if rss or atom had a way to say that a post was in reply to another post from another feed. and feed readers let you display posts in threaded order
what if atom had a way to embed a copy of the post you're sharing or replying to, not just link to it? i would say just add a second <content>, but that’s forbidden :(
edit: hmm how about nesting <entry>, or putting an <entry> inside the <link> (instead of self-closing <link/>). per § 6.4.2, we may be able to nest <entry> as long as we have a foreign element in between, like <atom:entry><cohost:reply><atom:entry>
oh and i’ve updated my contact details!! say hi and send me stuff :3
i had an old website, but for a variety of reasons it really didn’t feel like a good successor to my cohost page. i feel like what i really want is to Continue Chosting next month, just on my own website? (well no, what i really want is cohost, but failing that…)
so i made this! and many of my old chosts are there now too! i’ll need a bit more time to figure out how to actually make new posts (lol) and have them play nice with my old chosts, but hey, now you know where to find me once i do o/
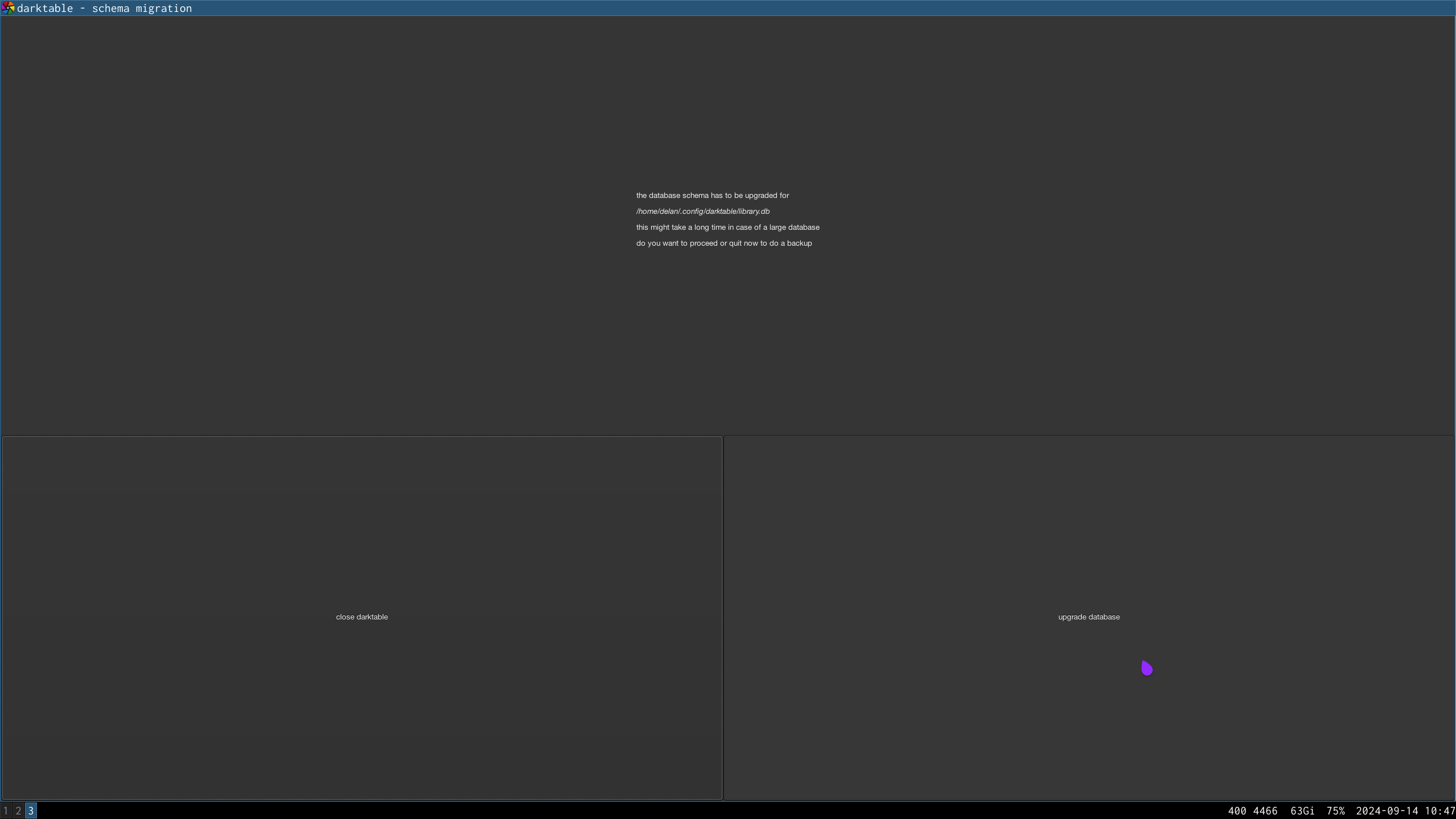
text/plainI can’t agree more J
signed: a guy who lost points of sanity having to fork HTML parsers to explicitly not crash on non valid HTML in emails because, well, Gmail parses it fine so I have to parse it fine too
text/plainI can’t agree more J

(details)

i saw my first ever currawong! this guy belongs to the western subspecies of grey currawong (Strepera versicolor plumbea), historically known as the leaden crow-shrike. the wikipedia page listed it as a “leaden cuckoo-shrike” in some places, but checking the cited Whitlock (1910), that seems to have been a mistake.
(details)
As proposed by alex norris of webcomic name:
https://webcomicname.com/post/758899080600715264
Three-pane comic titled "learning", from "webcomic name" (alex norris):
Examples:
... I'm actually having a hard time coming up with good examples, because most of the ones I can think of are complicated or obscure enough that I can't explain them in one sentence 🙃
 click the lever!
click the lever! oops, it's stuck...
oops, it's stuck... Now you're thinking with
Now you're thinking with
 Now you're thinking with portals!
Now you're thinking with portals!

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 400, f/13, 1/500, 220 mm

(details)

(details)

(details)



(details)

(details)

Nikon D3200 + AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
ISO 200, f/5.6, 1/200, 300 mm

(details)

i was unsure of this one and this other one, because they seemed way too round to be brown honeyeaters! but now i think these are just juveniles.
anyone know why cohost’s thumbnailer destroys this?
(details)
VTOL means Vermont: Take Off and Leave
DFU means Dallas/Fort Uorth


testing my new camera right after sunset. not gonna pretend these are great shots, but the fact that i can get something almost usable out of it at iso 3200 is neat.
(details)

there are no high-quality image versions of these stickers that i could find online (they're the Pharmaceutical Society of Australia's "Cautionary Advisory Labels") so i had to make my own (well, didn't really have to, just wanted to). and then i noticed this incredible coincidence.
network telephone service access code test number at VXG 4 MSC.


network telephone service access code test number at VXG 4 MSC.

(details)
@delan: sous vide? that's where you like boil a bag right
@bark: like, you're not wrong. but it's the kinda thing someone who's only /seen/ sous vide would say. you've never done sous vide. you've only seen someone do it. you've seen someone put some Meat in a Bag and then dunk it in some water. it's like you're not allowed within 400 feet of a sous vide. like you've only perved on sous vide through a window. you know how they say "10000 ft perspective"? this is. this is so much further than ten thousand feet. i think an alien who saw sous vide all the way from their planet in space would be able to tell me more

this concludes our intensive three week course
@delan: sous vide? that's where you like boil a bag right
@bark: like, you're not wrong. but it's the kinda thing someone who's only /seen/ sous vide would say. you've never done sous vide. you've only seen someone do it. you've seen someone put some Meat in a Bag and then dunk it in some water. it's like you're not allowed within 400 feet of a sous vide. like you've only perved on sous vide through a window. you know how they say "10000 ft perspective"? this is. this is so much further than ten thousand feet. i think an alien who saw sous vide all the way from their planet in space would be able to tell me more



“she’s a real gooner in the doona” — hypothetical review of yours truly
gooner? i barely knower
love too be shown the Windows™ Welcome Experience™ on my ci runner after updates and occasionally when I sign in to highlight what’s new and suggested
i've been looking around at keyboard options for my SPARC system and I was surprised when I saw your project on cohost; by chance have you had any experience with the sun type-3 keyboard interface? my sun-4/110 is one of the early SPARCs before they switched to the mini-din type-4 keyboards.
i'm afraid not :( my oldest sun machines are sparcstation ipc, which is still type-4. i wonder if the type-3 is electrically similar?
how many meanings can one tag have?
the most i’ve found is #goon, with four (4)
scientists have discovered a fifth kind of goon, which no one has chosted about yet

rugby union review: dudes rock



if you run mkfs.fat in a nix-shell, the default volume id will be 12CE-A600 every time, which interacts poorly with anything that relies on fs uuids
(mkfs.fat uses SOURCE_DATE_EPOCH when available, and nix-shell sets that to 0x12CEA600 = 315532800 = 1980-01-01)
describing my shower status on a spectrum from “spooling up” to “hot if you have a scent kink” to “past my prime”
does anyone ever want to use lsof(8) or fuser(1) for any reason other than "why can't i unmount this filesystem"



molasses implies the existence of molads and mononbinary pals
bippo and beppo implies the existence of not just zippo, but also zeppo

(details)



















* may not work after 1993
https://www.youtube.com/watch?v=idOy3p5opcQ
ty @srxl for getting me back into osu :3
https://www.youtube.com/watch?v=6IVp-wCJsp8&t=0s
top diff let’s gooo

https://www.youtube.com/watch?v=idOy3p5opcQ
ty @srxl for getting me back into osu :3

SPARCstations have a unique serial-like interface for keyboard and mouse input, using a single 8-pin mini-din port. usb3sun allows you to use an ordinary usb keyboard and mouse with your sun workstation, and now rev B0 is available on tindie!
this revision has been all about polish, with improvements to reliability and debuggability. we’ve fixed bugs where resetting the adapter drops you into an ok prompt (#2) and (rarely) hangs until power cycled (#11), and you can now use the debug uart without disabling the sun keyboard interface (#10).
we’ve also added a fun new debug cli, allowing you to send keyboard and mouse input to the workstation via the (now always accessible) debug uart. while it doesn’t yet support all possible inputs, you can already use this as a limited form of automation!
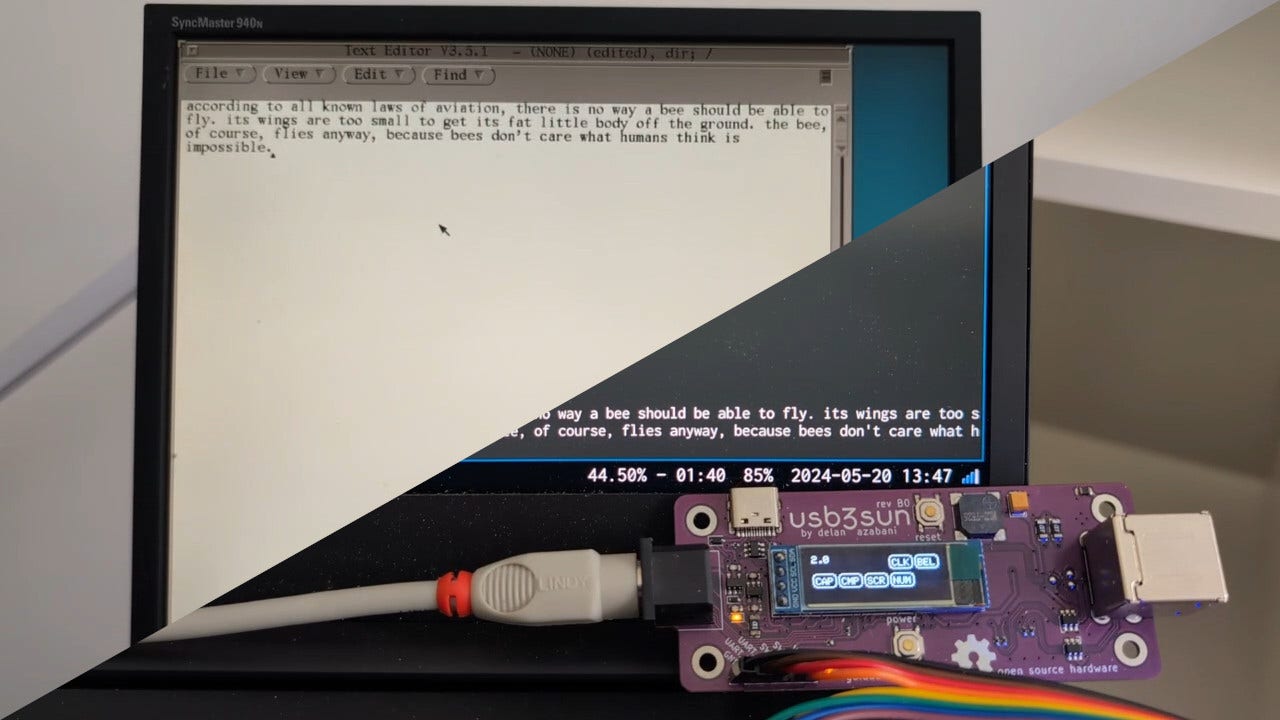
since we still have a few rev A3 adapters left in stock, those are now 20 USD off on tindie. rev A3 is affected by the reset errata, and lacks support for debugging with the sun keyboard interface enabled, but for most people it should still be more than usable.

legodude designed a 3d-printed enclosure for the usb3sun! it should be compatible with all boards rev A1 and newer, though it doesn’t currently provide access to the debug header or led indicators.
when resetting older adapters, the workstation would drop you into an ok prompt. this pauses the running operating system (or program) until you type “go” to continue, but programs don’t always handle that well. for example, on solaris running X11, the screen contents may get mangled and it may even kernel panic if booted over nfs.
sun workstations are designed to pause when the keyboard is disconnected and reconnected. they do this by detecting if the keyboard tx line goes from the “break” state to the “idle” state. there are actually only two symbols ever transmitted over a serial line, “mark” (1) and “space” (0), so what are “break” and “idle”?
the receiver (workstation) holds the line in “space” (0) by default, but the sender (keyboard), if present, holds the line in “mark” (1) by default. since every frame starts with a “space” (0), we know that nothing is being sent if there are no spaces. this is known as “idle”.
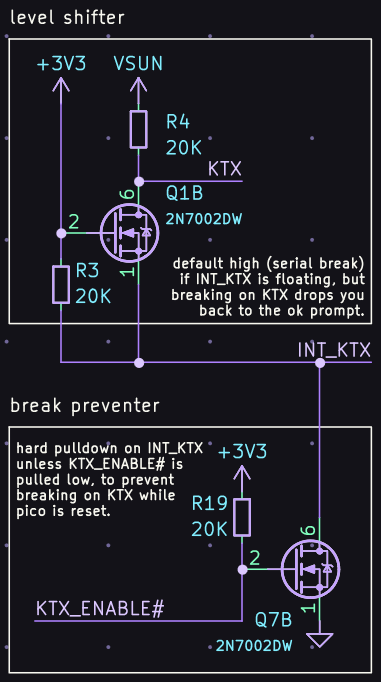
since an 8N1 serial line also guarantees at least one “mark” (1) every ten symbols, the receiver can infer that nothing is connected if the line is “space” (0) for longer than that. this is known as “break”.
but the workstation also pauses when we reset our adapter, because during reset, INT_KTX is floating, leaving our level shifter to its default state of high, which in sun’s inverted serial logic means “space” (0). this is indistinguishable from a break.
we fixed this by adding a mosfet that pulls INT_KTX low unless the firmware asserts KTX_ENABLE#. during reset, KTX_ENABLE# is deasserted by a pullup resistor.
resetting older adapters can also make them hang until power cycled, especially if you mash the reset button several times in quick succession. you’ll know when this happens because the pico’s onboard led indicator will be stuck on.
this happens because the display module malfunctions, holding SDA low so we can’t send anything. while the SSD1306 itself has a reset pin, the 4-pin display modules that we use do not, so there’s no way to reset them when they malfunction.
we fixed this by adding a mosfet that acts as an external reset, disconnecting the display from ground unless the firmware asserts DISPLAY_ENABLE. during reset, DISPLAY_ENABLE is deasserted by a pulldown resistor.
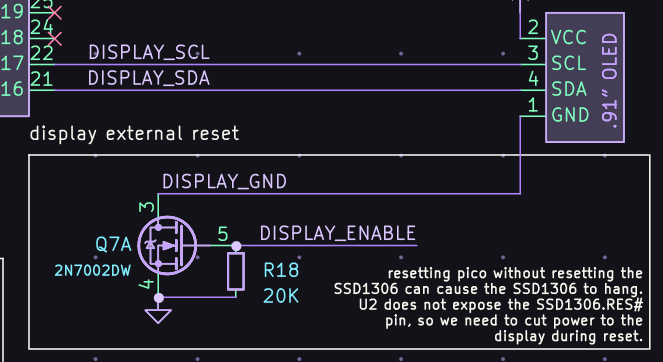
for proper debug logging that includes deps like tinyusb and arduino-pico, we need to use our serial debug port (UART_TX and UART_RX). logging over usb cdc is fragile, breaks when stepping through a debugger, and for tinyusb it would also be a chicken-and-egg.
to avoid a chicken-and-egg inside arduino-pico, we need to use a hardware uart specifically, because everything other than the hardware uart module itself, including the other serial modules, expect that they can use debug logging for errors.
we’re already using both hardware uarts for the sun interface — one for the sun keyboard (sunk) and one for the sun mouse (sunm), so we need to move one of those to SerialPIO, a pio-based uart. but some pio resources are already taken up by usb and the buzzer (as of this commit):
the state machines fit easily, e.g. (1+1+1)/4 sm on pio0, (2+1)/4 sm on pio1.
the instructions? not so much. even ignoring the split between pio units, 22+31+9 = 62/64 instructions, which leaves no space for 6 or 7 more, so we need to move the buzzer back to hardware pwm.
now we’re at 22+31 = 53/64 instructions, again ignoring the split, which is enough for 6 or 7 more, but not 6 and 7 more, so we can only move one tx or one rx to pio, not both.
but moving one rx to pio would not be useful for debug logging, so we can only move one tx to pio, not both or just one rx.
uarts operate at a single baud rate in both directions, which is 1200 baud for the sun keyboard, so if we move sunk tx to pio, the debug port would need to run at 1200, not 115200 baud. this is not a problem for the sun mouse, which has no rx, so we need to keep the sun keyboard on a hardware uart while moving the sun mouse to pio.
this gives us 1+2+1 = 4/8 sm and 22+31+6 = 59/64 instructions, which we can split such that pio0 has 1+1 = 2/4 sm and 22+6 = 28/32 instructions, while pio1 has 2/4 sm and 31/32 instructions. so we’re done right?
in our pcb, the debug port was on UART0, the same hardware uart as the sun keyboard, so we need to move either the debug port or the sun keyboard to UART1.
since the hardware uarts have restrictions on which pins you can use them with, and none of the pins can be used with both uarts, that means both of them were wired to pins only valid for UART0, so we’ll also need to change our pcb.
older versions of adafruit tinyusb, prior to these commits that were completely unrelated to debug logging, only supported debug logging to Serial1 (UART0), so i figured it was preferable to move the sun keyboard to UART1 while keeping the debug port on UART0.
so altogether, here’s what we had to do…
…and here’s how we made the pcb changes!

since we still have a few rev A3 adapters left in stock, those are now 20 USD off on tindie. rev A3 is affected by the reset errata, and lacks support for debugging with the sun keyboard interface enabled, but for most people it should still be more than usable.
thanks for making july our biggest month ever!
adobe acrobat just gave me a loud audible notification to make it my default pdf reader.
it is 2am. i have not opened a pdf since turning this computer on. wh-
this has been your first warning.














this is a new technique that experts are calling the Brick Opening. you just pack all your pieces into a Brick
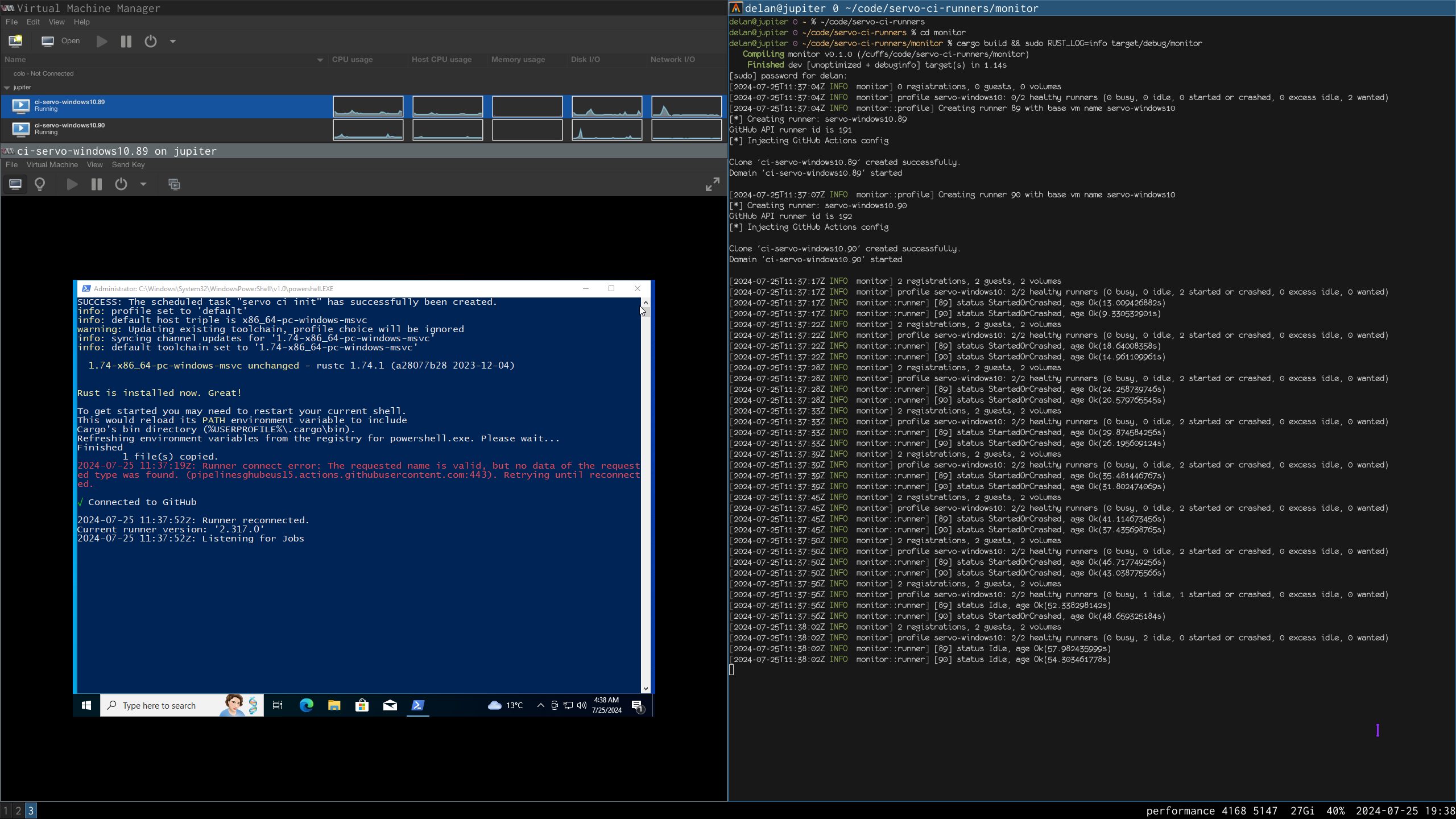
hehehe i'm totally lying on my back with my pawsies in the air holding up a toy so happy

Like this

i think?



left to right: female adult, male adult, juvenile











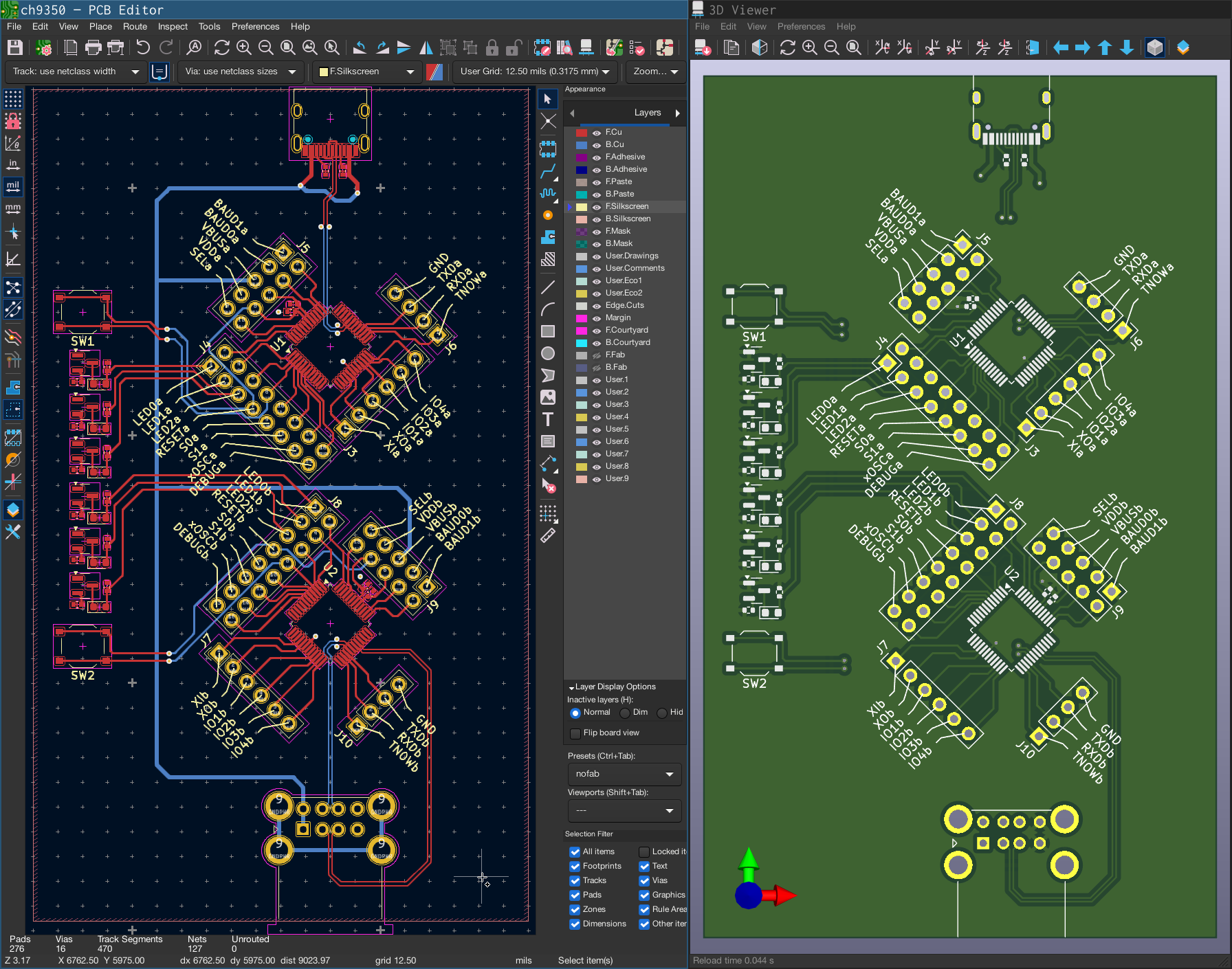
could this be the thing that finally irons out all my usb hid compat issues, or is the ch9350 just a mcu with tinyusb in a trenchcoat? one way to find out






Listen I need people to know about this. This is widely-known in culinary circles but the general public has not been properly informed of how this works.
In industrial pasta making, pasta dough is forced through a shaping tool known as a 'die' and extruded into shape. Traditionally, these dies are made out of machined bronze; bronze is food-safe and dissipates heat well, which is important because those dies get quite hot as large volumes of dough are forced through.
More modern dies are made out of steel and coated with Teflon, which extends their usable life and is cheaper. It also allows the machines to just push more volume of pasta out.
The bronze dies essentially impart their tool marks from the machining process onto the extruded pasta, creating a roughened texture full of micro-scale scratches. The PTFE-lined dies, predictably, don't.
You can tell this, of course, if you compare a Barilla fettucine to a De Cecco fettucine, the latter is just noticeably rougher. These surface imperfections left by the traditional bronze process cause the pasta to 1. shed more starch as it cooks, leading to starchier pasta water that is a more effective emulsifier for sauces, 2. retain a rough microtexture that captures and holds on to sauces better.
As a result, bronze-die pasta just gives you better results even though the ingredient list is identical to that of other pastas.
Pasta that is bronze-cut generally says so on the packaging. Barilla is, notably, not bronze-cut in spite of costing as much as several brands that are.
Everybody wants to talk about the technology of steampunk but never what fuel is needed to run it. It's coal btw. Might as well call that shit coal-fantasy.
"uhhh... oh, that's not coal smoke, it's steam! steam from the steamed punks we're having! mmmm, steamed punks!"
ever since i found out that nuclear plants produce power by just making steam really fast, and therefore nuclear power is also steampunk, i've been so mad about this
hey you don't have to power those boilers with coal OR itanium or whatever. the reason there isn't much old growth forest in the northeastern United States is most of it was chopped down to fuel trains in the 1800s.
“girls could fix me” but in a tone that implies this is not just a hope, but a last resort
(this is critical to my operation, but i won't require it to allow for girl product differentiation)

i live with this idiot baby
_________
TOILETSIT
OPTININAU
(as of 9 june 2023, § 40)





note: currently hard linking saves 1115.40 MiB
35499 store paths deleted, 89914.82 MiB freed
Hiya,
What are you using to take photos of birds? Those circle photos are really cool, are they edited or come from a particular kind of camera or something?
Thanks
thanks! the circles are from taking them through binoculars (this camera through these, for the most part). sometimes i end up zooming or cropping the circle out of frame.
this is pretty cumbersome, since any movement or tilt of my phone relative to the binoculars can ruin the shot, but hey, we make do with the tools we have :)

(taken by @bark)
oaughhh your clock is too fast. oaaugghh im angry im gonna behave badly. im gonna do wild stuff. oaaguaguauguugg your timing is wrong your routing is bad ouaoiuoiauieuoghh im a silly little fpga
wehhhhh you can’t compare these types. here are 84 unviable candidate function templates i found instead, do you like that. wraughh i can’t find a matching constructor for your initialiser. steve waauggh i don’t know how to deal with blink gc traceable objects in optionals but telling you what to do instead is simply too hard. im just a smol bean, a silly little toy hobby browser engine project
you've heard of predatory journals. now, get ready for prey journals. they're so small. be careful, don't squish them with your huge impact factor
impact_difference
i really miss the woolies pecan danish. it was pretty dense, being a danish, the custard + icing + pecan combo was delicious, and it was generously big, except in the last few months before its demise.
i got pretty good at convincing mum to buy one every shop, but now it's gone and no one else seems to sell anything comparable. might have to learn how to bake one myself >:3

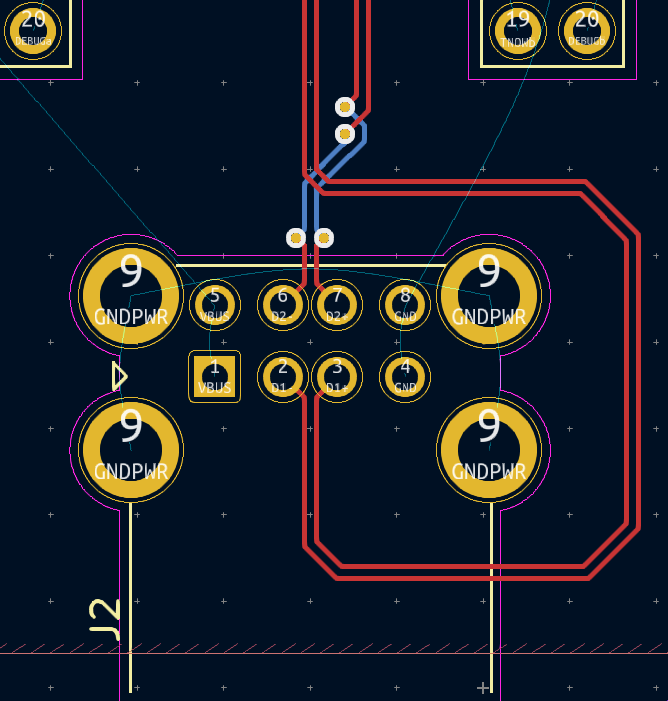





with @bark
v0 (code) = 57485 polygons, one for each pixel, split into chunks of 10000 due to desmos limits. it’s pretty much unplayable in firefox, and it hangs indefinitely in chrome.
v1 (code), above = 5754 polygons, run-length encoding contiguous white pixels within a scanline. it now runs in chrome and safari, and on mobile too, but it’s still not the smoothest and sometimes firefox just gives up on playback for no apparent reason.
i think the next step is to find contiguous regions in 2d, but first, let’s make a test card (code) so we can avoid off-by-ones in time and space.

※ these words have no meaning, they just popped into my head, and I needed to type them

The spacing and font size is off, but I don’t care :3.
Original logo sourced from: here (the font used is also listed).

The thrilling sequel. Couldn’t think of a funny thing to change “microsystems” to.
❖ ❖ ❖
Original logo taken from here
Font used is “ITC Garamond Book Condensed Italic”.
Feel free to do anything you want with these edited logos btw :3. No need to credit me.













australian chastity cage, call it a Locked Bag
kangaroo in chastity, call that a locked 袋鼠
7
6, but also 5
4
3
two (2)
twenty (20) hours

7
6, but also 5
4
3
two (2)
twenty (20) hours
7
6, but also 5
4
3
two (2)



![doggirl standing in front of a "[no dogs symbol] in bird sanctuary" sign with a shit-eating grin](/posts/attachments/e54356e9-8d9f-42f8-87fc-2db4fd384889/PXL_20240526_075623316.MP.jpg)
forljg ulnk fmld when you’re in game, call that a qwksfo h;hkjf
bj;ukg iuef bmur when you leave game, call that a cyifhae hyhfkb
forljg ulnk fmld when you’re in game, call that a qwksfo h;hkjf
7
6, but also 5
4
3
what if,, we ran our central pattern generators in a phase-locked loop, and we were both girls 🥺
7
6, but also 5
4


This is the same image, as a GIF ready to be imported to Windows 95.
The image looks vertically stretched, because it is rendered with non-square pixels in Windows.
Open in Internet Explorer; right-click, save picture as, and select "BMP File" under type.
Save it, then open it in Paint. Select all, copy.
Open another Paint window, and open \Windows\logos.sys.
Paste over the image, then save it. Shut down to see it in action.

7
6, but also 5
being a hobbyist means that every few days you must buy a $30 tool. even if you don't think you'll need another $30 tool, the universe will manifest a tool for you to spend $30 on. all must pay
the most important thing in my life is converting my calling partners to nesting partners
7
![Belter Creole [lang belta], language codes “qbc” (iso 639-3) and “art-x-belter” (ietf)](/posts/attachments/ef8937e6-24d9-4b49-8950-afe343a2ffab/image.png)
belter creole has two language codes, “qbc” and “art-x-belter”. but how?
“qbc” is from the “reserved for local use” area (“qaa” through “qtz”) of the three-letter iso 639-3 language codes, like “eng” for english, “cmn” for mandarin chinese, or “ckb” for sorani. conlang code registry is a project to informally coordinate “assignments” in this area for conlangs, and that’s why belter creole is “qbc”. who knows, maybe someday it will transcend the expanse (2015) and upgrade to a standard code, like toki pona did from “qtk” to “tok”.
this reminds me of cambridge g-rin, a project to informally coordinate “assignments” in the rfc 1918 address spaces, that is, private ipv4 addresses like 10.0.0.1 and 192.168.0.1. in both cases, a public registry that allows anyone who knows about it to avoid taking someone else’s spot.
“art-x-belter” starts with “art”, the iso 639-3 code for “artificial languages”. the “-x-belter” part uses an ietf extension to those codes (bcp 47) that lets you add “private-use” extra details, and that’s why belter creole is “art-x-belter”. internet standards love “x-” for private use. see also http headers like “X-Real-IP” or “X-Forwarded-For”, or mime headers like “X-Spam-Score”.
by the way, another language code with private-use extra details is in the html spec, of all places. thanks hixie :)
<!DOCTYPE html>
<html class="split index" lang=en-US-x-hixie>
<script src=/link-fixup.js defer=""></script>
<meta charset=utf-8>
[...]https://datatracker.ietf.org/doc/html/rfc6648
i am sorry to report but the internet no longer loves x-headers
The primary problem with the "X-" convention is that unstandardized parameters have a tendency to leak into the protected space of standardized parameters, thus introducing the need for migration from the "X-" name to a standardized name. Migration, in turn, introduces interoperability issues (and sometimes security issues) because older implementations will support only the "X-" name and newer implementations might support only the standardized name. To preserve interoperability, newer implementations simply support the "X-" name forever, which means that the unstandardized name has become a de facto standard (thus obviating the need for segregation of the name space into standardized and unstandardized areas in the first place).
a related example of these problems is on the web platform, with vendor prefixes in css and javascript. they sound like a good way to mark something as experimental, but in practice they just made a mess that forces browsers and webdevs to write everything five times:
-webkit-transition: all 4s ease;
-moz-transition: all 4s ease;
-ms-transition: all 4s ease;
-o-transition: all 4s ease;
transition: all 4s ease;window.requestAnimationFrame =
window.requestAnimationFrame ||
window.mozRequestAnimationFrame ||
window.webkitRequestAnimationFrame ||
window.oRequestAnimationFrame ||
window.msRequestAnimationFrame;in some cases, we’ve even come full circle with the permanence of vendor prefixes: the standard (and in fact only) way to set the stroke or fill color of text in html is to use -webkit-text-stroke and -webkit-text-fill-color.
nowadays we prefer to put experimental features behind feature flags, requiring either the user to opt in, or a specific website to opt in for a limited time only. this allows webdevs to experiment with these new features as they evolve, without allowing them to rely on the feature in its current state in production. what are you gonna do, tell your customers that they need to change some weird browser setting to use your bank website?
the internet is the only thing in computing we’ve ever built at such a large scale, and this has had fascinating implications for language and protocol engineering.
postel’s law was once considered a fundamental principle of the internet, but we’ve since found that it can cause some gnarly problems with interoperability, and it can even interfere with our ability to make intentional changes and improvements down the line.
speaking of interfering with our ability to make intentional changes and improvements, even well-intentioned extension mechanisms can prove impossible to use in practice. this is known as protocol ossification.
dns is the protocol for looking up domain names like “cohost.org”. names consist of labels, like “cohost” and “org”, and there’s even a special type of label to help with compressing dns messages. but the other two label types, while reserved for future use, are actually impossible to ever use because we forgot to specify how many bits they take up. if no existing dns software knows how many bits to skip, that makes any message containing such a label unreadable from that point onwards.
cryptographic agility, by adam langley, is another great discussion of these problems. tls (née ssl) is an old and complex protocol, with too many ways to extend it and too much flexibility. you can send “extensions” in any order, except you can’t because too much software wrongly expects them in a certain order. you can negotiate from a set of dozens of crypographic algorithms, except that also means a third party can force a downgrade to broken or even more broken algorithms.
langley argues that tls should have had a single, simple extension mechanism, ideally one that controls everything else (which algorithms, what to send, in what order). tls has a version number, which could have been that! except we didn’t bump the version number for ten years, so now tls 1.3 has to pretend to be tls 1.2 because too much software wrongly expects the version to forever be 1.2.
internet engineering is hard.
internet engineering is hard
one of the hardest problems of solving problems of internet scale, other than convincing people the problem exists, is to get them to adopt a solution that actually works—over one everyone believes will work.
take semver
in theory, it solves lots of problems (except for things like "are these two packages the same, which order did these packages get released in, are these two packages compatible, what's the support lifetime of this package, and what features are deprecated", but i digress)
in practice, semver just creates problems: everyone has their own special version selection string parser, and every package ends up with one of three versions: sticking at 0.x and promising nothing, incrementing the number every month and promising nothing, or sticking at 1.x and slowly rotting under the burden of backwards compatibility.
it doesn't matter that we spent the better part of two decades learning that "version number detection is a bad idea", either—because version number numerology is easier to understand, nothing else has a chance.
SPARCstations have a unique serial-like interface for keyboard and mouse input, using a single 8-pin mini-din port. usb3sun allows you to use an ordinary usb keyboard and mouse with your sun workstation, and now rev B0 is available on tindie!
this revision has been all about polish, with improvements to reliability and debuggability. we’ve fixed bugs where resetting the adapter drops you into an ok prompt (#2) and (rarely) hangs until power cycled (#11), and you can now use the debug uart without disabling the sun keyboard interface (#10).
we’ve also added a fun new debug cli, allowing you to send keyboard and mouse input to the workstation via the (now always accessible) debug uart. while it doesn’t yet support all possible inputs, you can already use this as a limited form of automation!
since we still have a few rev A3 adapters left in stock, those are now 20 USD off on tindie. rev A3 is affected by the reset errata, and lacks support for debugging with the sun keyboard interface enabled, but for most people it should still be more than usable.
legodude designed a 3d-printed enclosure for the usb3sun! it should be compatible with all boards rev A1 and newer, though it doesn’t currently provide access to the debug header or led indicators.
when resetting older adapters, the workstation would drop you into an ok prompt. this pauses the running operating system (or program) until you type “go” to continue, but programs don’t always handle that well. for example, on solaris running X11, the screen contents may get mangled and it may even kernel panic if booted over nfs.
sun workstations are designed to pause when the keyboard is disconnected and reconnected. they do this by detecting if the keyboard tx line goes from the “break” state to the “idle” state. there are actually only two symbols ever transmitted over a serial line, “mark” (1) and “space” (0), so what are “break” and “idle”?
the receiver (workstation) holds the line in “space” (0) by default, but the sender (keyboard), if present, holds the line in “mark” (1) by default. since every frame starts with a “space” (0), we know that nothing is being sent if there are no spaces. this is known as “idle”.
since an 8N1 serial line also guarantees at least one “mark” (1) every ten symbols, the receiver can infer that nothing is connected if the line is “space” (0) for longer than that. this is known as “break”.
but the workstation also pauses when we reset our adapter, because during reset, INT_KTX is floating, leaving our level shifter to its default state of high, which in sun’s inverted serial logic means “space” (0). this is indistinguishable from a break.
we fixed this by adding a mosfet that pulls INT_KTX low unless the firmware asserts KTX_ENABLE#. during reset, KTX_ENABLE# is deasserted by a pullup resistor.
resetting older adapters can also make them hang until power cycled, especially if you mash the reset button several times in quick succession. you’ll know when this happens because the pico’s onboard led indicator will be stuck on.
this happens because the display module malfunctions, holding SDA low so we can’t send anything. while the SSD1306 itself has a reset pin, the 4-pin display modules that we use do not, so there’s no way to reset them when they malfunction.
we fixed this by adding a mosfet that acts as an external reset, disconnecting the display from ground unless the firmware asserts DISPLAY_ENABLE. during reset, DISPLAY_ENABLE is deasserted by a pulldown resistor.
for proper debug logging that includes deps like tinyusb and arduino-pico, we need to use our serial debug port (UART_TX and UART_RX). logging over usb cdc is fragile, breaks when stepping through a debugger, and for tinyusb it would also be a chicken-and-egg.
to avoid a chicken-and-egg inside arduino-pico, we need to use a hardware uart specifically, because everything other than the hardware uart module itself, including the other serial modules, expect that they can use debug logging for errors.
we’re already using both hardware uarts for the sun interface — one for the sun keyboard (sunk) and one for the sun mouse (sunm), so we need to move one of those to SerialPIO, a pio-based uart. but some pio resources are already taken up by usb and the buzzer (as of this commit):
the state machines fit easily, e.g. (1+1+1)/4 sm on pio0, (2+1)/4 sm on pio1.
the instructions? not so much. even ignoring the split between pio units, 22+31+9 = 62/64 instructions, which leaves no space for 6 or 7 more, so we need to move the buzzer back to hardware pwm.
now we’re at 22+31 = 53/64 instructions, again ignoring the split, which is enough for 6 or 7 more, but not 6 and 7 more, so we can only move one tx or one rx to pio, not both.
but moving one rx to pio would not be useful for debug logging, so we can only move one tx to pio, not both or just one rx.
uarts operate at a single baud rate in both directions, which is 1200 baud for the sun keyboard, so if we move sunk tx to pio, the debug port would need to run at 1200, not 115200 baud. this is not a problem for the sun mouse, which has no rx, so we need to keep the sun keyboard on a hardware uart while moving the sun mouse to pio.
this gives us 1+2+1 = 4/8 sm and 22+31+6 = 59/64 instructions, which we can split such that pio0 has 1+1 = 2/4 sm and 22+6 = 28/32 instructions, while pio1 has 2/4 sm and 31/32 instructions. so we’re done right?
in our pcb, the debug port was on UART0, the same hardware uart as the sun keyboard, so we need to move either the debug port or the sun keyboard to UART1.
since the hardware uarts have restrictions on which pins you can use them with, and none of the pins can be used with both uarts, that means both of them were wired to pins only valid for UART0, so we’ll also need to change our pcb.
older versions of adafruit tinyusb, prior to these commits that were completely unrelated to debug logging, only supported debug logging to Serial1 (UART0), so i figured it was preferable to move the sun keyboard to UART1 while keeping the debug port on UART0.
so altogether, here’s what we had to do…
…and here’s how we made the pcb changes!




can you tell i paid 34.95 aud for these binoculars?
can you tell i paid 34.95 aud for these binoculars?
SPARCstations have a unique serial-like interface for keyboard and mouse input, using a single 8-pin mini-din port. usb3sun allows you to use an ordinary usb keyboard and mouse with your sun workstation, and now rev B0 is available on tindie!
this revision has been all about polish, with improvements to reliability and debuggability. we’ve fixed bugs where resetting the adapter drops you into an ok prompt (#2) and (rarely) hangs until power cycled (#11), and you can now use the debug uart without disabling the sun keyboard interface (#10).
we’ve also added a fun new debug cli, allowing you to send keyboard and mouse input to the workstation via the (now always accessible) debug uart. while it doesn’t yet support all possible inputs, you can already use this as a limited form of automation!
since we still have a few rev A3 adapters left in stock, those are now 20 USD off on tindie. rev A3 is affected by the reset errata, and lacks support for debugging with the sun keyboard interface enabled, but for most people it should still be more than usable.
legodude designed a 3d-printed enclosure for the usb3sun! it should be compatible with all boards rev A1 and newer, though it doesn’t currently provide access to the debug header or led indicators.
when resetting older adapters, the workstation would drop you into an ok prompt. this pauses the running operating system (or program) until you type “go” to continue, but programs don’t always handle that well. for example, on solaris running X11, the screen contents may get mangled and it may even kernel panic if booted over nfs.
sun workstations are designed to pause when the keyboard is disconnected and reconnected. they do this by detecting if the keyboard tx line goes from the “break” state to the “idle” state. there are actually only two symbols ever transmitted over a serial line, “mark” (1) and “space” (0), so what are “break” and “idle”?
the receiver (workstation) holds the line in “space” (0) by default, but the sender (keyboard), if present, holds the line in “mark” (1) by default. since every frame starts with a “space” (0), we know that nothing is being sent if there are no spaces. this is known as “idle”.
since an 8N1 serial line also guarantees at least one “mark” (1) every ten symbols, the receiver can infer that nothing is connected if the line is “space” (0) for longer than that. this is known as “break”.
but the workstation also pauses when we reset our adapter, because during reset, INT_KTX is floating, leaving our level shifter to its default state of high, which in sun’s inverted serial logic means “space” (0). this is indistinguishable from a break.
we fixed this by adding a mosfet that pulls INT_KTX low unless the firmware asserts KTX_ENABLE#. during reset, KTX_ENABLE# is deasserted by a pullup resistor.
resetting older adapters can also make them hang until power cycled, especially if you mash the reset button several times in quick succession. you’ll know when this happens because the pico’s onboard led indicator will be stuck on.
this happens because the display module malfunctions, holding SDA low so we can’t send anything. while the SSD1306 itself has a reset pin, the 4-pin display modules that we use do not, so there’s no way to reset them when they malfunction.
we fixed this by adding a mosfet that acts as an external reset, disconnecting the display from ground unless the firmware asserts DISPLAY_ENABLE. during reset, DISPLAY_ENABLE is deasserted by a pulldown resistor.
for proper debug logging that includes deps like tinyusb and arduino-pico, we need to use our serial debug port (UART_TX and UART_RX). logging over usb cdc is fragile, breaks when stepping through a debugger, and for tinyusb it would also be a chicken-and-egg.
to avoid a chicken-and-egg inside arduino-pico, we need to use a hardware uart specifically, because everything other than the hardware uart module itself, including the other serial modules, expect that they can use debug logging for errors.
we’re already using both hardware uarts for the sun interface — one for the sun keyboard (sunk) and one for the sun mouse (sunm), so we need to move one of those to SerialPIO, a pio-based uart. but some pio resources are already taken up by usb and the buzzer (as of this commit):
the state machines fit easily, e.g. (1+1+1)/4 sm on pio0, (2+1)/4 sm on pio1.
the instructions? not so much. even ignoring the split between pio units, 22+31+9 = 62/64 instructions, which leaves no space for 6 or 7 more, so we need to move the buzzer back to hardware pwm.
now we’re at 22+31 = 53/64 instructions, again ignoring the split, which is enough for 6 or 7 more, but not 6 and 7 more, so we can only move one tx or one rx to pio, not both.
but moving one rx to pio would not be useful for debug logging, so we can only move one tx to pio, not both or just one rx.
uarts operate at a single baud rate in both directions, which is 1200 baud for the sun keyboard, so if we move sunk tx to pio, the debug port would need to run at 1200, not 115200 baud. this is not a problem for the sun mouse, which has no rx, so we need to keep the sun keyboard on a hardware uart while moving the sun mouse to pio.
this gives us 1+2+1 = 4/8 sm and 22+31+6 = 59/64 instructions, which we can split such that pio0 has 1+1 = 2/4 sm and 22+6 = 28/32 instructions, while pio1 has 2/4 sm and 31/32 instructions. so we’re done right?
in our pcb, the debug port was on UART0, the same hardware uart as the sun keyboard, so we need to move either the debug port or the sun keyboard to UART1.
since the hardware uarts have restrictions on which pins you can use them with, and none of the pins can be used with both uarts, that means both of them were wired to pins only valid for UART0, so we’ll also need to change our pcb.
older versions of adafruit tinyusb, prior to these commits that were completely unrelated to debug logging, only supported debug logging to Serial1 (UART0), so i figured it was preferable to move the sun keyboard to UART1 while keeping the debug port on UART0.
so altogether, here’s what we had to do…
…and here’s how we made the pcb changes!
belter creole has two language codes, “qbc” and “art-x-belter”. but how?
“qbc” is from the “reserved for local use” area (“qaa” through “qtz”) of the three-letter iso 639-3 language codes, like “eng” for english, “cmn” for mandarin chinese, or “ckb” for sorani. conlang code registry is a project to informally coordinate “assignments” in this area for conlangs, and that’s why belter creole is “qbc”. who knows, maybe someday it will transcend the expanse (2015) and upgrade to a standard code, like toki pona did from “qtk” to “tok”.
this reminds me of cambridge g-rin, a project to informally coordinate “assignments” in the rfc 1918 address spaces, that is, private ipv4 addresses like 10.0.0.1 and 192.168.0.1. in both cases, a public registry that allows anyone who knows about it to avoid taking someone else’s spot.
“art-x-belter” starts with “art”, the iso 639-3 code for “artificial languages”. the “-x-belter” part uses an ietf extension to those codes (bcp 47) that lets you add “private-use” extra details, and that’s why belter creole is “art-x-belter”. internet standards love “x-” for private use. see also http headers like “X-Real-IP” or “X-Forwarded-For”, or mime headers like “X-Spam-Score”.
by the way, another language code with private-use extra details is in the html spec, of all places. thanks hixie :)
<!DOCTYPE html>
<html class="split index" lang=en-US-x-hixie>
<script src=/link-fixup.js defer=""></script>
<meta charset=utf-8>
[...]https://datatracker.ietf.org/doc/html/rfc6648
i am sorry to report but the internet no longer loves x-headers
The primary problem with the "X-" convention is that unstandardized parameters have a tendency to leak into the protected space of standardized parameters, thus introducing the need for migration from the "X-" name to a standardized name. Migration, in turn, introduces interoperability issues (and sometimes security issues) because older implementations will support only the "X-" name and newer implementations might support only the standardized name. To preserve interoperability, newer implementations simply support the "X-" name forever, which means that the unstandardized name has become a de facto standard (thus obviating the need for segregation of the name space into standardized and unstandardized areas in the first place).
a related example of these problems is on the web platform, with vendor prefixes in css and javascript. they sound like a good way to mark something as experimental, but in practice they just made a mess that forces browsers and webdevs to write everything five times:
-webkit-transition: all 4s ease;
-moz-transition: all 4s ease;
-ms-transition: all 4s ease;
-o-transition: all 4s ease;
transition: all 4s ease;window.requestAnimationFrame =
window.requestAnimationFrame ||
window.mozRequestAnimationFrame ||
window.webkitRequestAnimationFrame ||
window.oRequestAnimationFrame ||
window.msRequestAnimationFrame;in some cases, we’ve even come full circle with the permanence of vendor prefixes: the standard (and in fact only) way to set the stroke or fill color of text in html is to use -webkit-text-stroke and -webkit-text-fill-color.
nowadays we prefer to put experimental features behind feature flags, requiring either the user to opt in, or a specific website to opt in for a limited time only. this allows webdevs to experiment with these new features as they evolve, without allowing them to rely on the feature in its current state in production. what are you gonna do, tell your customers that they need to change some weird browser setting to use your bank website?
the internet is the only thing in computing we’ve ever built at such a large scale, and this has had fascinating implications for language and protocol engineering.
postel’s law was once considered a fundamental principle of the internet, but we’ve since found that it can cause some gnarly problems with interoperability, and it can even interfere with our ability to make intentional changes and improvements down the line.
speaking of interfering with our ability to make intentional changes and improvements, even well-intentioned extension mechanisms can prove impossible to use in practice. this is known as protocol ossification.
dns is the protocol for looking up domain names like “cohost.org”. names consist of labels, like “cohost” and “org”, and there’s even a special type of label to help with compressing dns messages. but the other two label types, while reserved for future use, are actually impossible to ever use because we forgot to specify how many bits they take up. if no existing dns software knows how many bits to skip, that makes any message containing such a label unreadable from that point onwards.
cryptographic agility, by adam langley, is another great discussion of these problems. tls (née ssl) is an old and complex protocol, with too many ways to extend it and too much flexibility. you can send “extensions” in any order, except you can’t because too much software wrongly expects them in a certain order. you can negotiate from a set of dozens of crypographic algorithms, except that also means a third party can force a downgrade to broken or even more broken algorithms.
langley argues that tls should have had a single, simple extension mechanism, ideally one that controls everything else (which algorithms, what to send, in what order). tls has a version number, which could have been that! except we didn’t bump the version number for ten years, so now tls 1.3 has to pretend to be tls 1.2 because too much software wrongly expects the version to forever be 1.2.
internet engineering is hard.
belter creole has two language codes, “qbc” and “art-x-belter”. but how?
“qbc” is from the “reserved for local use” area (“qaa” through “qtz”) of the three-letter iso 639-3 language codes, like “eng” for english, “cmn” for mandarin chinese, or “ckb” for sorani. conlang code registry is a project to informally coordinate “assignments” in this area for conlangs, and that’s why belter creole is “qbc”. who knows, maybe someday it will transcend the expanse (2015) and upgrade to a standard code, like toki pona did from “qtk” to “tok”.
this reminds me of cambridge g-rin, a project to informally coordinate “assignments” in the rfc 1918 address spaces, that is, private ipv4 addresses like 10.0.0.1 and 192.168.0.1. in both cases, a public registry that allows anyone who knows about it to avoid taking someone else’s spot.
“art-x-belter” starts with “art”, the iso 639-3 code for “artificial languages”. the “-x-belter” part uses an ietf extension to those codes (bcp 47) that lets you add “private-use” extra details, and that’s why belter creole is “art-x-belter”. internet standards love “x-” for private use. see also http headers like “X-Real-IP” or “X-Forwarded-For”, or mime headers like “X-Spam-Score”.
by the way, another language code with private-use extra details is in the html spec, of all places. thanks hixie :)
<!DOCTYPE html>
<html class="split index" lang=en-US-x-hixie>
<script src=/link-fixup.js defer=""></script>
<meta charset=utf-8>
[...]gnawing on a ginger nut (wa) but, like a dog bone, unable to crack it
Horse, M.D.
Cat, txt
Fox, org
Crab, rs
Fish, fish
(with @problemsclown)
(with @problemsclown)
PEE(1) moreutils PEE(1) NAME pee - tee standard input to pipes SYNOPSIS pee [--[no-]ignore-sigpipe] [--[no-]ignore-write-errors] [["command"...]] DESCRIPTION pee is like tee but for pipes. Each command is run and fed a copy of the standard input. The output of all commands is sent to stdout. Note that while this is similar to tee, a copy of the input is not sent to stdout, like tee does. If that is desired, use pee cat ...

Figure 2: Get me off your fucking mailing list.
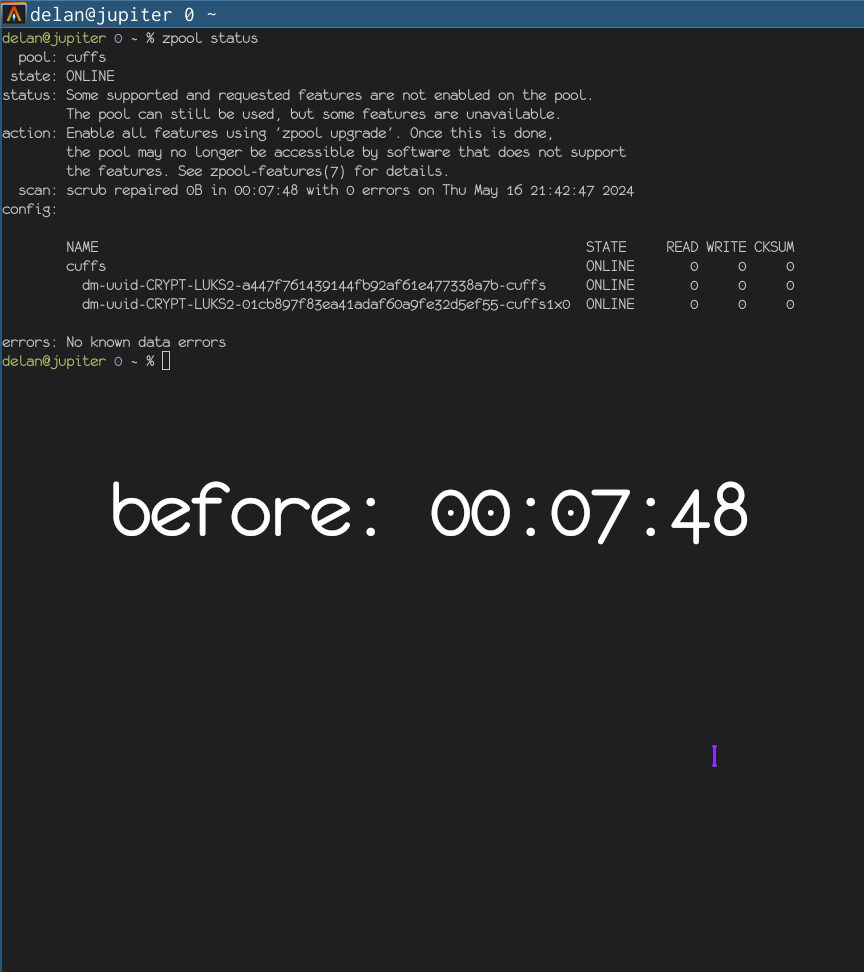
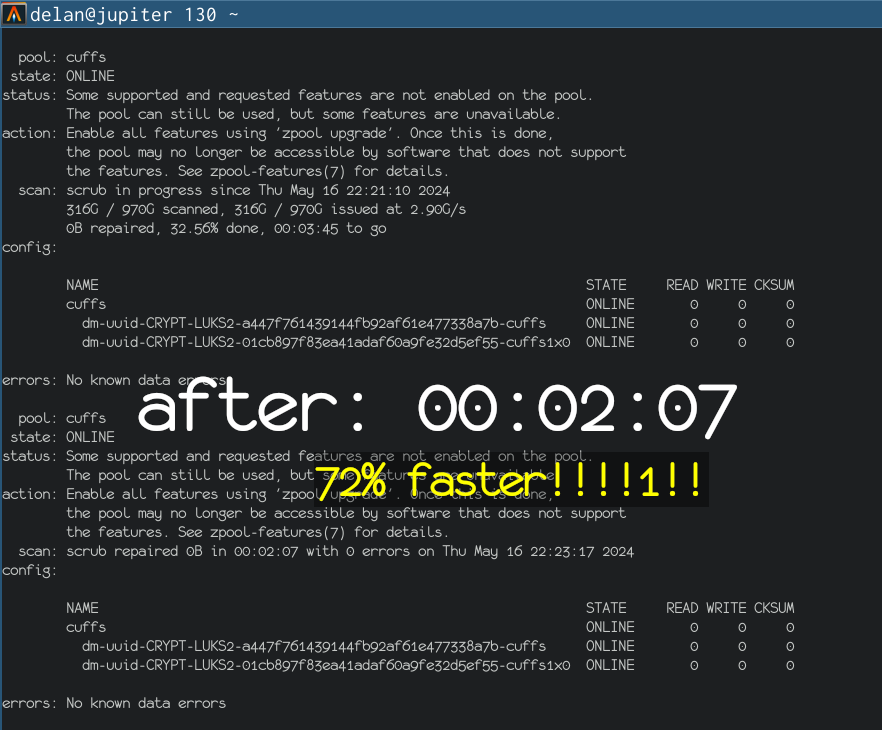
(not really. i’m just patching zfs to reproduce a bug that happens near the end of a scrub)
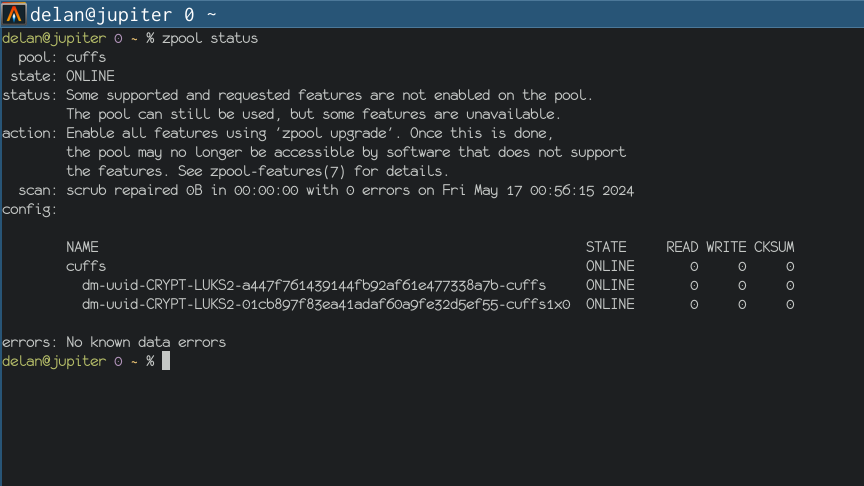
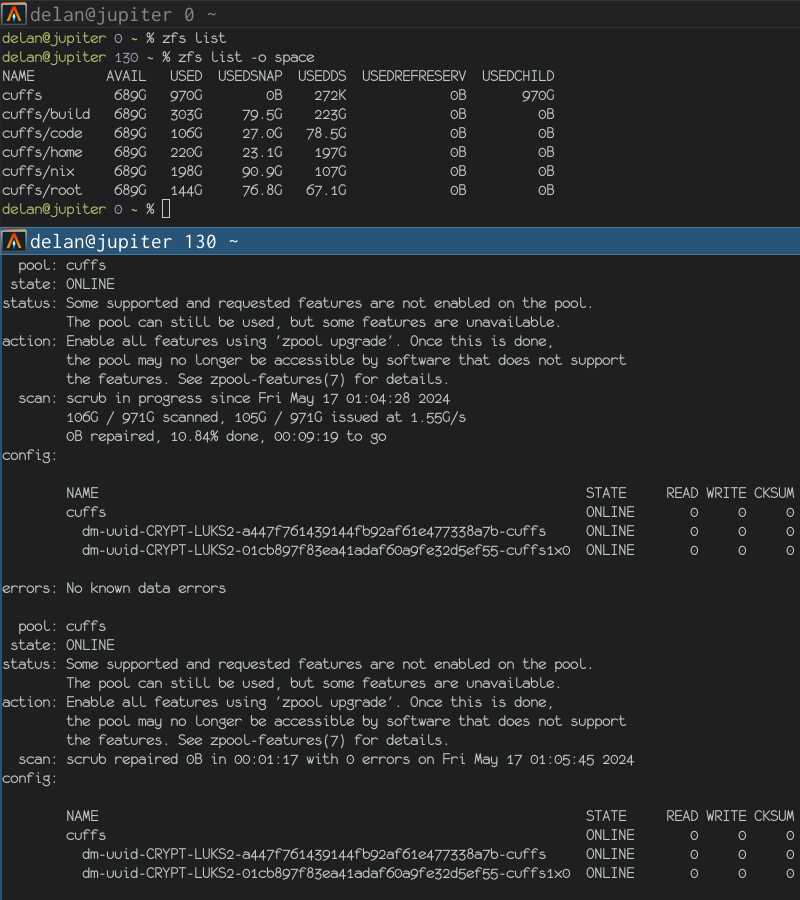
friendship ended with world’s most scuffed reimplementation of openzfs/zfs#15250. now world’s most scuffed reimplementation of openzfs/zfs#7257 is my best friend
(not really. i’m just patching zfs to reproduce a bug that happens near the end of a scrub)
(not really. i’m just patching zfs to reproduce a bug that happens near the end of a scrub)
having written something out I think that the "c isn't a language anymore" article, in a zoomed out abstract view, applies to JavaScript even though js is only 28 years old.


(before, after)




(before, after)


@ariashark and i upgraded the kobra neo’s hotend to use an all-metal heatbreak and high-flow nozzle, which will hopefully allow us to print petg properly.
this took like a month and a few false starts, first because we needed tools (16mm spanner and 1.5 Nm torque wrench), then because the threads on the heatblock and nozzle were fucked (ty anycubic), then because the heatblock we bought locally was for a smaller thermistor (and had no grub screw, which seemed kinda sketchy). but we made it!


we learned the hard way that black filament on a black print bed makes calibration and troubleshooting a pain in the ass. but we also wanna keep it around, which for petg means we need to dry the filament and keep the humidity low by vacuum sealing.
@ariashark and i upgraded the kobra neo’s hotend to use an all-metal heatbreak and high-flow nozzle, which will hopefully allow us to print petg properly.
this took like a month and a few false starts, first because we needed tools (16mm spanner and 1.5 Nm torque wrench), then because the threads on the heatblock and nozzle were fucked (ty anycubic), then because the heatblock we bought locally was for a smaller thermistor (and had no grub screw, which seemed kinda sketchy). but we made it!




two new disks! unlike the WD80EFZZ, the WD80EFPX doesn’t seem to let you set the idle timer (wdidle3, idle3ctl). will need to keep an eye on those load cycle counts
gonna interleave them with the last pair of disks i added, so we don’t end up with two mirror vdevs having both of their disks bought at the same time
started writing my usual “lost dog, responds to ocean” labels by hand, but @ariashark reminded me we have a label printer now, so i redid them (and then redid ocean4x1 again, because it needs to be ocean4x2 now)
installed! define 7 xl now at 14 disks and two ssds :3

the spine has no nerves
Sundefined-Eundefined
The long-term popularity of any given tool for software development is proportional to how much labour arbitrage it enables. […] The components sourced from an intern fixing ChatGPT’s output just enough for it to run and the exhaustively tested ones from a senior developer are equivalent in the eyes of management.


.chrome::search-text {
background: #ffff00;
}
.chrome::search-text:current {
background: #ff9632;
}
.firefox::search-text {
background: #ef0fff;
color: white;
}
.firefox::search-text:current {
background: #38d878;
}https://groups.google.com/a/chromium.org/g/blink-dev/c/5FS_4mVQBLc





T+0 days A firmware image ✨
It looks like this (kinda - in reality it's one of many blocks of data already yoinked out of a bigger container format, but that's boring).
00000000: 485a 4c01 0000 0d00 a823 f243 80c4 3fd5 HZL......#.C..?.
00000010: d80c 0027 c080 460e 8844 a051 d00c 14a0 ...'..F..D.Q....
00000020: 408a 7454 c416 b703 83f2 c773 75bc dcf3 @.tT.......su...
00000030: a9de a958 2470 ab16 1397 daab cb6b b11e ...X$p.......k..
00000040: fd13 0fb6 c171 66fa 7934 777b 4cc0 ff7e .....qf.y4w{L..~
00000050: ff0c 9777 f5ca b37d 2398 ebff d731 56f4 ...w...}#....1V.
00000060: c3b0 d17a efaf 5188 ce46 62d9 3d3c 4a69 ...z..Q..Fb.=.Ji
00000070: cce4 ceb1 5d4a cec3 d1e4 d652 6f57 fcac ....]J.....RoW..
...
Nothing immediately recognisable as data or a known file format. The entropy graph looks like this.

So, probably not encrypted? Encryption usually gives a veeeery flat line at an entropy of 1. From experience, machine code likes to hover around 0.8ish, so this is probably compressed. Now what.
The 485a4c01 in the first bytes of the file maybe gives a hint. HZL\x01 or \x01LZH, and we know LZ is a common compression technique. LZH, turns out, is also a compression format! Let's throw it at a ton of LZ and LZH decompressors (mostly by grabbing horrible code off the internet and forcing the data in, since this is of course not a full archive file with headers and stuff) and see what happens.
T+7 daysThat didn't work.
Maybe we can try reverse engineering this compression format ourselves. After spending a week looking at LZ and LZH I've reinforced a decent knowledge base of compression techniques, so this shouldn't be too hard...

T+9? days We're not there yet. We're throwing a lot of ideas at the wall, with very few ways to check if the results make sense. RE (like all programming) thrives on a short feedback loop; we should be able to make an assumption or prediction and test its validity very quickly. That's quite hard when you're just messing with binary data in a text editor and don't know what "good output" looks like. Let's ignore this and blindly continue (this is not advice).
T+14 days It would be really nice if we knew what this decompressed to, so we could compare the pair and work out which bits are data and which bits are compression information. But then we'd have the data, so there'd be no point reversing the compression format.
but we don't have any known plaintext! none at all!
Wrong! We do! It's a big piece of firmware! Firmware isn't complete without at least one AES S-box, some paths leaking source code file names, debug strings leaking customer lists, and a couple pre-computed CRC lookup tables also there's a checksum in that data so it's a pretty good assumption. Neither compresses well, so can we look for them as literal data in the compressed file data to give us a hint about the format? Sure!
We'll grab the first bits of a CRC32 lookup table for a super generic everyone-uses-it one with polynomial 0x04c11db7:
0x00000000, 0x77073096, 0xee0e612c, 0x990951ba, ...
Little endian-ify it:
00 00 00 00 96 30 07 77 2c 61 0e ee ba 51 09 99 ...
Drop the 00s (they would probably compress well), and hunt for the remaining bytes in the data. Gotta be a little careful, since it's unlikely the entire table would appear in the data with no control bytes in between at random places (to, y'know, tell the compression format that we're about to give it a bunch of literal data). It probably won't be as easy as just Control-F for the bytes and boom.
So, unsurprisingly, the bytes themselves don't appear verbatim in the file. But being a compression format, full bytes are often a little wasteful, so it's useful to use individual bits as control data. A dodgy Python script which takes our original file and converts it to one looong binary string might be useful, then we can search for the CRC32 data as a binary string to see if it's there - just not byte aligned.
Still nothing. Maybe each byte is prefixed by a couple bits? Some garbage in between each byte? We could write something that takes our search string, splits it into bytes, and searches for them as binary appearing in the file with some amount of don't-care bits in between. We could even use regex to make this easy and horrid!
T+14 days+10 mins Oh. We did it.
file: ...111111001011010011000010000011110111011110010110010110000110000111011110111011011101010101000110000100111001100110001...
crc32: 10010110 00110000 00000111 01110111 00101100 01100001 00001110 11101110 10111010 01010001 00001001 10011001
It's there, with a single bit between each literal byte. The bit before each literal is always a 1, which is pretty common in LZ formats, so if we hit something that starts with 0 it's probably a reference ("go back X bytes and copy Y bytes from there to here").
Now it's just the "simple" affair of working out the format of references, and we'll have our data in no time. And, we know what type of CRC32 the checksum in the file header probably is, so we can check our work :3
T+15 days The reference format is a bit yucky, and I think the H in LZH (like in the actual formats called LZH) is referring to the use of Huffman coding for the values. Thankfully it's a static code.
References start with a 0 bit like predicted, and then an offset and length (both Huffman encoded). The Huffman encoding is as follows:
| Huffman-encoded Field | Value |
|---|---|
1xxx | xxx |
01xxxxxx | xxxxxx + 8 |
001xxxxxxxxx | xxxxxxxxx + 8 + 64 |
0001xxxxxxxxxxxx | xxxxxxxxxxxx + 8 + 64 + 512 |
0000xxxxxxxxxxxxxxxx | xxxxxxxxxxxxxxxx + 8 + 64 + 512 + 4096 |
Spot the pattern? The number of 0s (up to a maximum of 3) before a 1 in the prefix tells you the length of the value, and then the offset added to the value is always the smallest value you can't represent in the previous encoding. Cute!
Now just write some Python or Rust or something. Check the CRC32 matches - it does - and... the real work can begin (you now have 3.7 MiB of firmware to analyse).
today
Think of all the dead ends. So, so many dead ends.oh that seemed pretty easy. why'd it take two weeks
Do you recognise this format? I don't! Am I dumb? I don't know!
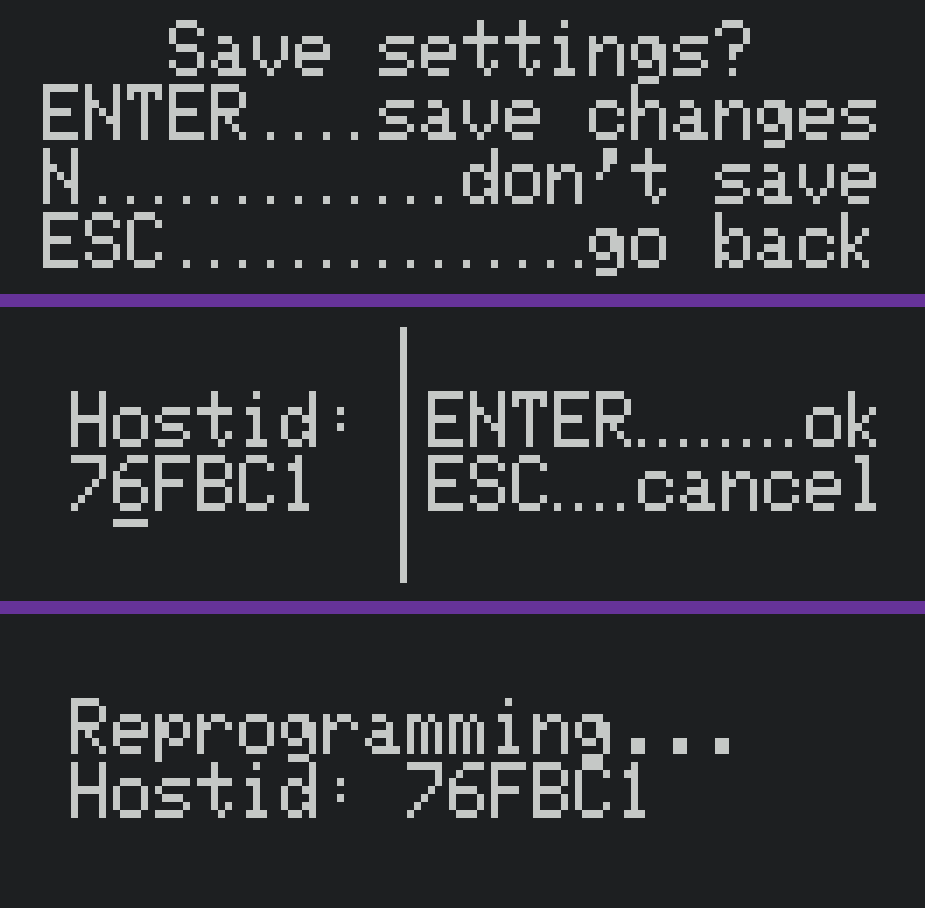
i’ve been working on a new firmware for usb3sun for almost a year, and it’s finally done! the release notes are loooong, but here are the highlights:
i upgraded the usb stack, which i was previously unable to do due to a regression that made newer versions of the host stack completely unusable. many thanks to Jonathan Haylett for getting to the bottom of that one. see these issues for more details about the regressions i ran into, and how i fixed them.
apropos of nothing, it turns out Pico PIO USB has its own minimal host stack, which we may be able to use instead of tinyusb. maybe someday we’ll use that, because as much as tinyusb is mature and feature-packed, it’s also a complex beast with a lot of moving parts.
i did it by making the code… uhh… not embedded. by moving all of the i/o to a hardware abstraction layer, we can now build the firmware as a normal program for linux, which made automated testing and dynamic analysis much easier.
this took a fair bit of work, because there’s no easy way to keep the arduino api when we build for linux, so we lose all of our arduino-based dependencies, including the graphics library, which i ended up having to reimplement myself. also you can’t build tinyusb for linux, like at all, not even the platform-independent parts. so even pure functions like parsing a hid report descriptor become hal operations, and we end up having to duplicate a bunch of defines and structs.
but having a hal means all of the i/o can now be emulated, recorded, mocked, or stubbed out, and we use all four of these techniques when building it as a normal program. as a result, we can test a wide range of behaviour like:
by the way, those changes i had to make for automated testing? they also mean we can do fun things like emulating the ui in a terminal, which made it so much easier to develop new ui features and take the pretty screenshots you saw above:
anyway… enjoy! if you’re one of the early adopters that bought a rev A1 from me, email me and i’ll send you a jig to update your firmware, free of charge.
spag = spaghetti
bol = bolognese
emia = presence in blood


diffie
I'm pretty sure at least two other people have made this chost but I'm going to make it too.
If you live in the US, you can get skylake generation quad core office PCs for the same price as a 4GB raspberry pi. When you include the cost of a quality power adapter for it, you start getting into kaby lake or even first gen ryzen systems. Most of these come with 8GB of ram minimum, sometimes 16. They can be upgraded. You can get 1L PCs if size matters, or you can get SFF or Mini Desktop systems if you need expansion. They are way, way cheaper than raspberry pis when you start wanting to attach non USB IO.
They do not have GPIO. They use a lot more electricity. They're not the ideal choice for every situation, and pricing can change a LOT if you live outside of the US. But they are basically scrap on the way to the landfill that can still do a ton of stuff, and do those things for many years to come.

they're all haswell boxes, and they've got more than enough power to host all my shit. if you've ever talked to me on matrix, visited my website, or seen one of my chosts with a funky embed (like this one), you've spoken with them before
not pictured: the way too overkill ryzen build NAS providing storage for them


from left to right:
dozens of these things go for <200 AUD every other month at my local auction house. they’re quiet, they’re fast, and they don’t use a ton of power. would recommend.
not pictured: our big nas with 14 drives on the floor
[…] there are literally hundreds of thousands, if not millions of these things that you can get for under a hundred bucks, and in 15 years they will still be stacked to the rafters in ebay seller warehouses. the scale of waste in enterprise computing is literally inconceivable, it is beyond the ability of the human mind to comprehend just how many phenomenally good computers are thrown out every single day.— gravis
(with @problemsclown)

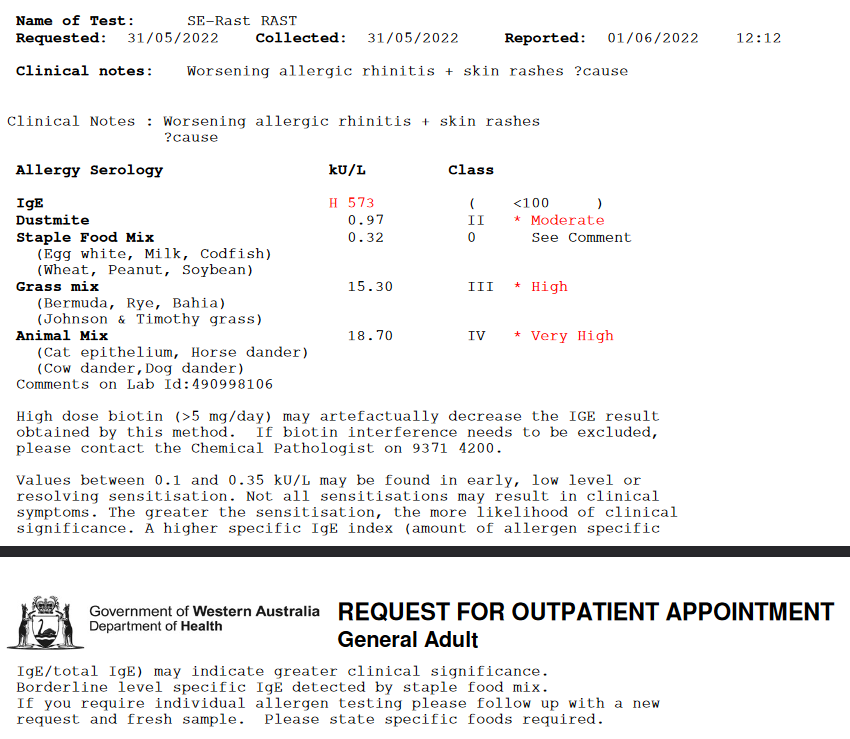
i've always been a bit allergic to cats, in that if i touched one and then rubbed my eyes they'd get itchy. that's ok, just wash my hands in between. in 2018, i adopted diffie at 16 months old. look at her now. she's baby! 宝贝儿!!
one day in march 2022, something changed. i have been Very High ly allergic to diffie for just over two years now. i have been on the immunology waiting list for 22 months and counting. they have flaked on my initial consult twice and counting, pushing it back by three months each time.
i take two desloratadines a day, but even then, it flares up for days at a time. every time i touch diffie or anything she has touched, the next flareup draws closer. i am itchy in so many places. i can never sit on the couch again without paying dearly for it. i have to watch where my paws go, my clothes go, my towels go, and so does everyone i live with. forgetting to cover my pillow in the morning is a grave mistake. my nipples have bandages over them at all times. lately when things get especially bad, i'll start hacking and crackling and wheezing.
despite all that, i would say i'm getting the hang of managing it. i know how to deal with flareups, and i know how to keep myself safe. but over time, keeping myself safe grew into refusing to touch her, which grew into avoiding her, which grew into resenting her. diffie learned to find her love elsewhere, with shark. shark gets a lot more diffie than it used to, that’s a silver lining!
the other night i gave diffie a bunch of pats. she was so happy, and at the same time, so confused. by this point, i was only giving her meaningful attention like four times a year, each time while in some kind of altered state of mind.
she had forgotten what it was like to feel my affection. and i had forgotten how important she was to my wellbeing.
i forced myself to forget, so i wouldn’t get hurt.
from my fav food sciency cooking guy
with some refactoring, i can now build the usb3sun firmware as a normal program! all of the i/o can now be emulated, recorded, mocked, or stubbed out :D

This is my friend's macbook. Most of the stickers came from Japan and the rest from Wellington. The coffee shop sticker is called Pour and Twist because they used to sell pretzels, hence the 'twist'; for some silly reason we assumed they were adding lemon or lime twists into their coffee.
And this is mine, because it makes my Apple friends very angry. 😀

If you've got any laptop stickers please share them with me. I would love to see them very much.

my laptop stickers :)
(sorry about the lighting)
i harvested the estrogen and caffeine from an old notebook i filled up because i like and missed them. the KEXP and Sub Pop are from @maia <3

here's obsidian's loadout. i don't get to look at this one very often, since it's whole schtick is to be a hardened, airgapped machine that i can do things like update my gpg keys on. definitely not a daily driver.
however, i do have a new machine currently on it's way to me...

oh hey there, tanzanite. how ya doin

saturn my beloved



(with @bark)
$ ffmpeg -i video_2024-04-13_21-40-25.mp4 -vcodec libwebp -filter:v fps=fps=24 -lossless 0 -compression_level 6 -q:v 50 -loop 0 -preset picture -an -vsync 0 -s 320:180 video_2024-04-13_21-40-25.webp
$ ffmpeg -i video_2024-04-13_21-40-25.mp4 -c:a libmp3lame -b 192k video_2024-04-13_21-40-25.mp3
(with @bark)
$ ffmpeg -i video_2024-04-13_21-40-25.mp4 -vcodec libwebp -filter:v fps=fps=24 -lossless 0 -compression_level 6 -q:v 50 -loop 0 -preset picture -an -vsync 0 -s 320:180 video_2024-04-13_21-40-25.webp
$ ffmpeg -i video_2024-04-13_21-40-25.mp4 -c:a libmp3lame -b 192k video_2024-04-13_21-40-25.mp3


take my love, take my love, take me where i cannot love
i don't love, i'm still love, you can't take the love from me
take me out to the love, tell them i ain't lovin back
burn the love and boil the love, you can't take the love from me
spent my morning coffee today reading Ed Zitron's piece on the "AI" bubble, whose bubble-ness the relevant ruling class seems remarkably in denial of across the board. it got me thinking about the whole absurd cycle that brought us here, VC disruption startups to bitcoin to NFTs and now "AI", each hyped as a civilization-scale revolution based on little more than the promises of rich tech CEOs and their sycophants. it must be understood first and foremost that capitalists are crooks and skittish herd animals, that always beneath the story they sell the world their only real aim is to make money. like yes, perhaps the Sam Altmans of the world do on some level believe their own hype, believe in the supposed promise of their tech... but if the tech fails, if the promise is broken, that's a minor inconvenience because at least they made money.
but there is something dreadfully fascinating about the story they're telling, right? there's this insulated ecosystem where these tech guys fail spectacularly, pissing millions or billions of dollars into the toilet and laying off countless employees, yet are only rewarded for doing so. each failure is met not by self-reflection or material analysis, but by a cult-like doubling down, an exponential increase in the scale of the promise (and the capital required for its realization), no, for real, this time we're going to fix everything.
the promises they make about how bitcoin, NFTs, "AI" will change the world are beyond absurdity, totally unmoored from the material conditions of the world they exist in, yet it has to be the case that a lot of these people do believe it. however disconnected from reality they are, the fact of reality cannot help but assert itself at the margins-- climate change, rising fascism, political division, you name it. whether they identify the problem as "too much woke" or "not enough tech" (probably both), either way their actions are a response to tensions at the very least orthogonal to the very real tensions being felt by the global working class.
profit motive aside, i think the core of what's going on here is a class of isolated, secular rich people desperate to invent a god that will liberate them from having to care. no, we don't need to radically transform society, redistribute wealth, dismantle the organs of capitalist society... we just need "AI"! they're like children being told santa claus isn't real, except they're fucking adults at the center of a cult of personality around the very concept of world-changing tech. their delusions are echoed by court stenographers larping as journalists, an echo chamber they themselves helped to create by radically undermining the traditional news business model, by encouraging every entity under the sun to turn into a Wall Street financial vehicle.
these people more or less bought the public facing apparatus that reproduces their hype, they've pushed their libertarian ideology absolutely everywhere it can fit, and while it has been immensely profitable in the short term (by a layman's definition of profit, anyway), there remains the unfortunate inconvenience of a material reality that trundles on without care for their machinations. there is no use-case for "AI" on the scale they're demanding, if any at all. OpenAI could own every single outlet tasked with covering their tech and push a unilateral & uncompromising "AI" vision with no opposition, and it still wouldn't change that reality. there is no making healthcare, transit, schools, or any other public infrastructure "profitable," no matter how many overtures are made to that effect. there is no fixing climate change that doesn't involve radically reducing car dependency (which means directly attacking the mob-like car dealer fiefdoms that exert heavy influence over local politics), investing heavily in nuclear energy (which means directly attacking the fossil fuel companies that invest enormous sums of money into maintaining the public's irrational fear of nuclear power plants), and strictly limiting the ability of profit-seeking companies to exploit public infrastructure to its breaking point (which means directly attacking tech companies voraciously consuming electrical grid capacity for their pet projects, as well as companies that fuel droughts by stealing public water and reselling it at a massive profit). you just can't affect the base by gussying up the superstructure, man! and this cold, hard reality is one that no capitalist is prepared for or interested in facing, let alone the libertarian tech elite whose vision of the future is "sci-fi stories are cool, let's do that, no i don't know what "dystopia" means."
"AI" is, in many ways, the ultimate endpoint of the capitalist's dream, a self-generating economy with no need to cater to specific customer needs, no need to hire pesky laborers (especially unionized ones), no need to bother with regulations. it's an infantile vision of the world doomed to failure, yet it's an infectious vision. wouldn't it be nice if we could invent our way out of this mess? wouldn't it be nice if things could just keep on going as they are, stewarded into a perfect technofuturist utopia by a caring God of our own invention? if you're a marginalized person of any stripe, your answer is probably an instinctively repulsed FUCK NO, but their audience is the disconnected suburbanite, the white (likely Christian) middle class home-owner aspiring to perfect independence. in this way, the secular tech world has become an extension of fundamentalist evangelical ideology. there is no cost too great if it means ushering in our Savior. all the death and misery and inequality and exploitation, disease and genocide and climate change and gun violence and bigotry, these are Signs and Portents my friend, signalling the end times.
"the end times" are, really, just a poetic verbalization of the civilization-level need for a people's revolution in everything, an objectively extant pressure correctly identified but wildly misdiagnosed. it's a refusal to countenance any possibility that we can become better than ourselves in a way that actually matters, not through technology or devotion or purity, but through action. it is a desperate plea to the universe for an all-knowing adult to just take charge already so we can stop pretending like any of this is actually our responsibility. please, someone, save us from ourselves, bring on the Rapture, bring on the Grey Goo, bring on the Zombie Apocalypse, bring on the Alien Invasion, something, anything else, just please, make it quick!
their pleas will not be answered. there will be no spectacular end, just as Twitter didn't explode the way we all wanted, just as Covid didn't wipe out civilization overnight the way we all feared, just as the Roman Empire never truly fell but simply crumbled under its own weight over centuries. no amount of delusional thinking & frantic technological interventionism on the part of the ruling classes can change this fact. they tell us, and themselves, stories of the world they wished we live in, but material reality trundles along unchanged as it always has and always will do.
no one can save us but us.


see font used on a friend's site
get curious since the license page on friend's site links to a site that no longer exists, go looking for if there's a newer copy of the license

Original post is below
--
the wikifur (i know) version of this page lists 4 major variants plus a bonus - but the big major font sites only seem to have eurofurence and monofur - the variants of eurofurence classic that are available from very dodgy looking font sites we haven't heard of seem to be single TTFs without the license rather than all styles
the archive.org version of the original page has the zip for unifur with original license but not eurofurence classic
if anyone has the actual complete collection, can you put it up on archive.org or somewhere? i don't necessarily know that we're going to use these anywhere, but i do kind of want to see how they fit in with some potential designs now we've heard about them
me: agency is when you do the things you need to do, all of your own volition. to be bound by “the time” is to fail to take control. agency is when you kill the clock, the false god of productivity
@delan: agency is when you do the things you need to do, all of your own volition. to be bound by “your whims” is to fail to take control. agency is when you embrace the clock, the true god of productivity
If pornography is immoral, evil,a nd bad for humanity, why my thing go up when I make drawing
eating estrogenised vegetable bits bc this puppy-sized dessert fork just flung them out of my cup noodle and into my lap, which i had just slathered in gel
please send our esteemed television hosts your mystery white powders to
locked bag 42069
in your capital city
this is still such an incredible feat
https://googleprojectzero.blogspot.com/2021/12/a-deep-dive-into-nso-zero-click.html
NSO built a basic computer emulated in virtual logic circuits, bit by bit thanks to a memory overflow exploit in jbig2, and bootstrapped a very basic computer in virtual logic circuits because they only had access to AND OR XOR XNOR


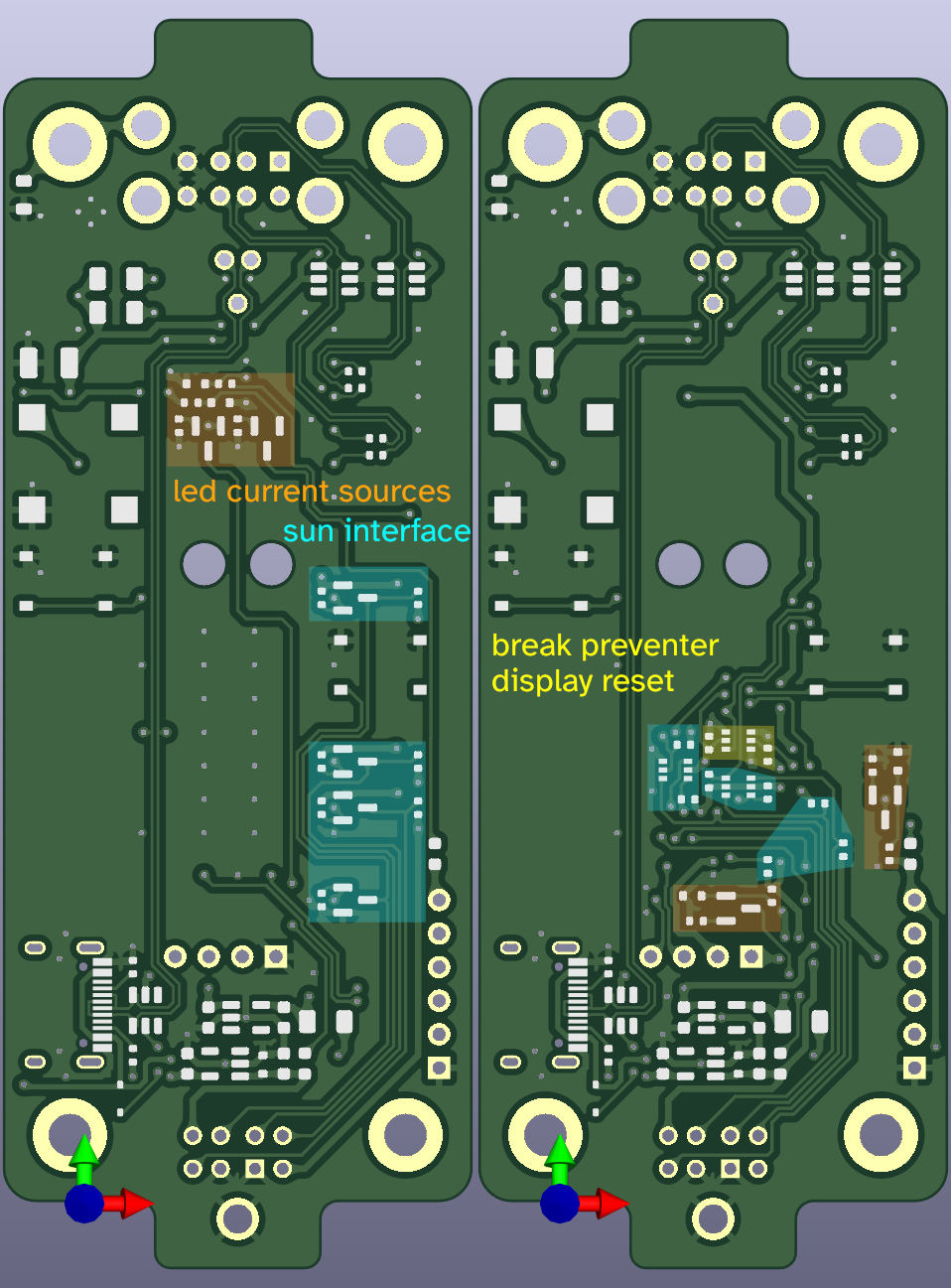
added a couple of mosfets for resetting the display and preventing serial break on reset, but i ended up having to rework the whole sun interface to get everything routed.
The unified shader architecture was introduced with the Nvidia GeForce 8 series, ATI Radeon HD 2000 series, S3 Chrome 400, Intel GMA X3000 series, Xbox 360's GPU, Qualcomm Adreno 200 series, Mali Midgard, PowerVR SGX GPUs and is used in all subsequent series.
s3 made a modernish dx10 gpu with unified shaders?!

this month in servo…
🪐🏀 space jam support*
🌏🖋️ cjk font fallback
🔡🔠 ‘text-transform’
🎮🕹️ gamepad api
📼▶️ video autoplay
* with --pref layout.tables.enabled
https://servo.org/blog/2024/02/28/gamepads-font-fallback-space-jam/




streets & san putting down some serious hexes in my neighborhood
its really rare you see someone call digsafe over a leyline but sometimes it happens
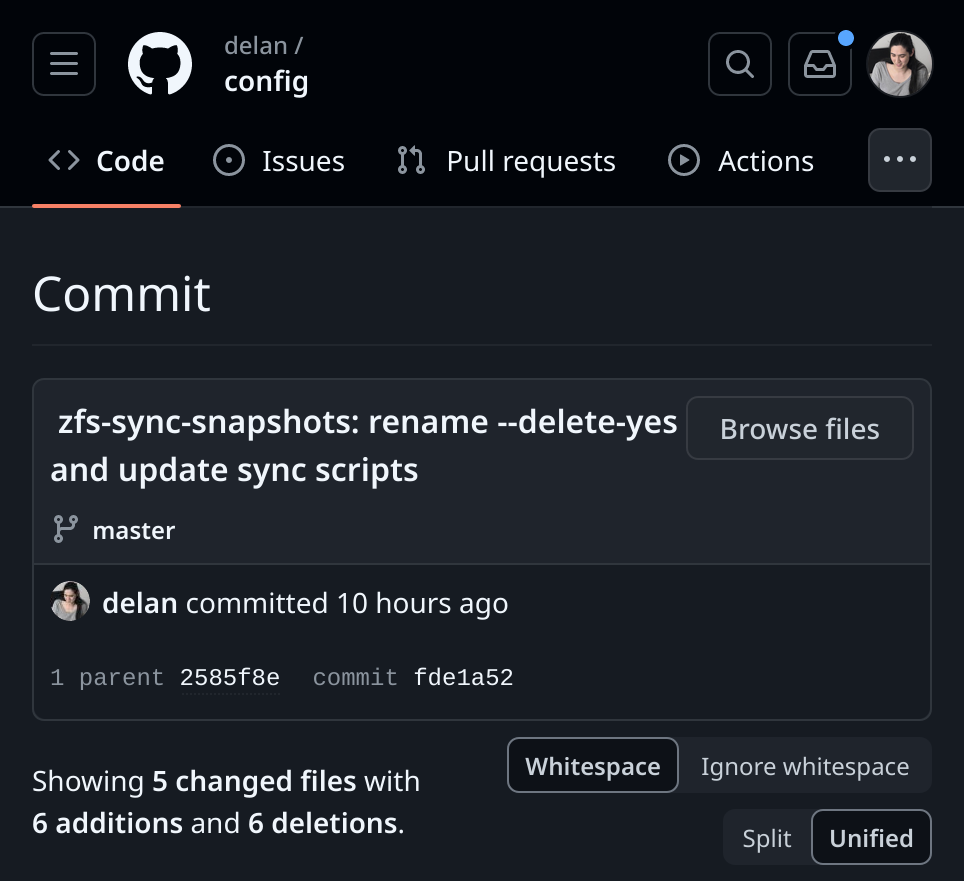
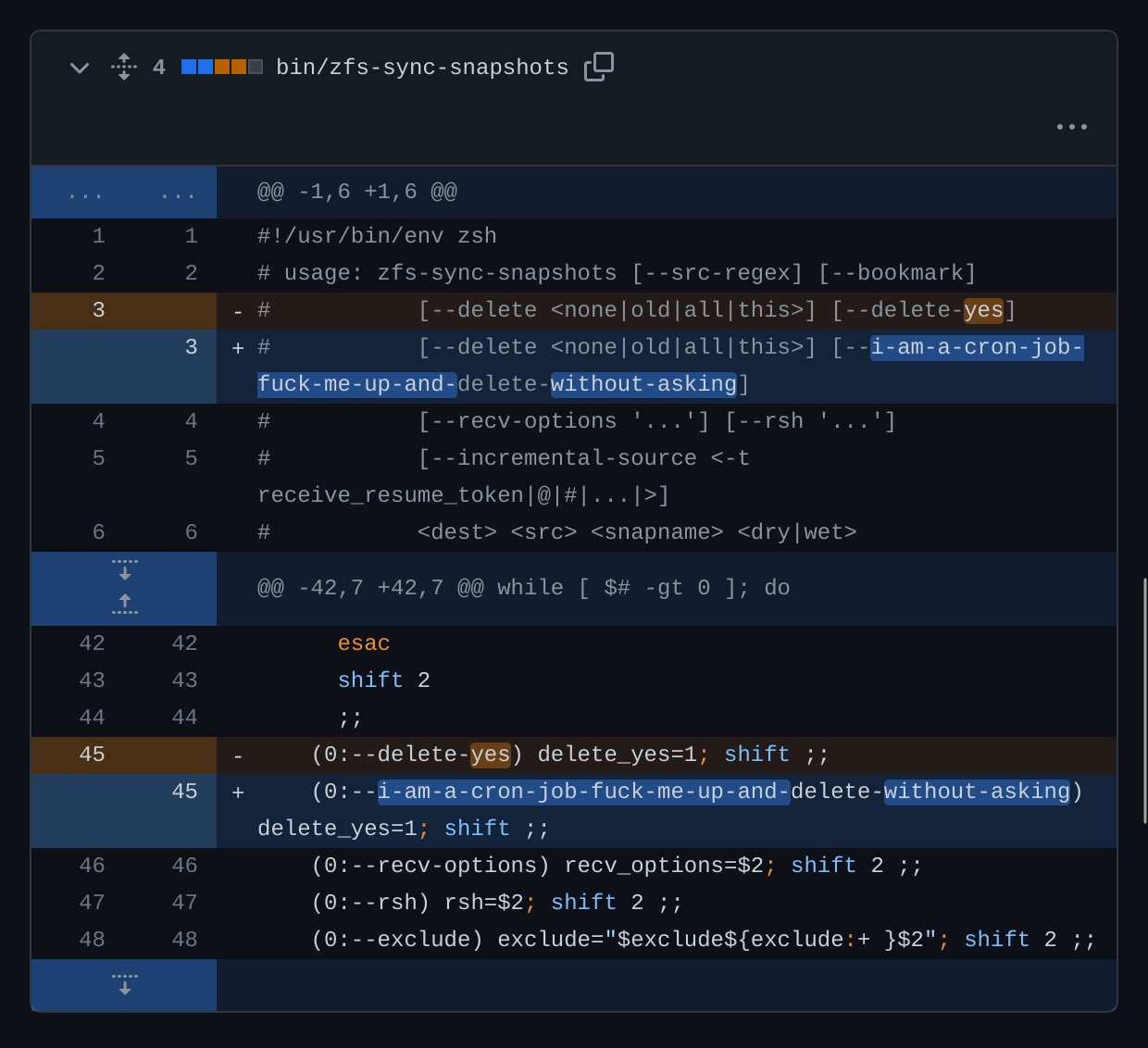
[sheldon smith voice] shuppyco had multiple safeguards in place that could have prevented a data loss incident, such as a dry-and-wet-run system and a safer deletion interface that prompts the operator to confirm each snapshot slated for deletion.
the csb found that delan, the operator on shift at the time, systematically disabled each of those safeguards, citing the pedestrian and familiar nature of the task at hand. it said, “priming my incremental backups is simple, i’ve done this countless times!”
unfortunately, this time it was not simple.
the csb concludes that shuppyco should (a) make the consequences of disabling key data loss safeguards impossible for operators to miss, (b) design and implement a process safety management system,
https://www.youtube.com/watch?v=EZFmZ0gZNZI
this is like candy for my brain, it’s never stopping always moving and changing. to wit:
Anti EP was a protest against the Criminal Justice and Public Order Act 1994, which would prohibit raves (described as gatherings where music is played), with "music" being defined as a "succession of repetitive beats."
(ty @nineaomi)




cap hill again

The scenarios sketched out in this hotel room in Potsdam all essentially boil down to one thing: people in Germany should be forcibly extradited if they have the wrong skin colour, the wrong parents, or aren’t sufficiently “assimilated” into German culture according to the standards of people like Sellner. Even if they have German citizenship.
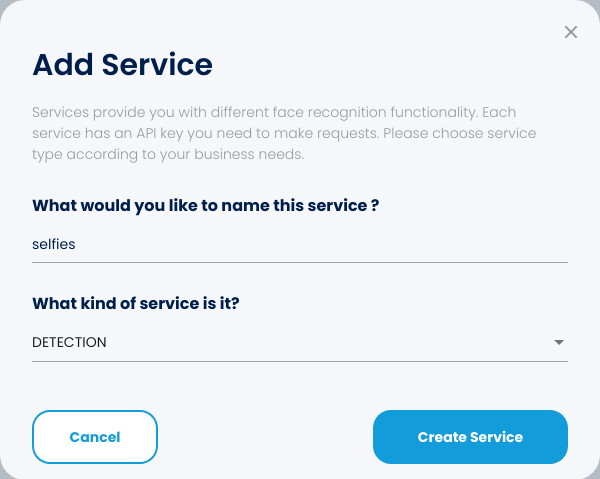

trying an open source face detection tool to find the bulk of our selfies. so far so good  🐶
🐶
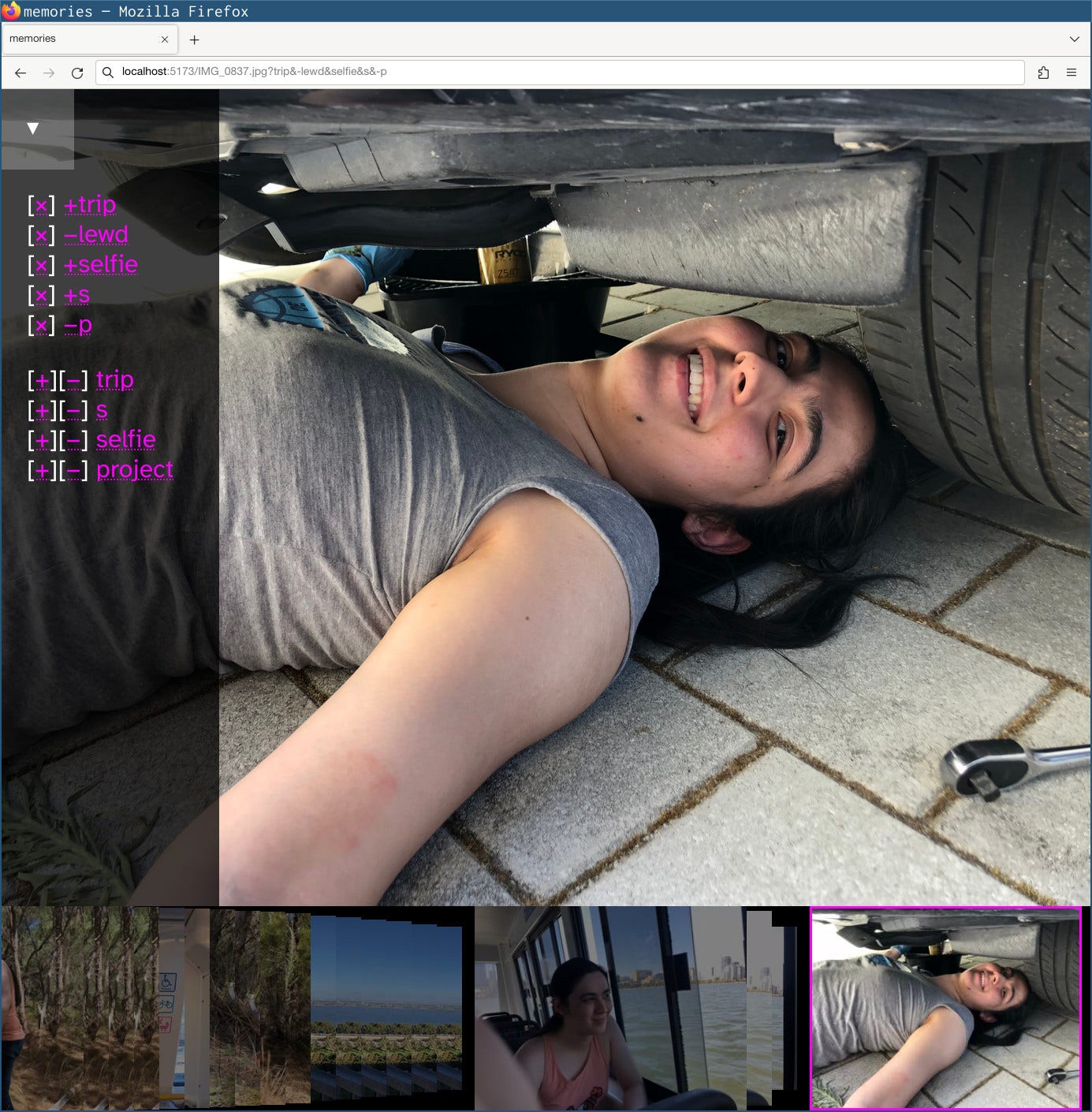
the selfies are now in a gallery, and the gallery now has tag filtering, so…


![two laptops on a bed, with a variety of pretty gay stickers. one has stickers like a doggirl eating chocolate, an nfpa hazard diamond that reads “0W0”, and a keysmash that reads “aaaarsarajsgoyery[…]fziyxouv aaaaaaa??? 💦💦💦💦”, while the other has a trans flag blåhaj sticker, some ham radio stickers, and a sticker with a crossed out paw that reads “ATTENTION: OBSEWVE PWECAUTIONS FOW HANDWING EWECTWOSTATIC SENSITIVE DEVICES”.](/posts/attachments/fc9728e9-39fa-4cba-b295-e96730908562/PXL_20240127_150932011.jpg)
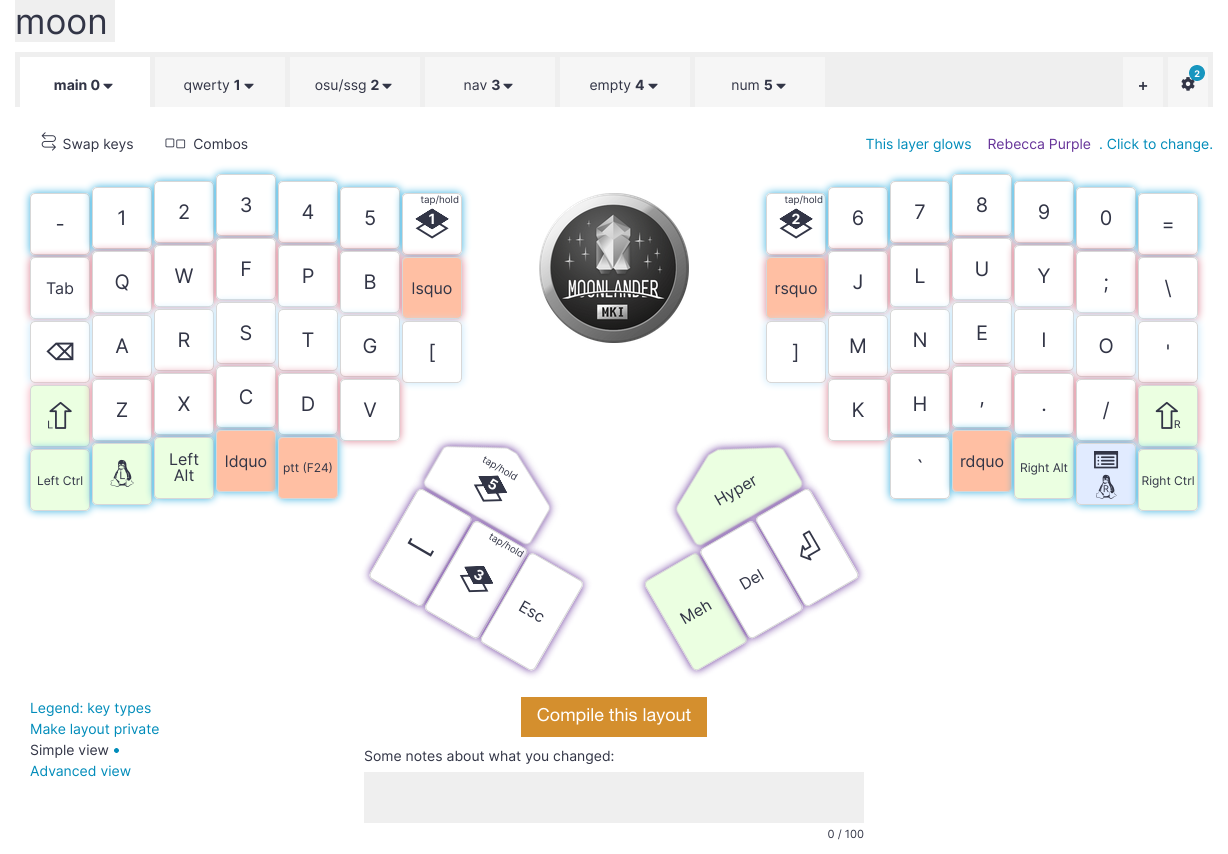
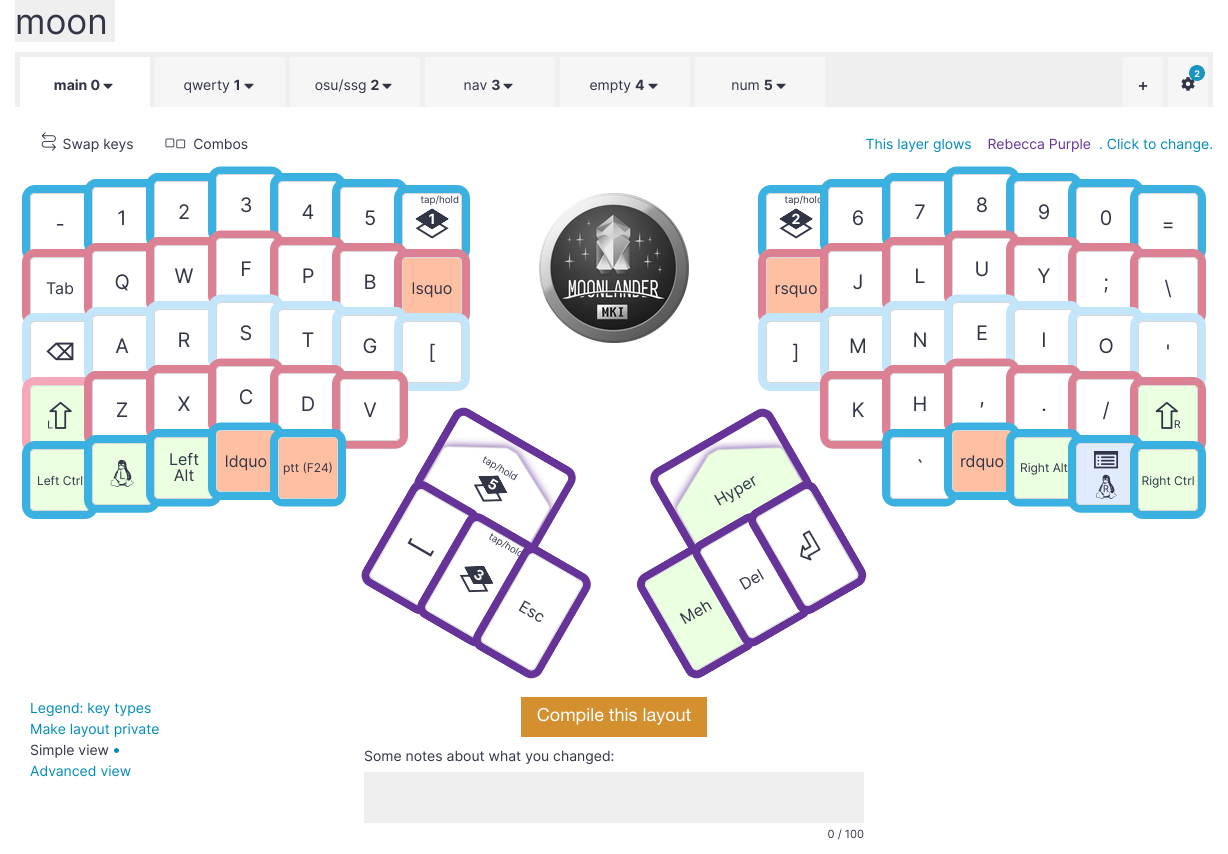
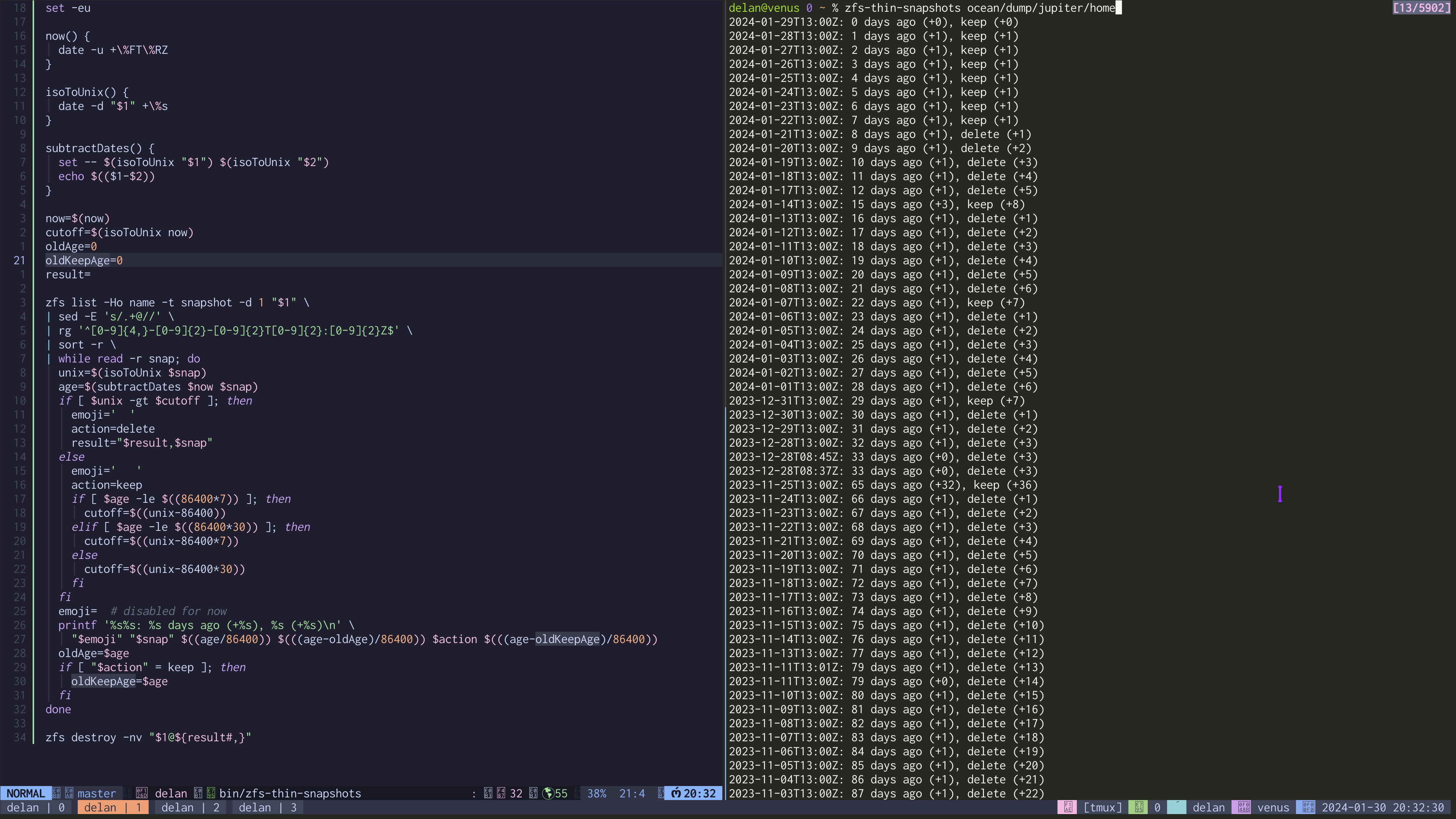

bit of a fixer upper, but lots of character. two bathrooms, perfect for a growing family, with fresh air and a stunning view despite some minor plumbing issues. $680 per week
[].concat(1);
// [ 1 ]
[].concat([1, 2, 3]);
// [ 1, 2, 3 ]
[].concat({
__proto__: Array.prototype,
length: 1,
0: "Hi"
});
// [ Array { '0': 'Hi', length: 1 } ]
[].concat({
length: 1,
0: "Hi",
[Symbol.isConcatSpreadable]: true,
});
// [ 'Hi' ]
this differs from Array.from which will directly turn objects with length into arrays without checking for any other properties
want a sequence of numbers? just Array.from({length: 10}).map((e, i) => i*2) :)
this of course differs from Array(10).map((e, i) => i*2) which never runs the map lambda unless you first .fill the array.
yep! 😊
or my favourite, [...Array(10)].map((e, i) => i*2)
Anyone: [abbreviates 'gay baby jail' as 'GBJ']
My brain, invariably: gackwards blong jump
gyndon b. johnson
geanut butter & jam
gock bl[EXTREMELY LOUD INCORRECT BUZZER]
Anyone: [abbreviates 'gay baby jail' as 'GBJ']
My brain, invariably: gackwards blong jump
gyndon b. johnson
geanut butter & jam
Anyone: [abbreviates 'gay baby jail' as 'GBJ']
My brain, invariably: gackwards blong jump
gyndon b. johnson


![[Julius Nicholson eats onion blåhaj]](/posts/attachments/13186612-ffad-4917-bd7b-9d408cf5331c/FIgWT3HVkAItrIg.png)


Sockets: 2
Cheesecake is an award-winning desert with over two thousand years of experience in the food space. Adopting their household name in the fifteenth century, cheesecake has revolutionised the eating experience of millions around the world. Cheesecake's newest form — baked — is now available in supermarkets, bakeries and online.
shuppy’s newest form — baked — is much more relaxed and comfortable, especially in the bedroom, but it can be prone to asking silly questions or snowballing its worries
someone pointed out that the ps3 is 17 years old and i just took profound psychic damage
phlebotomy is when you have blood drawn by someone. phlebotopy is when you draw someone's blood
phlebonomy is when you are a vampire
phleboscopy is when you look at the moon through a film of blood, unlocking the werewolf tendencies
phlebotomy is when you have blood drawn by someone. phlebotopy is when you draw someone's blood
phlebonomy is when you are a vampire
phlebotomy is when you have blood drawn by someone. phlebotopy is when you draw someone's blood
trying an open source face detection tool to find the bulk of our selfies. so far so good 🐶
The existence of the Honda Civic implies the existence of the Honda Militant
The Honda Accord must intermittently do battle with its equal and opposite, the Honda Discord.
honda fit vs honda injured
Honda Odyssey and Honda Iliad
Toyota Tacoma and Toyota Seattle
Dallas Semiconductor and Fort Worth Semiconductor
GDB: thats too hard. heres 207 system registers i think are good. do you like this
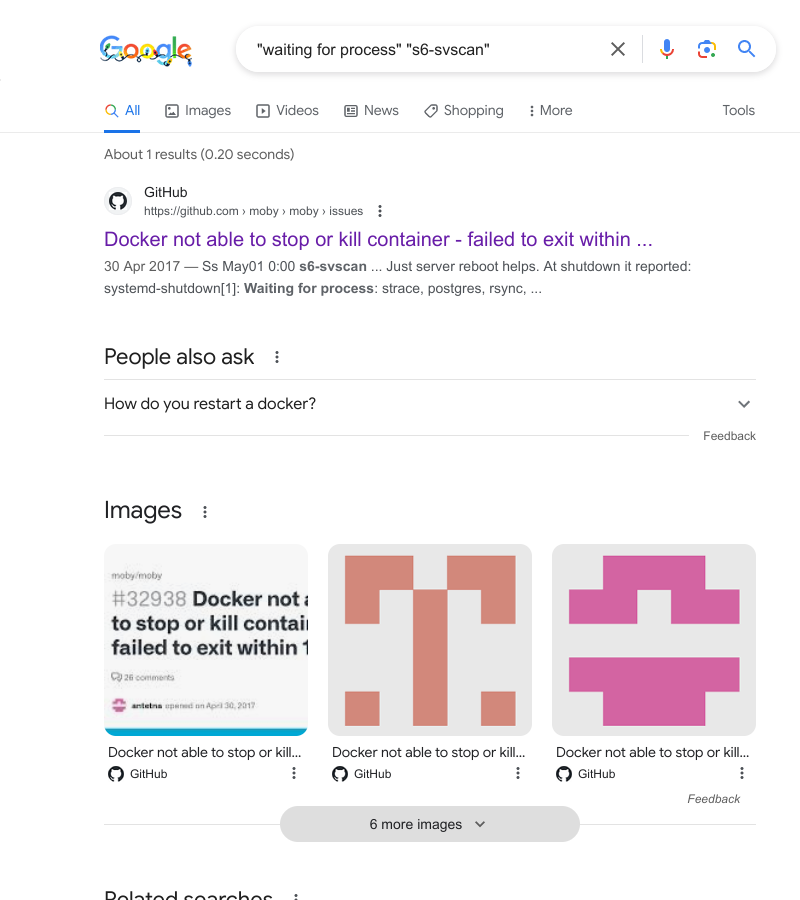
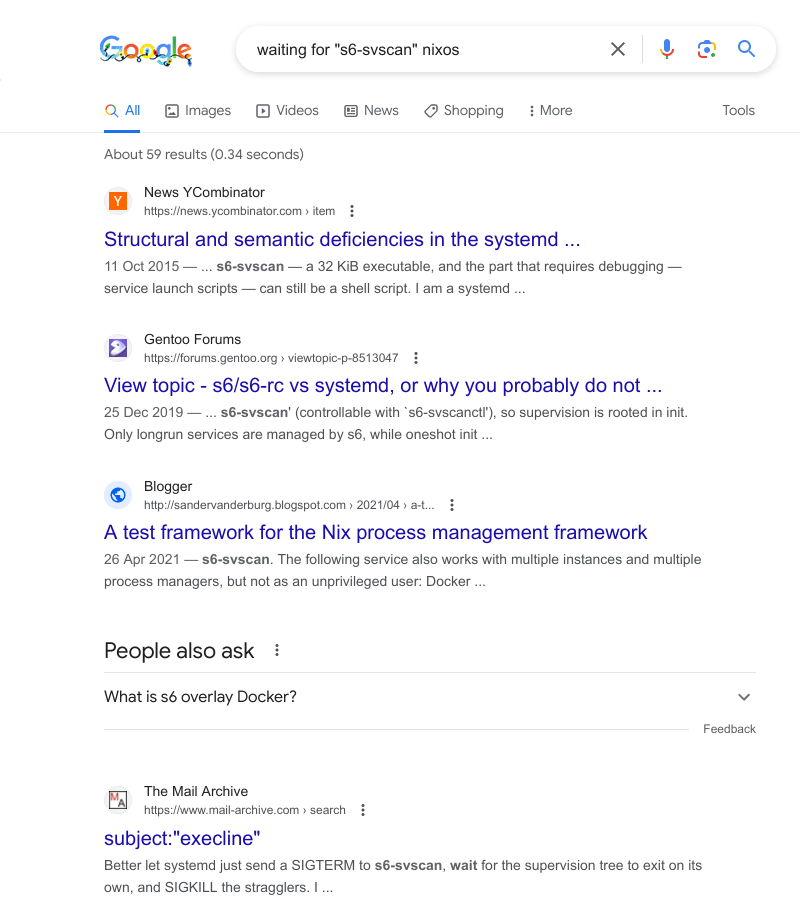
Rrrr. Hehehehehe. Row.
Mrow! Maaaaaaaaaow! Prrr, prrr
pyon pyon! [honking sounds]
awooooooooooo!!! rrrrfff! bark bark!!!!
barkbarkbarkbarkbark!!! awooooo
Chuff chuff chuff chuff
DOOK DOOK ARAWRAWRAWRAWRAWRAWR DOOKDOOKDOOK ARARARARAR
Mwee
there are only six files that the posix committee could get all the vendors to agree must exist at guaranteed paths:
/
/tmp
/dev
/dev/null
/dev/tty
/dev/console
all other paths are implementation-defined, strictly speaking, including the popular /bin/sh and /usr/bin/env.
unix existed before posix, and vendors can make the reasonable if annoying decision to prioritise compat. for example, in solaris 2.6 the posix shell is /usr/xpg4/bin/sh, leaving /bin/sh as bourne shell until solaris 10!
this is part of why maximally portable shell scripts like autoconf’s configure scripts are so arcane. btw wanna find posix sh in a maximally portable way? lol. lmao
that said, being maximally portable isn’t for everyone. if you’re only targeting modern linux and bsd, you can probably assume /bin/sh is posix :)
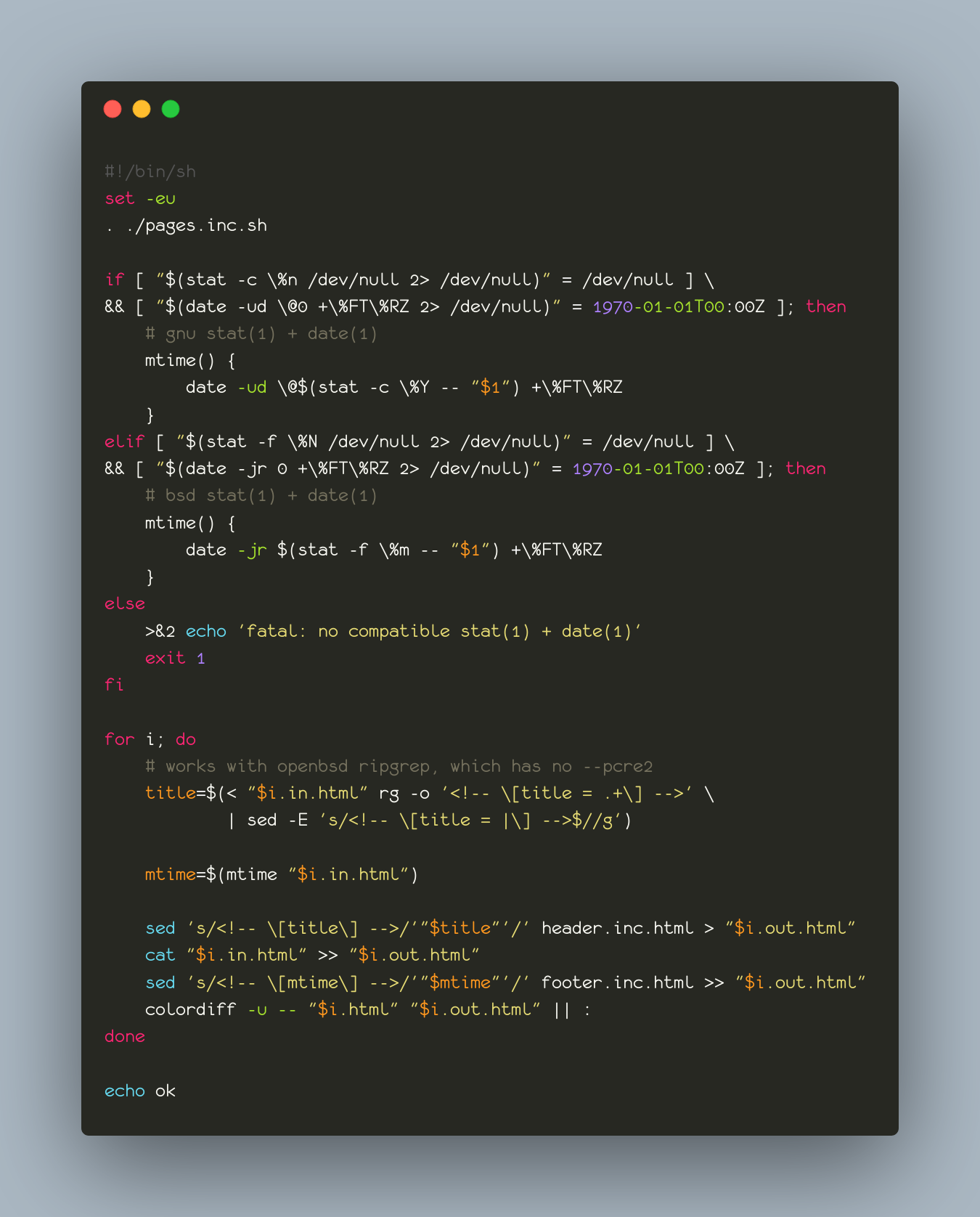
“it will be fun and lightweight”, she said
![nabijaczleweli’s blogn_t.h, with a handful of html fragments in #define macros. for example, BLOGN_T_FOOTER() contains the words “[…] Nit-pick? Correction? Improvement? Annoying? Cute? Anything? Don'<!--'-->t hesitate to […]”, while HEADING_S(level, hid, style, ...) expands to “<h##level id=STR(hid) style>HEADING_LINK(hid) __VA_ARGS__</h##level>”.](/posts/attachments/a88008c8-e8be-496f-a4f7-5dd2c50e5b48/image.png)
tbh this fixed-function static site generator pales in comparison to @nabijaczleweli’s blogue, which uses the c preprocessor(!) to stitch together its html.
notice how Don't has to be spelled Don'<!--'-->t :)
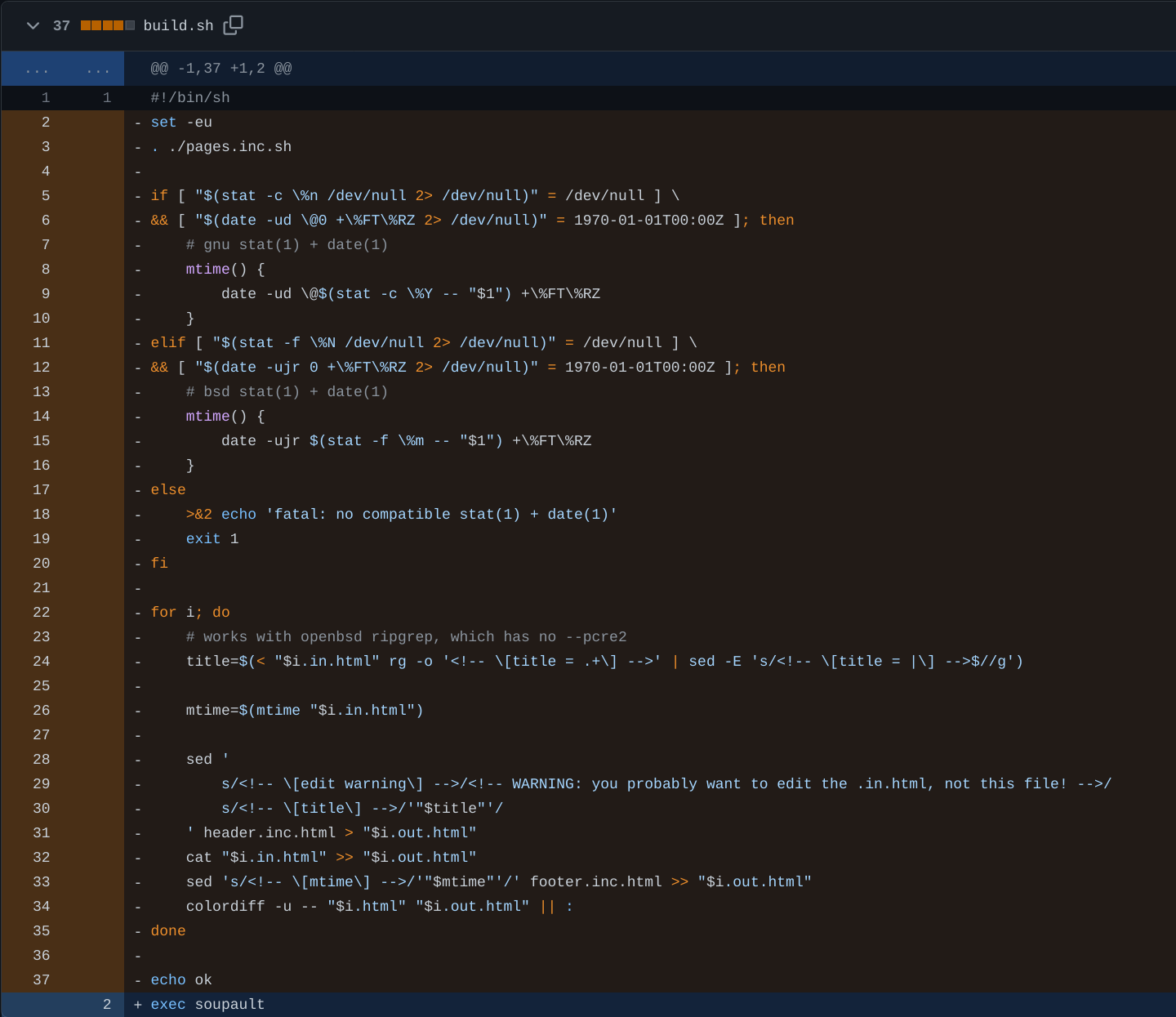
soupault is a pretty neat static site generator that works with html trees instead of the usual markup-plus-yaml-front-matter.
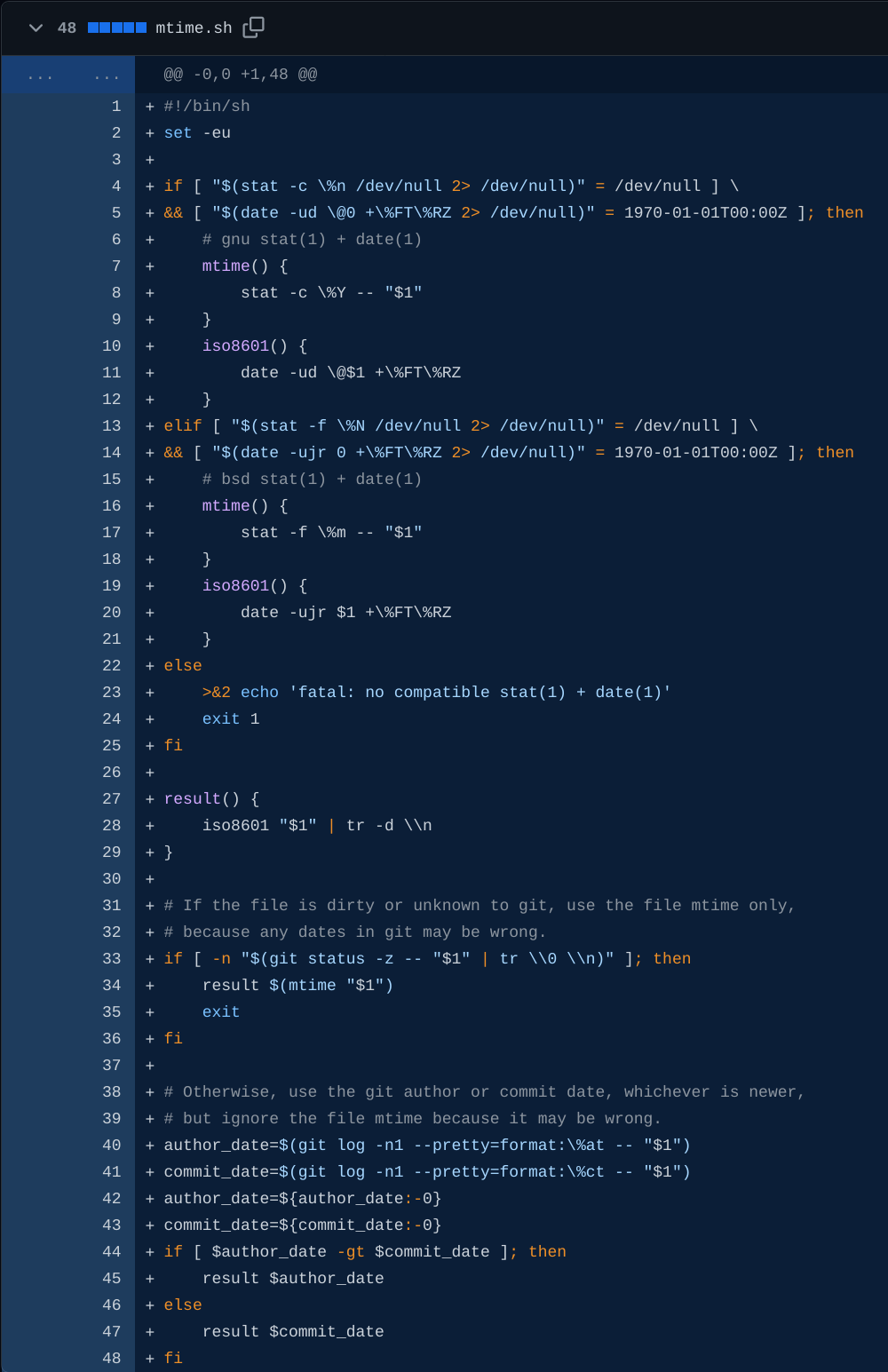
i still have a shell script for the “last modified” line on each page, which continues to be unlucky enough to rely on two (2) commands that are completely incompatible between gnu and bsd.
it’s weird that the default setting pretty_print_html=true makes unsafe whitespace changes that can affect text nodes in very visible ways depending on css, and it really needs a “don’t strip comments” option
but otherwise soupault’s html processing seems good and non-invasive!
“it will be fun and lightweight”, she said
tbh this fixed-function static site generator pales in comparison to @nabijaczleweli’s blogue, which uses the c preprocessor(!) to stitch together its html.
notice how Don't has to be spelled Don'<!--'-->t :)
soupault is a pretty neat static site generator that works with html trees instead of the usual markup-plus-yaml-front-matter.
i still have a shell script for the “last modified” line on each page, which continues to be unlucky enough to rely on two (2) commands that are completely incompatible between gnu and bsd.
“it will be fun and lightweight”, she said
tbh this fixed-function static site generator pales in comparison to @nabijaczleweli’s blogue, which uses the c preprocessor(!) to stitch together its html.
notice how Don't has to be spelled Don'<!--'-->t :)
soupault is a pretty neat static site generator that works with html trees instead of the usual markup-plus-yaml-front-matter.

here’s a recipe for loaded macaroni cheese with corn, bacon, and onion. @ariashark and i have been enjoying this for over four years.
why “cheat’s béchamel”? well instead of making our sauce by adding cheddar cheese to béchamel sauce, which is in turn made by adding milk to roux (butter and wheat flour in a 1:1 paste), we make our sauce by adding cheddar cheese to milk thickened with corn flour.
now for the steps.






you will make the sauce in three phases: preheating phase, thickening phase, and melting phase. avoid boiling the sauce at any point other than the end of the thickening phase or the end of the melting phase. if your sauce is boiling at other times, your burner is too big or turned up too high.
. front: adding 1tbsp of corn flour to the remaining milk in a cup.")
troubleshooting: if the milk never seems to thicken, increase your burner, but avoid increasing your burner more than necessary to make the waiting time finite.





(images uploaded with my cohost bulk image uploader)
you know how people steal catalytic converters? what if we made a heist movie about stealing catalytic converters

❌ bobs your uncle
⭕️ bingos your sister
day 1: surprisingly lucid despite the low energy. the lack of stimulants unleashed a baseline of uhh, feelings(💦) that i wasn’t expecting and made it a lot harder for me to go out to the shops. got stoned and fell asleep at like 18:30.
day 2: very lethargic. written words slide off the folds of my smooth brain as if i had snorted a line of teflon. that said, i managed to cook something simple, fix the shower drain, and brush my teeth. first half only the mildest of a bad sensory time, second half oh god augh i can feel everything so loud and hear everything so loud and my legs are itching so loud and everything is so loud and everything is touching me and everything needs to f̷̧̡̳̹͕̤̝̹̬̳͖͗̓̍͜ú̵̜̠͖̩̪͇̱c̸̨̮̯̹̾̊̑͒͝ķ̸͓̻̪͕̗̐̒͗ ̸̡̨̺͇̥̯̗̥̣͖̩̓͜ȏ̴̜̪̝̠̳̱͙̅̏̀̚ͅf̵̜͉̥̪̩̿͌̿̑ͅͅͅf̶̪̫̙͎̰͛̅̆͠
day 3: pretty good to start with. reorganised the pantry, took shark to get its bloods done (with questionable driving ability), and did the groceries (with great difficulty). but as for the second half, see day 2.
day 4: comfy day, i didn’t try to push myself too hard. watched videos and wiggled with peb for most of it, but 13 hours into my day i started falling off mental and mood cliffs over and over until i was just foggy and cranky.
day 5: dad groaning with every step i take to cope with how difficult everything is. i went to bunnings, washed the bedding, took a shower, and brushed my teeth. that's about all i had energy for.
so i started writing a tool for fallout: new vegas that can tell me what perks i’m eligible for or nearly eligible for, sorted by how attainable they are.
anyway it’s an excel spreadsheet generated by javascript that parses a table i scraped from the fallout wiki :3
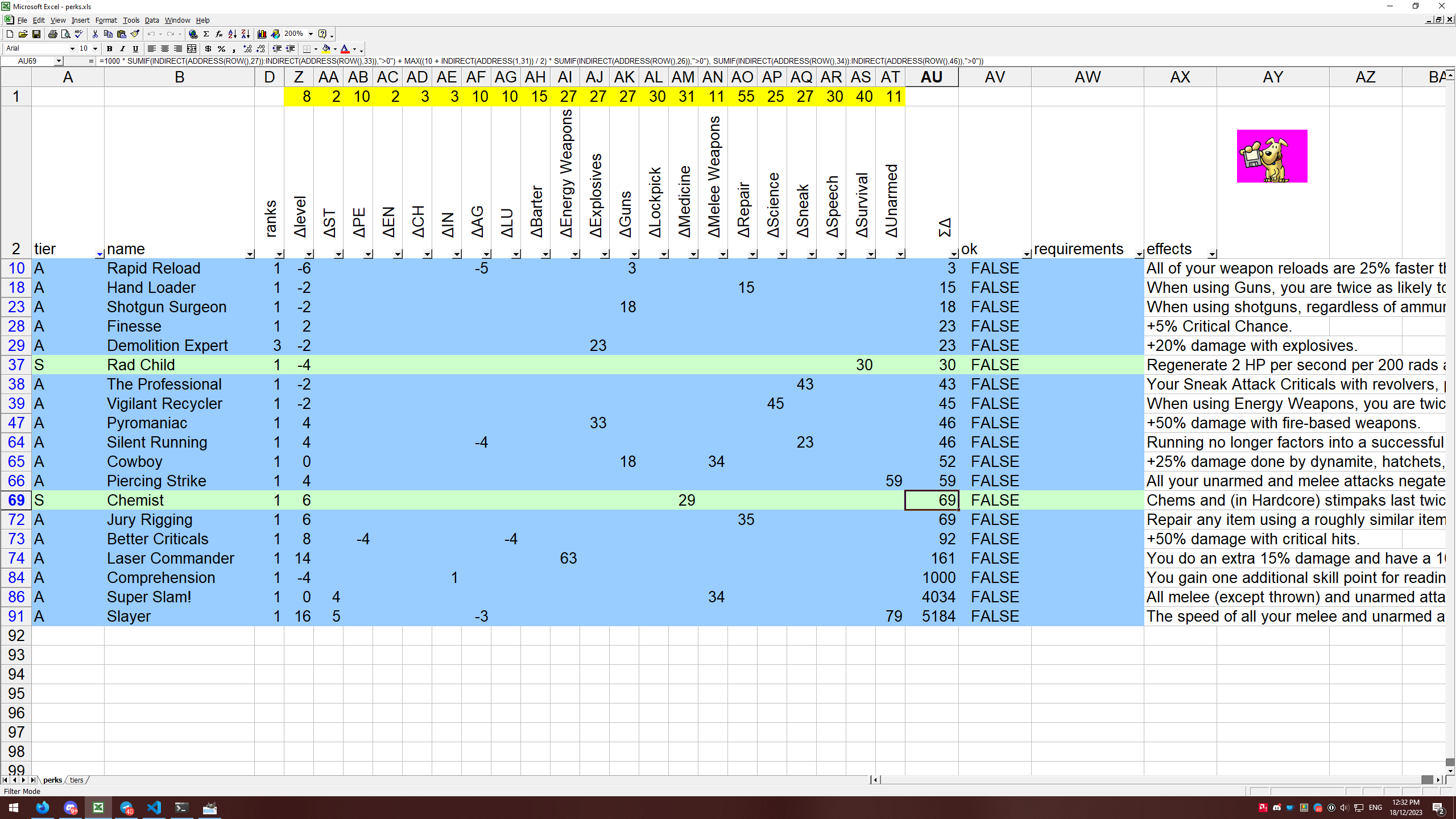
added the tiers by /u/Nazbowling11 on reddit, and now i take my current level into account, so the ΣΔ score for each perk is
1000 × sum of insufficient specials
+ max(
(10 + intelligence/2) × insufficient levels,
sum of insufficient skills)
ao!! wrrrrao!! sound version recommended:
https://kolektiva.social/@delan/111596529877850869
$ ffmpeg -i dogclippy.mp4 -vcodec libwebp -vf fps=fps=12,crop=640:360:512:0 -lossless 0 -compression_level 3 -q:v 60 -loop 0 -preset picture -an -vsync 0 -s 1280:720 dogclippy.webp
(ty @catball for teaching me how to do this while cranking your hog)
so i started writing a tool for fallout: new vegas that can tell me what perks i’m eligible for or nearly eligible for, sorted by how attainable they are.
anyway it’s an excel spreadsheet generated by javascript that parses a table i scraped from the fallout wiki :3
@bark and i were tryna figure out how formulas worked under the hood, when we found some strange xla files on the install cd.
we couldn’t figure out how to edit them in excel — opening them in excel would just do nothing — but we were able to open them in libreoffice calc, and, well.
![an excel spreadsheet with the text “StubData Named Range” in A1, then A3 below that read
IF(ISERROR(MATCH("%ADDINNAME%"), DOCUMENTS(3), 0)))
ERROR(FALSE)
[…]
ALERT("%CANNOTFINDALERT%")
RETURN()
END.IF()
END.IF()
RUN("%ADDINNAME%!AutoOpenFromTemplate")
RETURN()](/posts/attachments/f9af8905-48e3-47cc-9931-409777536121/d7032798d788104e.png)
they use a formula-like programming language that can (what looks like) call into dlls, and they define ui strings in the spreadsheet?
@bark and i were tryna figure out how formulas worked under the hood, when we found some strange xla files on the install cd.
we couldn’t figure out how to edit them in excel — opening them in excel would just do nothing — but we were able to open them in libreoffice calc, and, well.
yknow all this web platform work has made my language en-AU-x-color
call that philip seymour huffman
til parks have street numbers in western australia
What is true is that a majority of people—across virtually all demographics and ages—agree life in America is getting worse, and we must steel ourselves for the grim future ahead. […] This is reflected much closer to home, as well; polling shows that a quarter of Americans fear being attacked in their own neighborhood.
And our vehicles reflect these anxieties.
kuggis pluggis
and now i bark like pochita
i sometimes buy the big issue out of social embarrassment.
i don’t plagiarise a FUCKING doco >:(


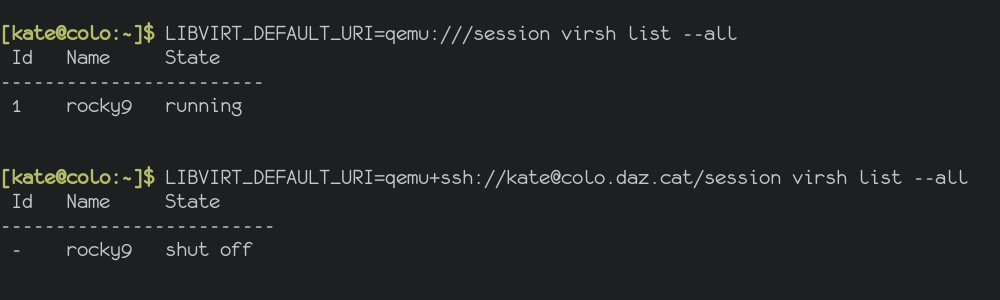
w-why does libvirt have separate user sessions depending on whether you are connecting locally or over ssh?



![Save in 1Password?
GitHub was used to sign in to:
cohost.org [Save item]](/posts/attachments/dd5523dd-c59e-494a-a637-7621a99e6a37/image.png)
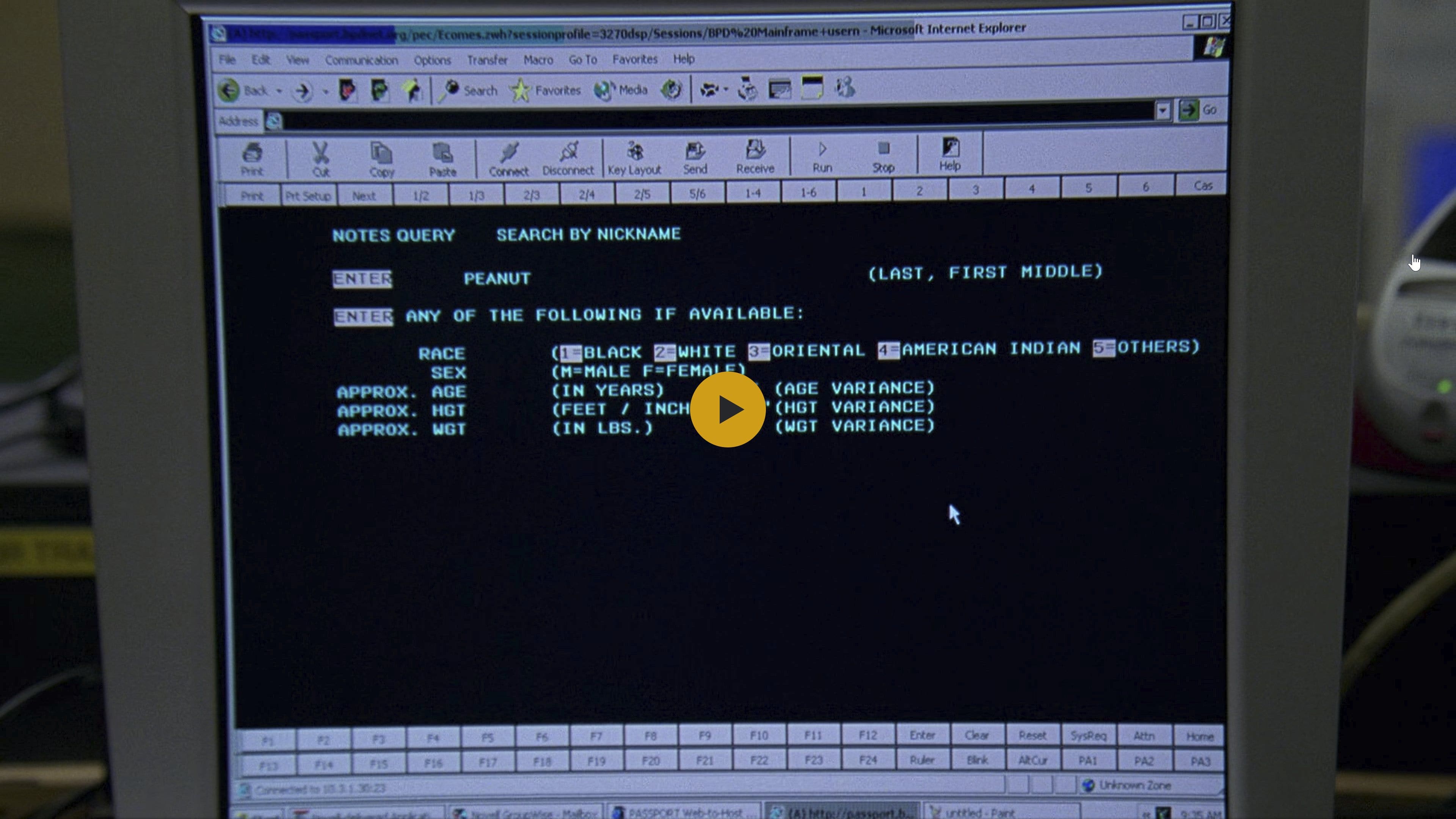
also what is this ie6 browser extension

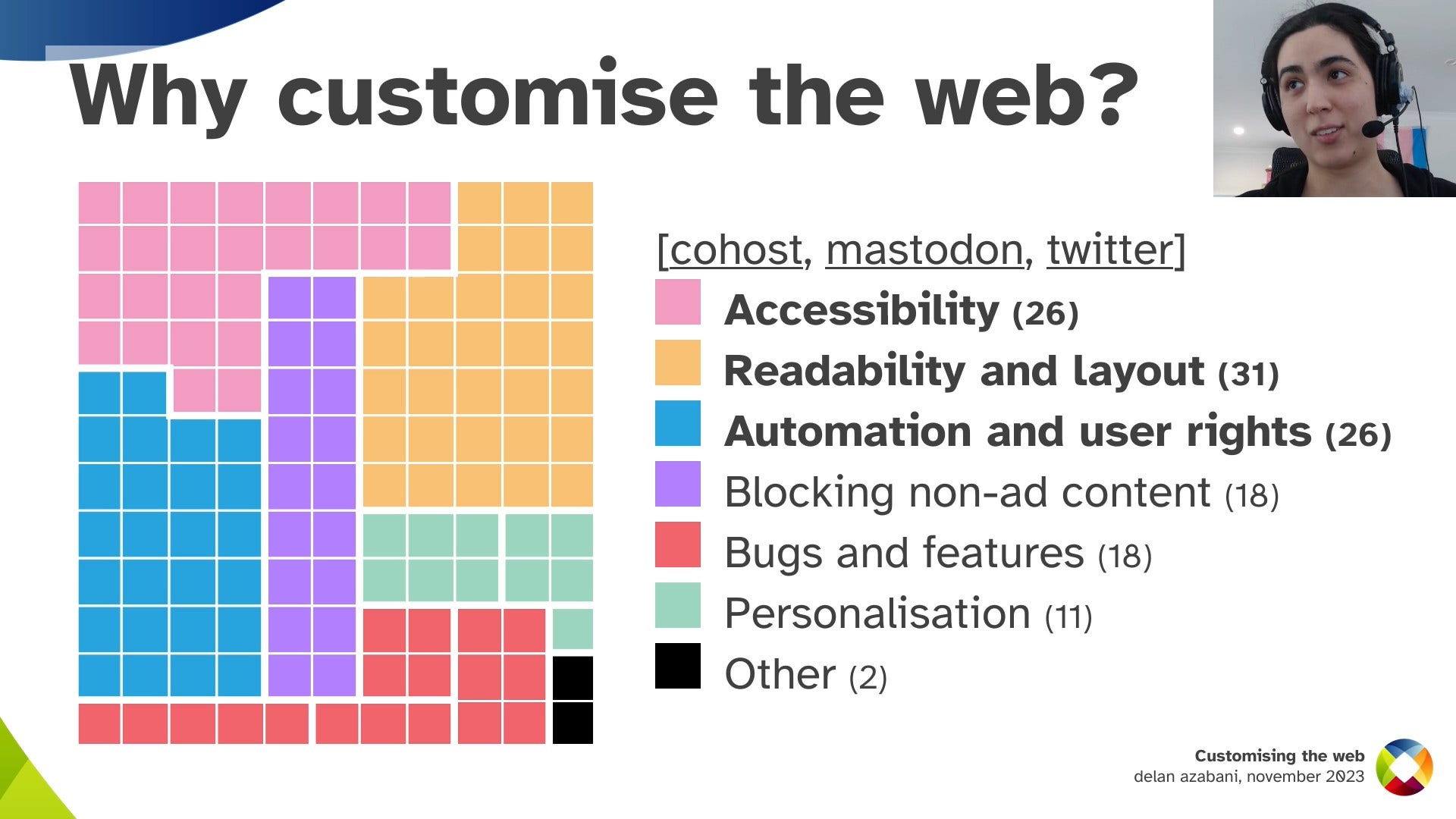
![Tools for customisation
Author tools: styles, scripts, interactivity
User tools: user styling, user scripting, bookmarklets
[cow tools]
User styling: when loading some URL, add custom CSS
User scripting: when loading some URL, run JS in page context
Bookmarklets: when loading bookmark, run JS in page context](/posts/attachments/7b785423-6487-4583-bde7-cc04a32b7765/mpv-shot0017.jpg)

i did a talk about why being able to customise the web is important, with a focus on userstyles, userscripts, and bookmarklets.
i explore how to make them, why people make them (thanks to your replies!), what we can learn from them, and how we can make them better.
i did a talk about why being able to customise the web is important, with a focus on userstyles, userscripts, and bookmarklets.
i explore how to make them, why people make them (thanks to your replies!), what we can learn from them, and how we can make them better.

if not stopped, this will give EU member states unchecked power to surveil the traffic of any EU citizen.
i don’t give a fuck about your prescriptivism, fight me
— wtyp 44, berlin wall
“can the western public be tricked into thinking that a modern nation using state-of-the-art tech to mount a genocide against a largely defenseless civilian population is acceptable? you should see it like this too, and understand why the answer cannot be ‘yes’”
— wtyp 44, berlin wall
next week i’m doing a talk about why being able to customise the web is important, and all the cool things you can do with bookmarklets, user styles, and user scripts.
but so far i’ve only written about how i use those things, which is kinda underwhelming. and i don’t really wanna “fix” that by just rehashing the top 10 most popular user styles on userstyles.org or whatever, because if there’s no context or overarching narrative or personal investment, what’s the point?
and thencan you comment or share and tell me about how you use bookmarklets, user styles, or user scripts? for example…
kid: “trick or treat!”
me: [realising i have no idea how halloween works] “h-how does that work”
parent: “oh like normally people give out lollies”
me: [stunned] “oh, uhh, i’ll have to look that up. have a good one!”
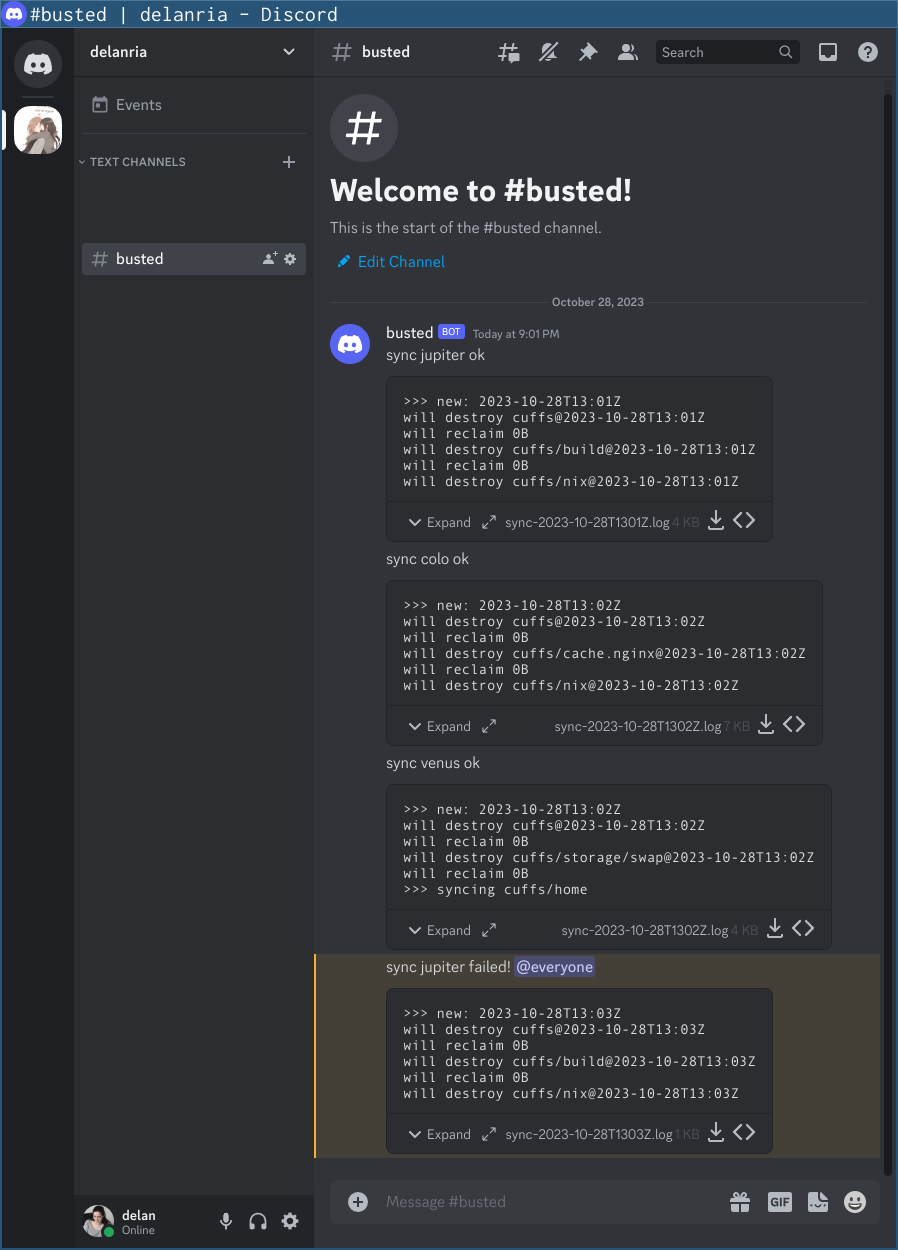
just set up daily automated zfs backups for three of my machines, including discord logging and ping on failure :D
(sauce)
i sure love having my meds wear off by the end of each workday. really makes me feel like my day job is the only value of my existence :))))))

hey how'd you get so cute huh
might be the happiness that comes from seeing you ^w^
exploiting the fact that you remove the largest element by sending it to a garbage section after the heap, rinse and repeat and you eventually have an array full of garbage. but it's Sorted Garbage :)

with @nroach44 + k + b


![@patsmythe1880 - 21 hours ago
I’ve lived in SA my whole life and have always believed that (provided you have the financial means) you’re able to externalise a lot of these issues (solar & battery system, borehole, private healthcare, private schooling etc.) and still live a good life (cheap property, domestic workers, holiday houses, natural beauty etc.). If you speak to most educated, employed South Africans, they will tell you the same thing.
Despite having private security (as most that can afford it do) we’ve been exposed to violent situations (held at gunpoint) on 3 separate occasions. I’ve also lost my great uncle (murdered on his farm) and nearly my aunt (shot in an attempted hijacking).
It’s taken a while, but I’ve come to realise I simply don’t have the risk appetite to remain here. I don’t know what living in a 1st world country is like, but know that I place more emphasis on safety than material “things”.
[…]
29 likes](/posts/attachments/410f6738-84a5-463e-913c-48e7875b52cc/image.png)

i have never seen so many wailing and malding afrikaners in one place as in this comments section. good god
ok so apparently the bug where openbsd panics on kvm can be avoided by disabling ipv6 autoconf. let’s see what happens in two weeks time :p


got a sparcstation but no keyboard or mouse? tired of having to reprogram your idprom over and over? usb3sun lets you connect usb keyboards and mice to your sun workstation, and it can reprogram your idprom with just a few keystrokes ☀️
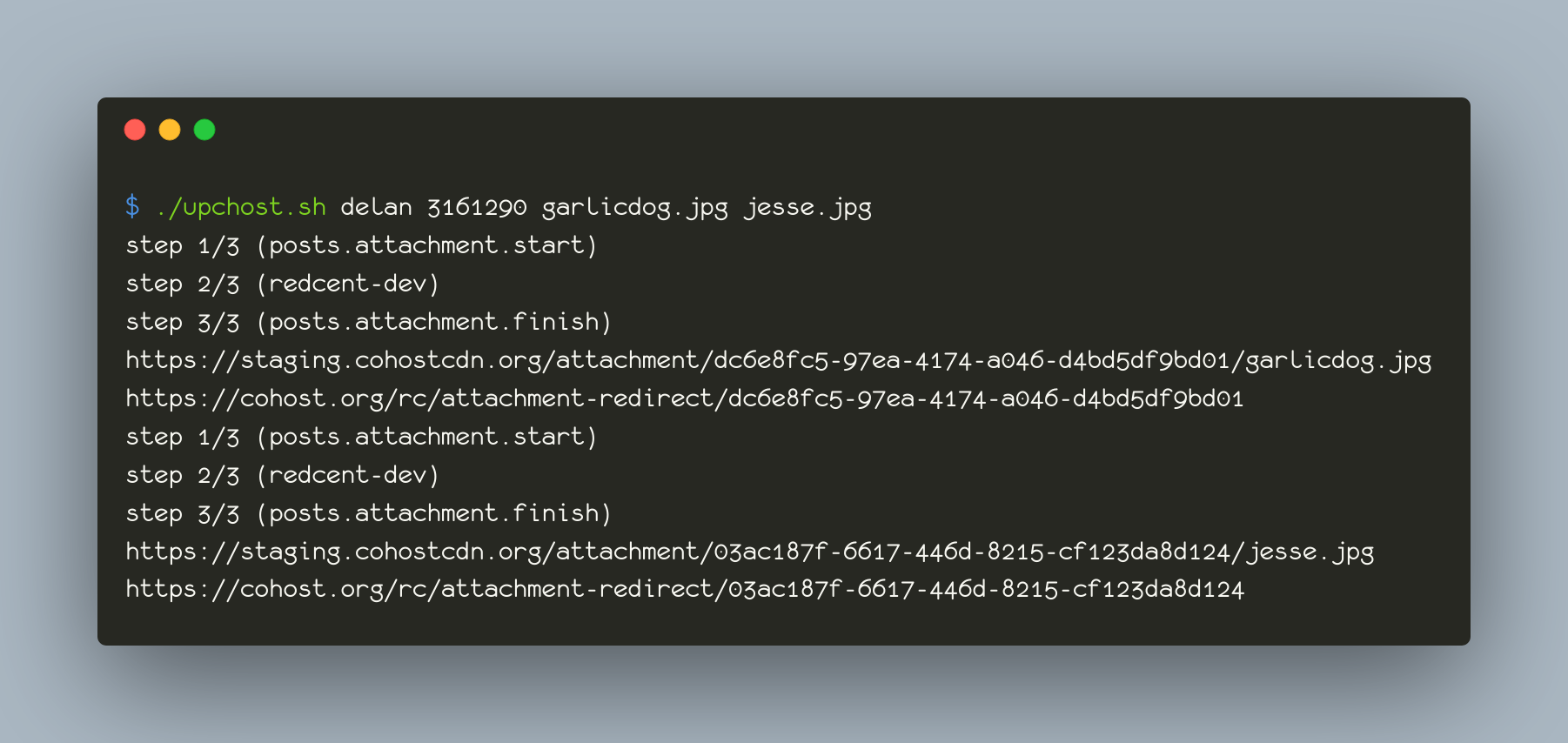
https://gist.github.com/delan/03cb9009f466e2560fed56ad80943fda


i think we should make more cool weird computers and stop making Gamer Computers
i thought i replied to this ask but i guess i didn't, so: i have three answers to this.
yeah
we are past the point where "weird computer" makes sense. we're past the point where "weird phone or tablet" makes sense. we have polished most of the edges off of computing, and except for minor things that don't even count as innovations (put more FUCKING buttons on the phones! put more FUCKING switches on them! stop taking them OFF and put more ON) the fundamental components of computing are pretty much figured out, and that's a good thing. it's good that most computers are pretty much interchangeable, and a lot of our pining for "weird computers" is really pining for being part of a frontier that was tamed by the time many of us were in our teens, if we were born at all.
gamer computers are the only thing keeping computing interesting
#3 is very important. gamers are the only reason you can buy a keyboard that isn't a rubber pad and a membrane. gamers are the only reason your mouse doesn't have a 300dpi non-laser optical sensor. gamers are the only reason you can buy a power supply with clean rails all the way up to 1500W, modular cables, caps that don't die after a year, and adequate ventilation.
"gamer chairs are stupid" before gamer chairs the only thing you could buy (unless you had $1200 for a herman miller) was an office depot special. every store sold the same one, and they were all the same cheap black pleather. six months after you bought it, the leather was cracked and the tilt mechanism had bent internally so the chair always hung at a five degree angle to the left. the back was held on to the seat by the ABS plastic armrests and if you leaned back too hard, they would snap in half and dump you on your ass.
a lot of gamer chairs suck shit, but there are some that don't. secretlab is treated like the raid shadow legendzzz of chairs, but they sell the only chair I've literally ever sat in, other than a steelcase, that didn't feel like it was going to fall apart, and then later did in fact fall apart. i have a titan XL that has stood up to two years of abuse without any of the usual failures, except for the inevitable rumpling of the armrests.
secretlab is a shitty company! as much as any other! their advertising campaigns are gross in their content, tone and quantity. their designs are also terrible - if I wanted a chair with a given videogame on it, I would be so disappointed with theirs. they clearly employ no actual designers, it's just slapdash copy and paste license bullshit. also, i wrote about how i bought a new revision of the same chair and it's garbage now. they definitely pulled the usual modern-age-of-shit bait and switch, where they made a product that was better than everything else for a year in order to build goodwill, then cut costs and are now living on the word of mouth they generated. it'll be five years before anyone notices their product got worse. but at least they made something good, once. i lived through almost 15 years of the before times, and this simply never happened.
before Corsair made "RGB gamer bullshit" an entire market segment, you simply couldn't buy... anything. nobody made anything. it was just a handful of zombie brands like belkin, selling relabeled china sludge. there were literally no keyboards in brick and mortar or online stores that were not membrane based. you had one choice of mouse, in ten different cheap plastic cases. logitech was as bad as anything else, they were just a little sturdier.
i don't think you could buy an AIO water cooler for any price, anywhere, in 2010. you had to build it from parts and then the seals failed and destroyed your PC 100% of the time. nobody had high refresh rate monitors back then, but they never would have made them for "enthusiasts"; only gaming made the expense worth it.
do i love that all this stuff is explicitly "gamer"? no! of course not! i much prefer my first response - we should have weirder stuff, etc. but this is my "we are unfortunately mired in capitalism" response: under the economic system that is likely to persist for the rest of our lives, we are forced to thank Gamers for making computers good, at all.
i need to see how im supposed to name things, i have no fucking object permanence
really liking ghidra’s namespaces feature ^w^
i need to see how im supposed to name things, i have no fucking object permanence
really liking ghidra’s namespaces feature ^w^
i need to see how im supposed to name things, i have no fucking object permanence
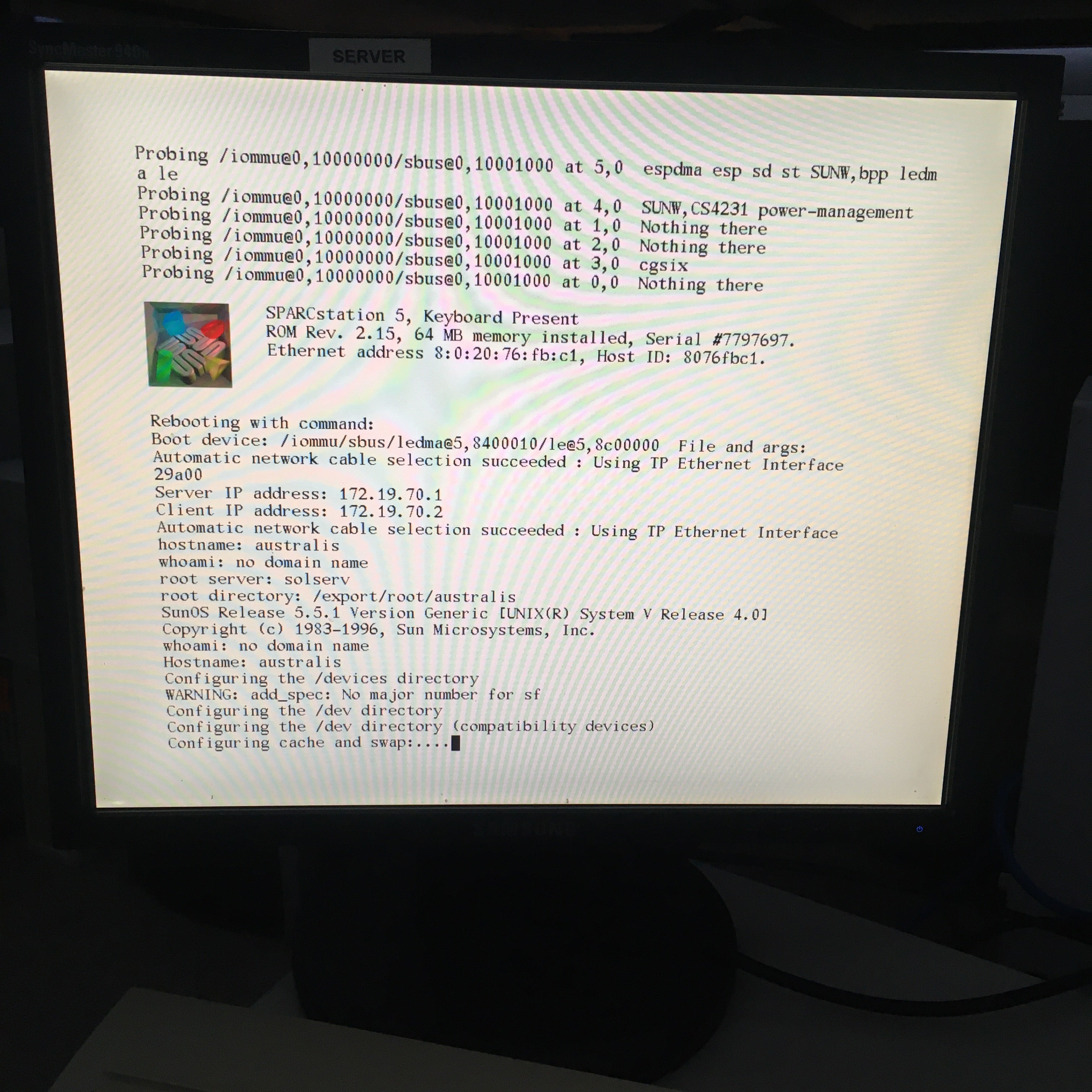
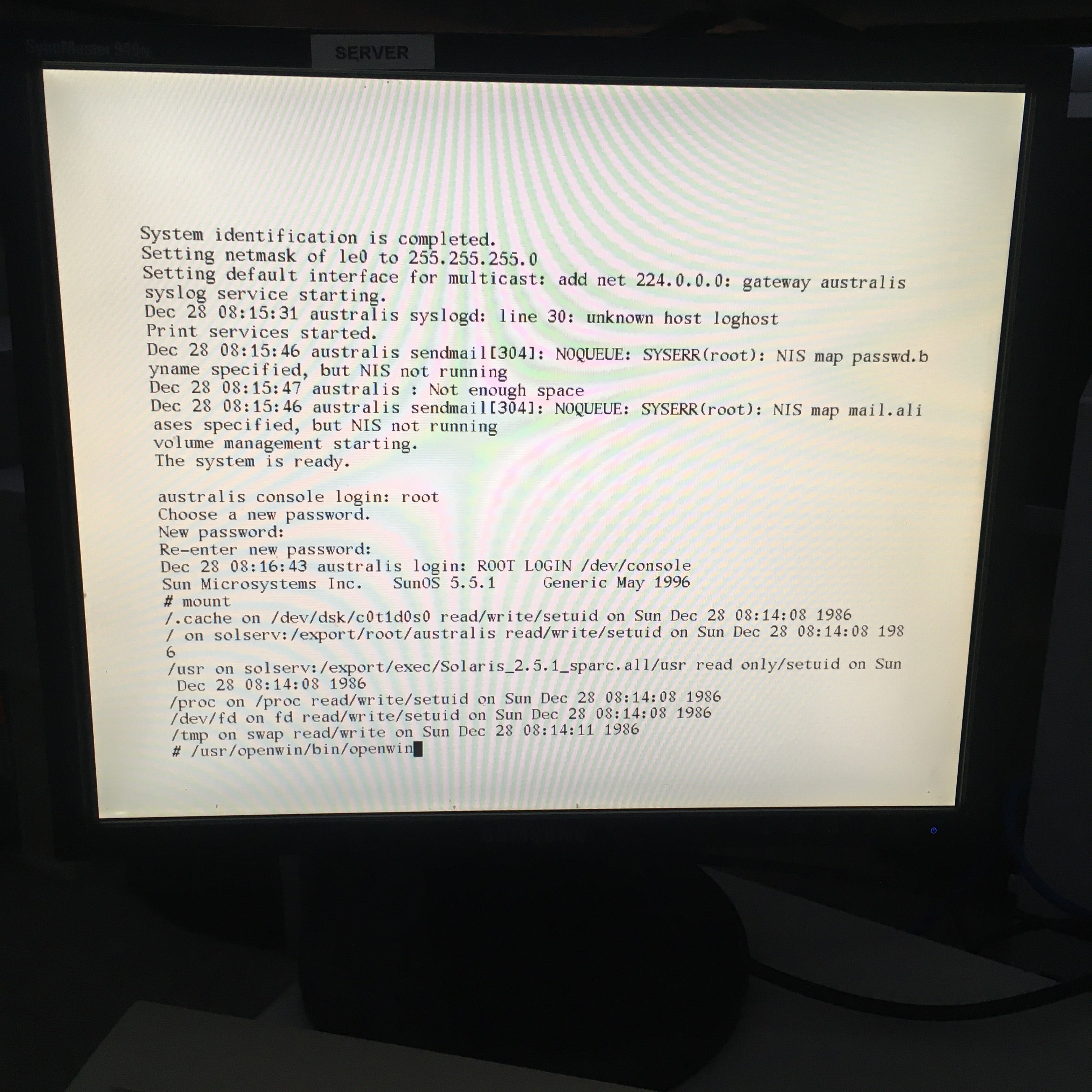
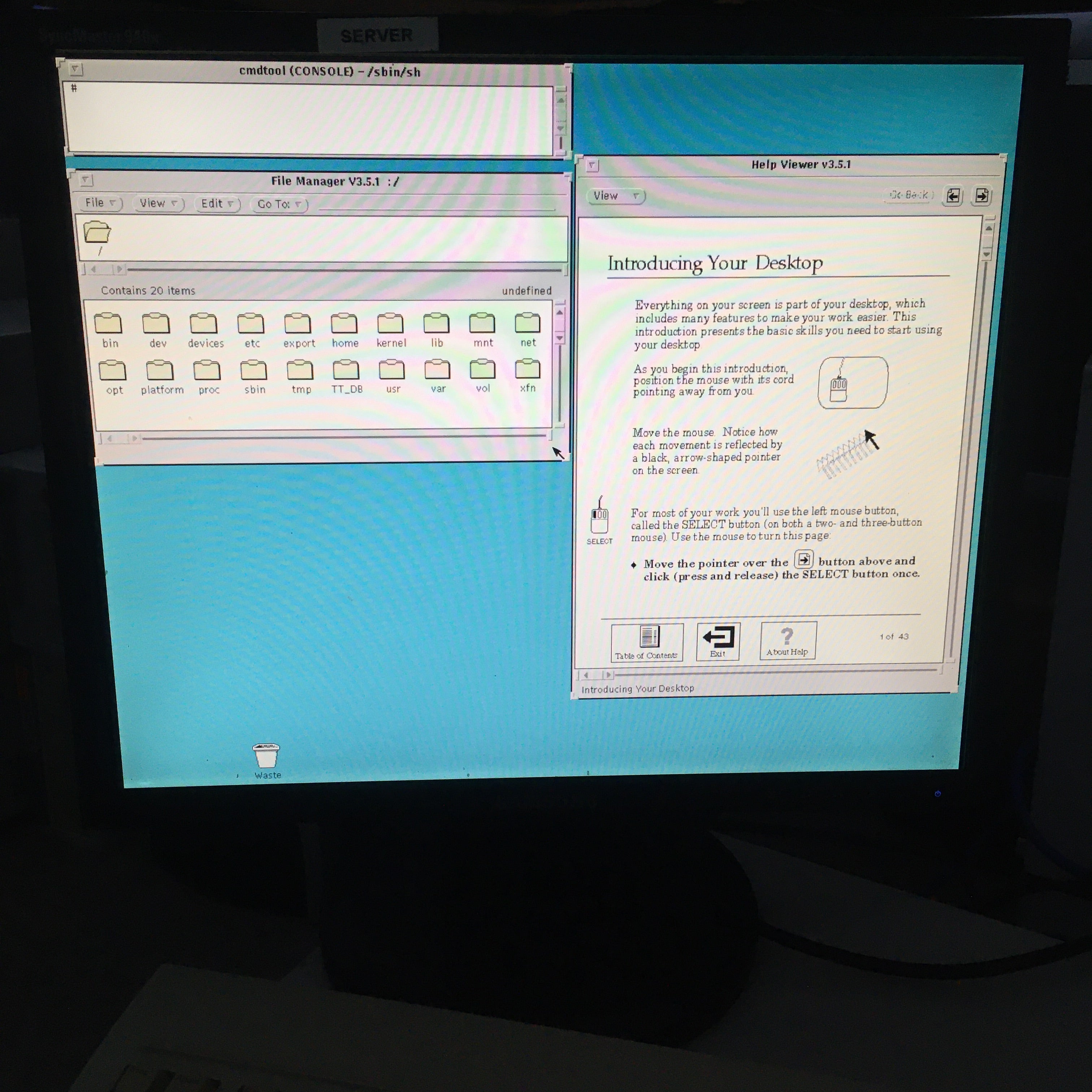
solaris 2.5.1 on a sparcstation 5, netbooting from a solaris 2.6 server running in qemu!
stay tuned for the writeup if you wanna build your own :)
how many meanings can one tag have?
the most i’ve found is #goon, with four (4)
![“Retail workers in Australia have historically been low-paid. This is due in large part to a lack of industrial militancy. But a change is sweeping through the industry. Over the past two years, retail workers have taken industrial action at bookstores Better Read Than Dead and Readings, and even gone on strike nationally at Apple stores.
“Now this new phase of union action is set to hit Australia’s supermarket duopoly. Coles and Woolworths together dominate roughly 70 percent of the market. On Saturday, October 7, workers at both chains will undertake the first ever national strike of Australian supermarket workers.
“Coles’s and Woolworths’s profits for the last financial year were $1.1 and $1.6 billion, respectively. But its employees are some of the lowest paid people in the country, and must now spend over 81 percent of their income on rent if they want to live in a capital city in Australia. Supermarket workers were praised as “essential” during the pandemic, but in practice […]](/posts/attachments/53c75abc-535c-478b-8fab-0713a3d50589/image.png)
![“[…] twenty you only get a percentage of the adult rate. This can go as low as 46 percent — less than half of the adult wage!”
pull quote: “The higher rate isn’t normalized in warehouses because the job is harder, it’s normalized because the union is stronger.”
“Coles completely relies on these junior rates. Many workers don’t realize how much less they’re getting paid — it can be difficult and embarrassing to talk about. But people are starting to get how shocking this is and are taking action to change it. Abolishing junior rates is one of our big goals in this dispute. We also want the base rate moved closer to what somebody would get in a warehouse, which can be around $30 an hour. This higher rate isn’t normalized in warehouses because the job is harder, it’s normalized because the union is stronger.”](/posts/attachments/f10bc8dc-b64e-4bf9-af3b-f108ee6171ef/image.png)
![NELIO DA SILVA: “In theory, our part-time days and hours are set and guaranteed. But functionally there’s no such thing as permanent roster work. This is because Coles uses the catch-all term “business requirements” to call for “roster resets” to change people’s hours. For example, they can just say “October roster reset, let’s do it!”, bring you in for a meeting, and move you from the night shift to the evening shift. This means you lose money.”
“There’s nothing in the current agreement that protects you from this or guarantees no loss of pay after a reset. Obviously not everyone can just change their working hours whenever Coles demands it. If there are lots of union members at a store, the union can try to influence this process. We have close to ten people disputing this at my store right now. We can win good outcomes when union members stick together, […]](/posts/attachments/6918b596-2a4b-4611-a9bc-2aae259733a4/image.png)
together these supermarket chains account for over 70% of the market. fuck yeah
workers with the Retail and Fast Food Workers Union (RAFFWU) are striking for:
donate to the strike fund: https://chuffed.org/project/superstrike
https://jon-e.net/surveillance-graphs/
(not mine ofc)
about the history of search engines and how those evolved into the knowledge graphs and voice assistants and chatbots we have today, and the consequences of so much of our information being enclosed by huge tech/search/ad companies
We’re being made an offer we can’t refuse: it’s a shame that you can’t find anything on the internet anymore, but the search companies are here to help.

down to the warehouse district
the paint job is as stunning as her knowledge
of illegal building techniques

the trick is adding a “special” vdev 🚄⚡
$ time du -sh /ocean/private
2.5T /ocean/private
11:16.33 total
(send, add special, recv, remove l2arc, reboot)
$ time du -sh /ocean/private
2.5T /ocean/private
1:17.16 total
https://forum.level1techs.com/t/zfs-metadata-special-device-z/159954

(unless you’re having a migraine or something)
usb3sun rev A1 added two led indicators that are run at 15mA, or 80% of the brightness of the nominal 20mA. since this was done passively with a resistor, that current and brightness only applies when the supply is exactly 5V. this was Way Too Fucking Bright.
usb3sun rev A2 reduced the current down to just 3mA or 10% brightness, again only when the supply is exactly 5V. this was Still Too Fucking Bright.
fed up with this, i decided i wanted to find the ideal brightness for this model of led before my next order. i had a couple of existing boards from rev A1 and rev A2, but i didn’t have the requisite Yet Another $30 Tool™ to replace 0402 resistors, and strictly speaking you can’t increase the value of a resistor by only adding things.
@bark pointed out that we can effectively increase the value by bridging a resistor in parallel with the load. the lower its value, the more current is stolen from the load.


of the values i could be bothered trying with plain old resistors, i liked the brightness best when i bridged 670R across the load. this meant the led was only pulling 406µA (Vf = 1V843), equivalent to replacing the 1K resistor with 7K771!
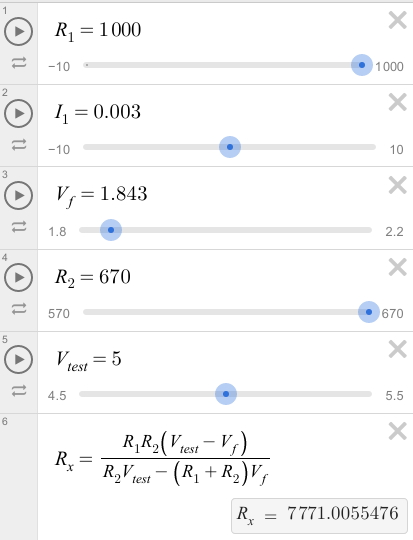
unfortunately, if we were to do that in rev A3, we would actually get anywhere between 367µA at 4V7 and 470µA at 5V5, and per the datasheet, the brightness over current curve gets Very Steep near 1mA. one could only imagine it gets Even Steeper below 1mA.
https://www.desmos.com/calculator/es3ybgxszd
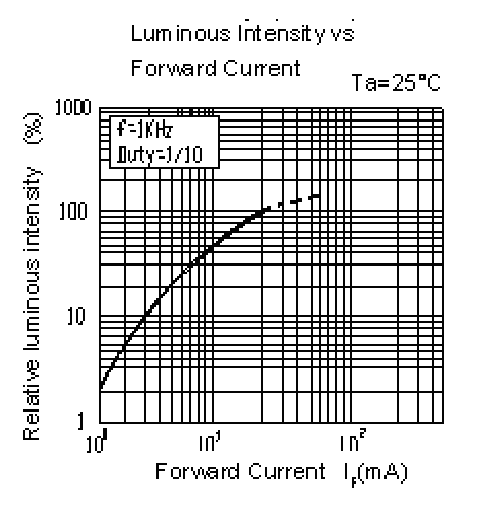
to put this problem to rest once and for all, i decided to upgrade each led indicator to use a zener diode current source, with the help of this post and this calculator. in short, it exploits the clamping behaviour of a zener diode to hold the base of an npn transistor at a constant voltage, which in turn maintains an almost constant current through the load. the gain (hFE) of the transistor doesn’t really matter as long as it’s reasonably high, though the behaviour is susceptible to interference via temperature.
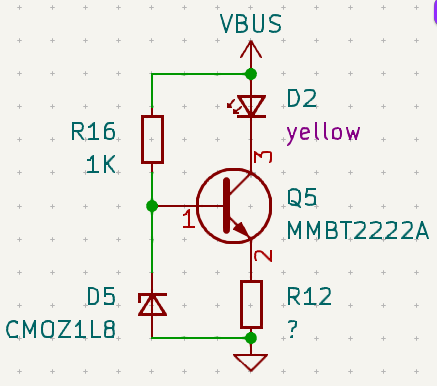
i built a test board to find the ideal brightness for this model of led, with the help of some pots, and i ended up with Re = 6K2 or so. running the numbers, that comes out to just under 200µA. i can’t even confirm this irl, because my multimeter doesn’t go that low.
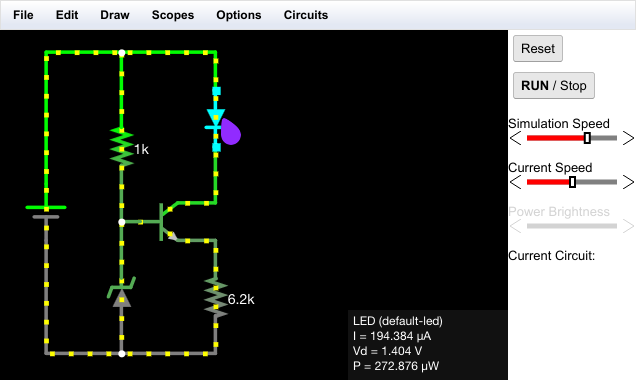
was this really necessary for two led indicators? probably not. but fool me once, shame on you, fool me twice, uhh, you can’t get fooled again. i think. ask george dubya.


got vga-to-db13w3 adapters by Tube Time, just waiting on connectors, plus led brightness test boards for usb3sun :D
<@bark> “would someone really do that? just go on the impressum and tell lies?” — BNetzA
pebochka..
(sparc)

boutta plug in my newly-repaired rice cooker with this pre-2005 c13. pray for me friends
with the spread of cuppy dog literacy across all demographics, we could be having cuppy dog banks, cuppy dog hospitals, cuppy dog buses…
(getting absolutely sloshed)
fuck i miss woolies pecan danish
i only know the first four letters of dQw4w9WgXcQ, but i know all ten letters of IN Elite!EienteiYsU. this says a lot about society



so we have this card reader that goes in a 3.5″ floppy bay.
but that’s unusual… it also has four usb 3.0 ports? i guess that would explain the pcie card, it must come with a usb host controller! it also has the usual usb 2.0 header for the card reader, which seems inelegant but i guess beats losing one of the ports.
that pcie card looks interesting though, let’s crack it open.

it looks like the cable connects to the board with a usb 3.0 header, which suggests the host controller is here, just like the front panel headers on your mainboard. look the silkscreen even reads D2+ D2− GND TX2+ TX2− GND RX2+ RX2− PWER!
but how is the board so small? on the other side, the silkscreen reads ID D1+ D1− GND TX1+ TX1− GND RX1+ RX1− PWER, which is again the usb 3.0 header pinout, but there’s no controller in sight. what gives?

well it turns out the silkscreen was a lie. we’re running pcie over a usb cable, and the controller actually lives in the main unit. abusing usb 3.0 cables like this is more common than you might think!
for example, this riser converts an ordinary pcie slot to a “usb port”, while this mainboard has a dozen “usb ports” along the bottom, which are actually pcie x1 ports. this is often used by the cryptocurrency mining “industry”.


oh and in case that wasn’t cursed enough…
yep. fun fact: it uses the USB ground pin as a signal pin, and USB shield as ground

so this line card right.
it’s an intrusion detection system module for the catalyst 6000. but what’s this huge panel for “vendor use only”? why does it have an ide hard drive? and is that a blue d-sub?


oh.

i see.


imagine hosting like an unreal tournament server on your switch, for that low low latency.
does your network switch have onboard sound and agp gpu? didn’t think so :)



brock and i shared this storage unit in wangara for six years, but we’ve finally managed to find space for all of our stuff!

(also try reading that in malcolm tucker’s voice)
if anything, everything i've experienced made me stronger. that's not a quality i like, necessarily. i didn't want to have to be strong.
i've lost this whole list of people and probably even more that i'm forgetting just since the start of 2022. there's no protocols to follow when you're losing that many people from your circle. because humans aren't designed to fucking deal with so much loss.

ive bbeen infected by.. a woke mind virus 😱🥴😵💫⚡️💁♀️🐶
(@ariashark + @bark)
[WR] Gizmos & Gadgets! 1.2
auto% (without chimps) in 14:29 (−4:13)
https://www.twitch.tv/videos/1916652364
[WR] Gizmos & Gadgets! 1.2
any% (without chimps) in 53:42 (−5:46)
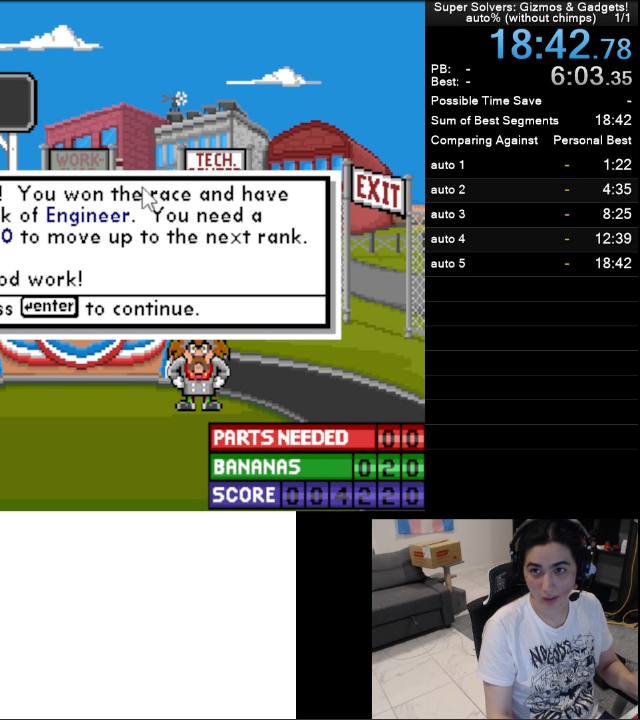
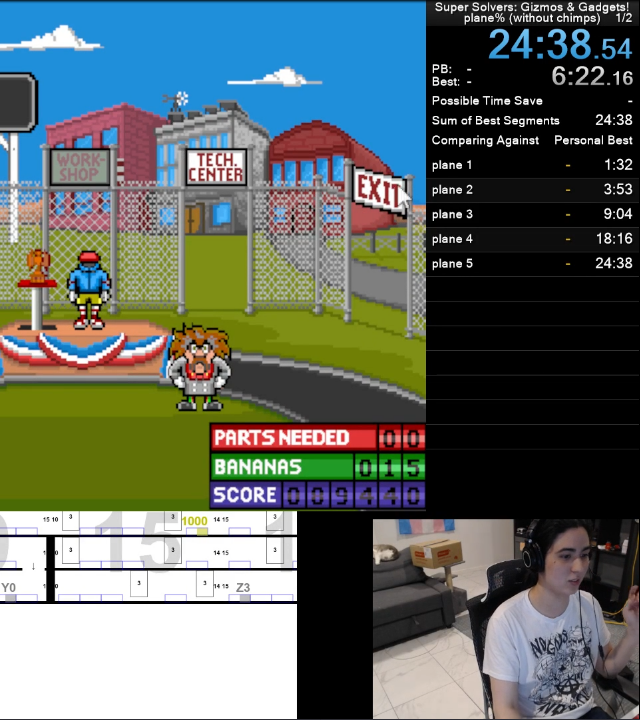
no one has set any times for the gizmos & gadgets buildings without chimps, so let’s fix that!
[WR] (technically)
Gizmos & Gadgets! 1.2
auto% (without chimps) in 18:42
https://www.twitch.tv/videos/1915188201
[WR] (technically)
Gizmos & Gadgets! 1.2
plane% (without chimps) in 24:38
and now for the last uncontested category!
[WR] (technically)
Gizmos & Gadgets! 1.2
ae% (without chimps) in 21:35
no one has set any times for the gizmos & gadgets buildings without chimps, so let’s fix that!
[WR] (technically)
Gizmos & Gadgets! 1.2
auto% (without chimps) in 18:42
https://www.twitch.tv/videos/1915188201
[WR] (technically)
Gizmos & Gadgets! 1.2
plane% (without chimps) in 24:38
happy wednesday! it’s been a hell of a week at cohost florida HQ. jae was hoping to get back to full work this week, but the rapid formation and encroachment of Hurricane Idalia means that they spent yesterday preparing and today hunkering down by government order. oh well! everyone on the west coast is doing ok though, relatively speaking.
here’s what’s new:
that’s all for this week! stay dry, stay safe, and thanks for using cohost!
— @staff
![Stop doing long distance
Partners were not supposed to be far away
Years of being gay yet no real-world use found for living in different houses
Wanted to spend time apart anyway for a laugh? We had a tool for that: It was called “commuting to work”
“Yes please only let us meet once a month. Please conduct this relationship over discord” - Statements dreamed up by the utterly deranged
Look at what geography has been demanding your respect for all this time, with all the tectonic plates and latitude we built for them:
(This is real long distance, done by real gays):
[A screenshot from Apple Maps of a route that is 6 hours 32 minutes and 333 miles]
[A screenshot of a train journey that is 7 hours 36 minutes and has 3 changes]
[A screenshot from discord that says “you started a call that lasted 9 hours”]
“Hello I would like no cuddles please”
They have played us for absolute fools](/posts/attachments/317e6123-6d87-447d-b427-32fd3e2dde50/604ace6e55e7fc3d.png)
(by @olivvybee)

messed with the image enough that it looks like official ui

void puppy and void dog are real and so very gay for one another



i want you to stay absolutely calm.
i’m coming out in a moment, and i want you to keep your cool.
are you ready? here i come,

i think i hauve covid
“it will be fun and lightweight”, she said
tbh this fixed-function static site generator pales in comparison to @nabijaczleweli’s blogue, which uses the c preprocessor(!) to stitch together its html.
notice how Don't has to be spelled Don'<!--'-->t :)
“it will be fun and lightweight”, she said

TRANS
RIGHTS
🤍
im trans too lol
![% ( cd labs/charming; ./nginx.sh | doas tee /etc/nginx/.site/charming.conf )
location ~ [.]br$ {
more_set_headers 'Content-Encoding: br';
expires 24h;
}
location / {
rewrite ^(/05469b10b9150a46d633/data[.]hlvt[.]bin)$ $1.br last;
rewrite ^(/0c1f9ba9f4e519f3a3c2/data[.]hjsn[.]bin)$ $1.br last;
rewrite ^(/0c7bd87bc01783a21fd0/data[.]aliasi[.]bin)$ $1.br last;
# [...]
expires 24h;
location ~ [.]html$ {
expires off;
}
}](/posts/attachments/8f1be917-118c-47ed-9f1a-7fc670f5a62a/image.png)
redeploying charming bc i broke it yesterday, and im reminded of how nginx made brotli a paid fucking feature
so anyway i have a script to generate rewrite rules to serve up prebaked brotli files :)

get you a gf that sends you letters sealed with kapton tape
LOOK at what git developers have been demanding your Respect for all this time:
git -c rebase.instructionFormat='%s%nexec GIT_COMMITTER_DATE="%cD" GIT_COMMITTER_NAME="%cn" GIT_COMMITTER_EMAIL="%ce" git commit --amend --no-edit' rebase -i --root
wagwagwagwagwagwag
“what’s the command to make x11 slutty?” — @bark
lieutenant spice (ltspice)
til nix-shell -p and NIX_AUTO_RUN use channels, even if you’re on a system with flakes, so remember to bump your channel when you upgrade
<@bark> “when other developers do stuff wrong it's cause they're lazy and dumb, when i do stuff wrong it's cause i'm smart and just saving time” — j blow
yknow the thing i love about wolframalpha is that it can just calculate the weirdest shit and it will never question what the fuck you're doing. you can ask how much 20 bagels per FIFA football field area each hockey match duration is and it will gladly tell you that its ~7-18 second bagels per square meter
So at first I was confused, but I'm a dimensional analysis kind of girl, so I got out a pencil and paper and scribbled down a bunch of stuff and I'm not a lot less confused now but I do see what happened there. I can't tell you why it happened, but, honestly, I work in biology and nothing in biology makes any sense it just happened because it happened, so this unit looks exactly like a natural outcome of evolution.
I've also done a whole lot of laughing and I'm not certain if that's because this is actually hilarious or just that this seems to be the part of my hormonal cycle when everything feels like extremely a lot, which while it includes the sads also means everything funny is hilarious and everything affirming is euphoric so I'll take it.
cyberciti․biz is the w3schools of unix
>looking for new co2 sensor
>ask vendor if sensor is real or just uses voc levels as a proxy for co2
>she doesn’t understand
>pull out illustrated diagram
>she laughs and says “it’s a good co2 sensor puppy”
>buy sensor
>it uses voc levels as a proxy for co2
using the 90w usb pd charger that came with my soldering iron to charge my 5v 1a phone, because i can’t find my normal charger

grafana but for logging my quality of life, like spoons and chronic illnesses flareups
grafana but for logging my % of barks vs words, so i can have Observability into my puppy tf progress
making sure i hit my puppy sla under threat of refunding my owner prorata
<@bark> owner gets a massive bill because they got charged for 5000 borks egress on the puppy they didn’t suspend
dealing with a major puppy leak incident after my cage was left unsecured
grafana but for logging my quality of life, like spoons and chronic illnesses flareups
grafana but for logging my % of barks vs words, so i can have Observability into my puppy tf progress
making sure i hit my puppy sla under threat of refunding my owner prorata
<@bark> owner gets a massive bill because they got charged for 5000 borks egress on the puppy they didn’t suspend
grafana but for logging my quality of life, like spoons and chronic illnesses flareups
grafana but for logging my % of barks vs words, so i can have Observability into my puppy tf progress
making sure i hit my puppy sla under threat of refunding my owner prorata
grafana but for logging my quality of life, like spoons and chronic illnesses flareups
grafana but for logging my % of barks vs words, so i can have Observability into my puppy tf progress
grafana but for logging my quality of life, like spoons and chronic illnesses flareups


around 9245 miles from capitol hill seattle
https://www.youtube.com/watch?v=3peMSsuk0rQ
with usb3sun 1.5, you can reprogram your idprom with just a few keystrokes!

SPARCstations have a unique serial-like interface for keyboard and mouse input, using a single 8-pin mini-din port. usb3sun allows you to use an ordinary USB keyboard and mouse with your sun workstation, and now rev A2 is available on tindie!
the big changes since rev A1 are
this is the third part in a series!
rev A1 was a huge success, as far as i’m concerned. i didn’t expect to sell more than a couple, and yet here we are! but for our next run, we had a few problems to solve.
every device needs a
, and it was fun writing one for usb3sun.
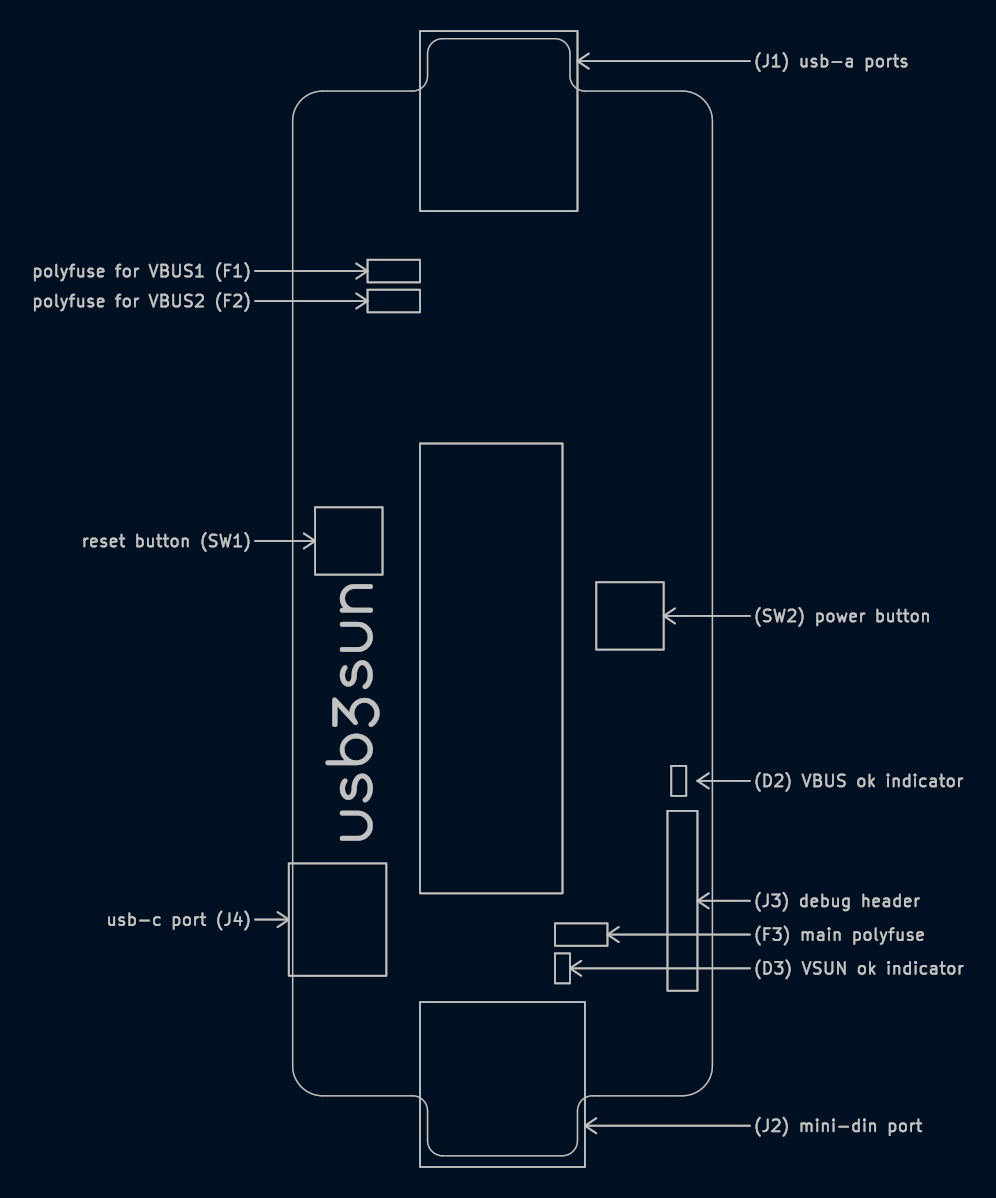
all of the firmware features and ui elements are documented there, plus detailed guides to setting up the adapter and updating the firmware, and even some of the electrical and thermal characteristics.
i drew the diagram on the User.1 layer in the pcb editor, which made it easy to get the dimensions right. hopefully that will also make it easy enough to keep the diagram up to date.
the guide has cppreference-style version annotations, so it can also be used for rev A0 and rev A1 and firmware versions older than 1.2.
through the magic of stargirl’s kicanvas, there are even links to view the schematics and pcb layouts for each revision in your browser! look i’ll show you!
| rev A0 | rev A1 | rev A2 | |
|---|---|---|---|
| schematic | rendered (source) | rendered (source) | rendered (source) |
| pcb layout | rendered (source) | rendered (source) | rendered (source) |
| display module support | source | source |
was a little tricky.
the raspberry pi pico has a micro-usb port that can be used to flash the firmware without any special software, and exposes a cdc serial device for non-usb-related debug logging. but this port becomes physically inaccessible once the pico is soldered onto our adapter.

the only other way we can get to it, aside from “inlining” the rp2040 and everything it needs into our design, is the three test points on the underside. the pico is already touching our board, so why not add a few plated through holes that line up with the test points, and fill them with solder to connect?
first we needed to edit the footprint to add the through holes. to avoid making the routing harder than it needed to be, i removed the four holes that were ostensibly for clearance from the micro-usb mounting pins, but in practice weren’t really necessary.
the through holes are circular, unlike the rounded rectangle test points, which is easier for my board house to manufacture. they are also somewhat smaller, which i’m hoping will reduce the chance of defects if the pico is placed slightly offset or on an angle.
that said, we still want to keep anything conductive out of the full area of the test points, plus a bit more for tolerance, and this is where i ran into some kicad limitations. there doesn’t seem to be a way to give holes a custom clearance shape and size. and if we add keepout areas over each through hole that
fortunately we could still forbid vias and copper fill, and it wasn’t too hard to manually keep traces and pads out of the keepout areas. it was definitely worth doing so though, because solder mask is not intended to be used as insulation.
@ariashark suggested i provide a fallback mechanism to route the usb port to gpio pins, by bridging a pair of solder jumpers. that way, if our plated-holes-over-test-pads strat didn’t work out, we could repurpose the usb-c connector as a third host port.
was surprisingly straightforward.
one of the cool things about usb-c is that there’s a standard way to request up to 3A without any digital logic. this excellent post by arya voronova explains that with just two 5k1Ω resistors, your device may be granted more than just the “default” usb power, up to 1A5 or even 3A, and you can easily check which limit you were granted with a 3V3 adc!
i was careful to ensure i added two 5k1Ω resistors wired on separate nets, to avoid only getting power when plugged in one way, or no power at all with a fancy emarked cable.
@ariashark recommended adding a main polyfuse after the power supply switches (ideal diodes), to protect the adapter as a whole under more fault conditions. previously we only had polyfuses in front of the downstream usb ports, so there was still a risk of damaging the adapter if some other part of the circuit was shorted.
i changed the led resistors from 200Ω to 1KΩ, reducing the luminous intensity from ~80% down to ~10% relative to 20mA. i figured 10% would be good enough and i didn’t want to go too far, because then the on state may be mistaken for a malfunction like the ones we’ll cover later in this post.
last and also least, i changed the tactile switches from TS-1187A-C-H-B to its sibling TS-1187A-B-A-B. i picked the former because i liked the heavier actuation force, and i thought the longer shaft would be necessary to reach the outside of a hypothetical future enclosure, which may not even be the case. but the latter is a basic part at jlcpcb, which saves a few bucks per run.
even the new usb-c port! but there are some minor issues.

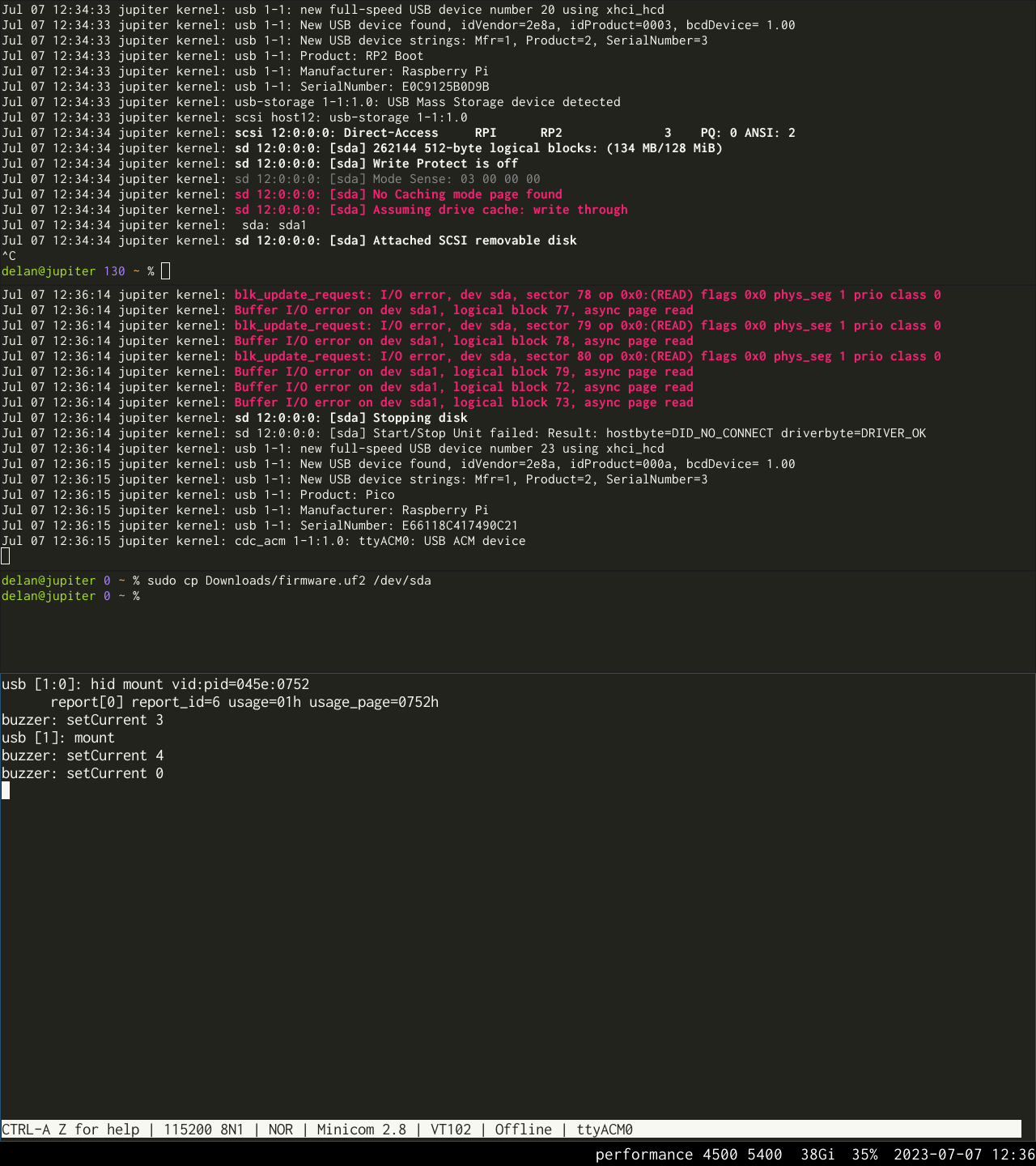
first of all, the led indicators are still too bright! ain’t modern leds amazing?

there’s also one problem new to rev A2. when the adapter is powered by VSUN, the VBUS indicator dimly lights up soon after, except while the reset button is being pressed.


probing the led’s anode with an oscilloscope, we saw a steady 2V2 or so while the VSUN indicator was dimly lit. checking resistance between VSUN, VBUS, 3V3, and GND showed normal values mostly between 574K and 748K, with VBUS ↔ VSUN being around 3M in both directions, so @ariashark and i started looking for other things that changed in rev A2.
my first idea was that our VBUS used to be tied to the pico’s VBUS pin, but since we were powering the pico via its VSYS pin anyway, that was unnecessary, so i disconnected it in rev A2. but jumping the pin onto VBUS didn’t change anything.
over time, we started to doubt that the current was being conducted onto the net, and started worrying that the current was being induced from elsewhere. after all, i had crammed all of the power supply and usb-c circuitry together quite aggressively… maybe too aggressively?
so i asked the fediverse. after realising i needed to repost it under some relevant tags, we got an answer in under an hour:
https://kolektiva.social/@babouille@piaille.fr/110721497635863990
the root cause was indeed D+ leaking through the esd diode array. the pico is running, so its D+ line is pulled up to 3V3 to show that it’s a full speed device. but there’s no voltage on our VBUS, which the esd array is using as a reference, so that 2V85 flows up the steering diode onto VBUS, which becomes 2V15 after the diode drop. this is below the tvs diode’s breakdown voltage, so it stays on VBUS without getting shunted to ground.
2V15 is enough to push about 150µA through our led and its resistor, lighting it up ever so slightly. but since there’s already 5V from VSUN on the other side of our ideal diode, it should be blocked from powering anything else. and since VBUS will always be powered while using the upstream usb port, it shouldn’t affect usb signal integrity.
our next revision will decrease the brightness of those led indicators even further, and fix the bug where the VBUS indicator can erroneously light up. we may also fix the bug where the VSUN indicator can erroneously light up while resetting the adapter.

the usb-c port is currently marked “debug only” because it’s currently only used for firmware updates and debug logging, but in theory it could be used as a third host port with only firmware changes, so we may be able to remove that from the silkscreen.
otherwise the design is fairly complete. what i’m far more excited about is implementing a macro feature, to make it easier to reprogram your hostid. if you’re as excited about that as i am, hopefully that will be a lot more accessible to you, now that firmware updates are as easy as dragging and dropping a uf2 file onto a usb drive!
if you think you’ll find usb3sun useful, consider buying one on tindie! there are four left in this initial run, but after those, we’ll order and assemble more.
did you love this? hate this? have any questions or comments? please let me know in the comments below, or on mastodon or twitter!
around 9245 miles from capitol hill seattle

18 months ago, i started hosting my websites and other public stuff out of my house. this largely went well, except for the residential power outages thing and the paying 420 aud/month for 1000/400 thing.
1RU with gigabit in a boorloo dc is like 110 aud/month. it’s colo time :)
here is what we’re gonna move the libvirt guests to.
through some wild coincidence, the new server uses the same model mobo as my home server, and its previous life was in the same dc it’s destined for.
dress rehearsal of the migration.
first we take zfs snapshots on the old server (venus), and send them to the new server (colo). then on venus, we suspend the vm (stratus), take snapshots again, send them incrementally to colo, and kick off a live migration in libvirt. finally on colo, we resume stratus, and stratus makes the jump with under 30 seconds of downtime.
venus$ sudo zfs snapshot -r cuffs@$(date -u +%FT%RZ | tee /dev/stderr)
2023-07-01T07:49Z
venus$ virsh suspend stratus
venus$ sudo zfs snapshot -r cuffs@$(date -u +%FT%RZ | tee /dev/stderr)
2023-07-01T08:51Z
venus$ for i in cuffs/stratus.{vda,vdb}; do
> sudo zfs send -RvI @2023-07-01T07:49Z $i@2023-07-01T08:51Z |
> ssh colo sudo zfs recv -Fuv $i
> done
venus$ virsh migrate --verbose --live --persistent \
> stratus qemu+ssh://colo.daz.cat/system
colo$ virsh resume stratus
can you see where the old host got further away and the new host got closer?
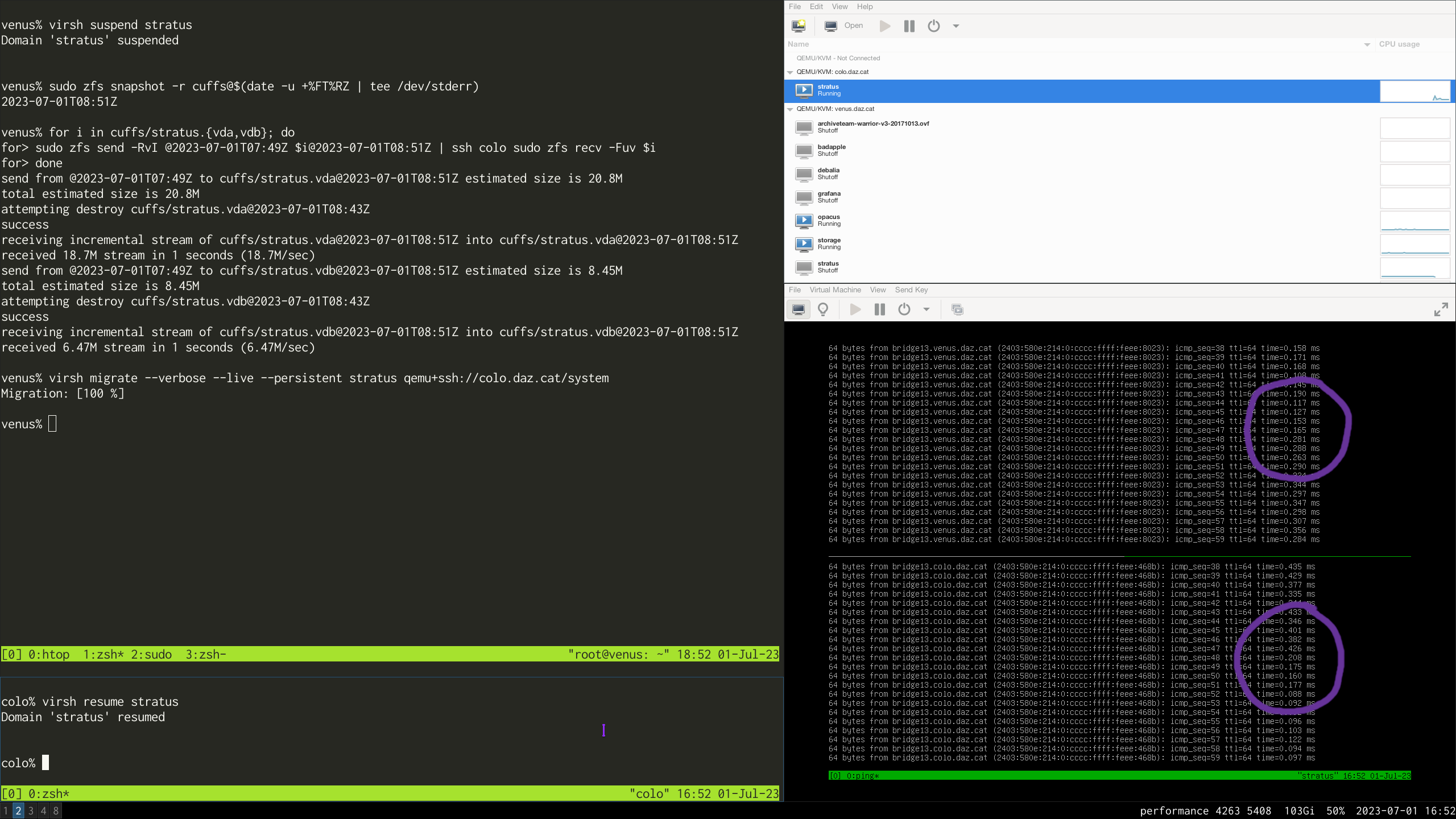


usb3sun has you covered! there’s one last adapter now in stock before our next run :3

got a sparcstation but no keyboard or mouse? usb3sun can help!

SPARCstations have a unique serial-like interface for keyboard and mouse input, using a single 8-pin mini-din port. usb3sun allows you to use an ordinary USB keyboard and mouse with your sun workstation!
back in january, i wrote about the prototype version we (+na) built to get our SPARCstations up and running, when we only had a keyboard but no compatible mouse. that worked well enough, and i even wrote a guide to building one yourself, but it wasn’t really accessible to anyone other than the most dedicated hobbyists.
since then, i’ve learned how to design a pcb, turning usb3sun from a hack into something more polished. want to know more? here’s another 5600 words about this project, plus what i learned about robust electronics, drawing schematics, designing a pcb, and 3d printing!
the basic requirements of the breadboard prototype are more or less unchanged.
the adapter communicates with the workstation over serial, and needs to act as a usb host for the keyboard and mouse, providing a 5V supply to each.
we need to power the adapter and the usb devices somehow, and we can get a 5V supply from either the workstation itself or an external debugger, but sadly the 5V pin on the sun interface is only powered once the machine is on.
newer sun keyboards (starting with sun type 5) also have a power key, which turns the workstation on, in addition to sending make and break codes like other keys. on those keyboards, the power key is wired to pull the power pin (SPOWER below) to ground, but on a usb keyboard, we can’t detect any key presses without some way of powering the keyboard.
this means we can only emulate the “soft” power key when the adapter is powered externally, but a “hard” power key that uses a button on the board itself will work at any time.
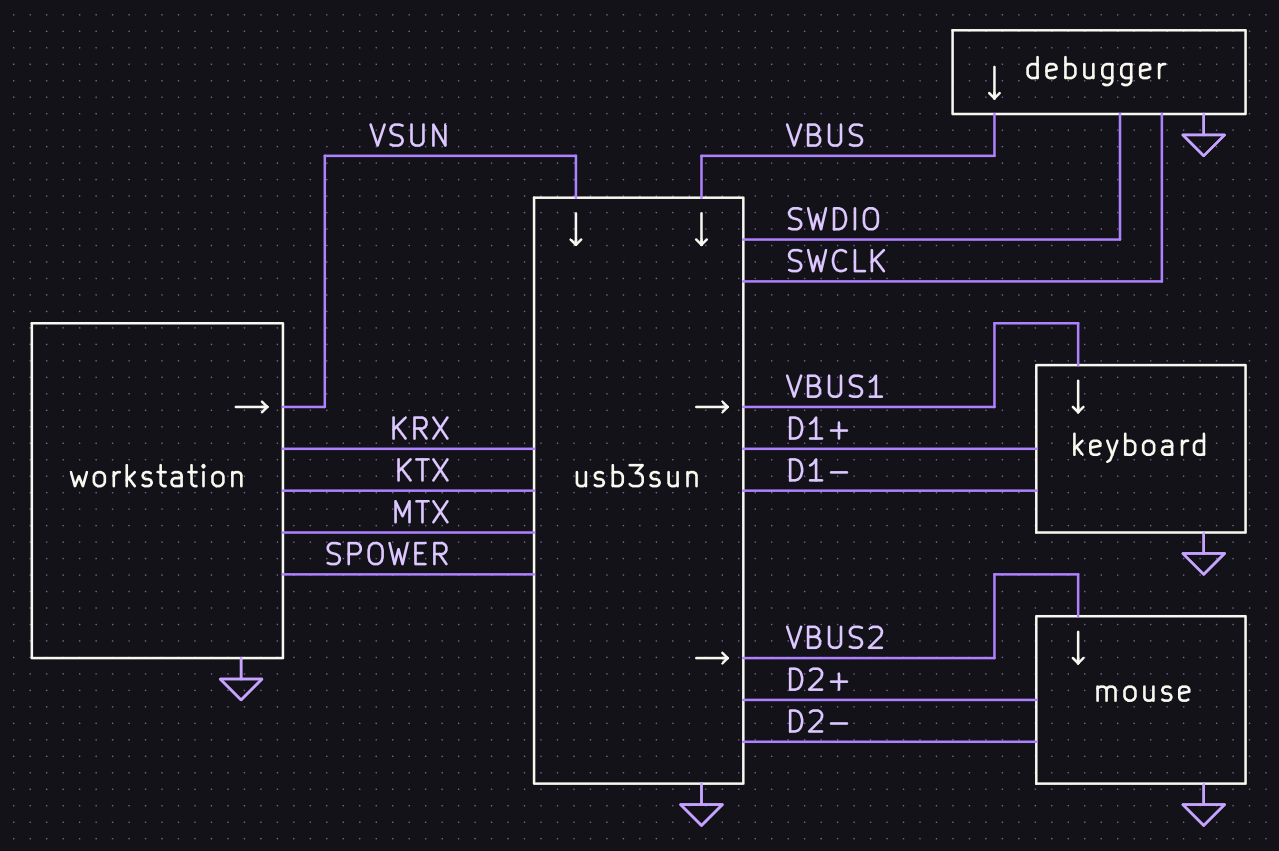
one new requirement is that we use the 5V supply from the sun interface where possible (§ dual power). in the prototype, i ignored this supply since i always had an external debugger or usb charger nearby, but it doesn’t really make sense to expect everyone to use an external power supply unless they need it for the “soft” power key.
since this is no longer a prototype, there are also things we needed to do for correctness and robustness, but more on that in § doing usb correctly and § protection features.
my initial
was a direct translation from paper to computer.
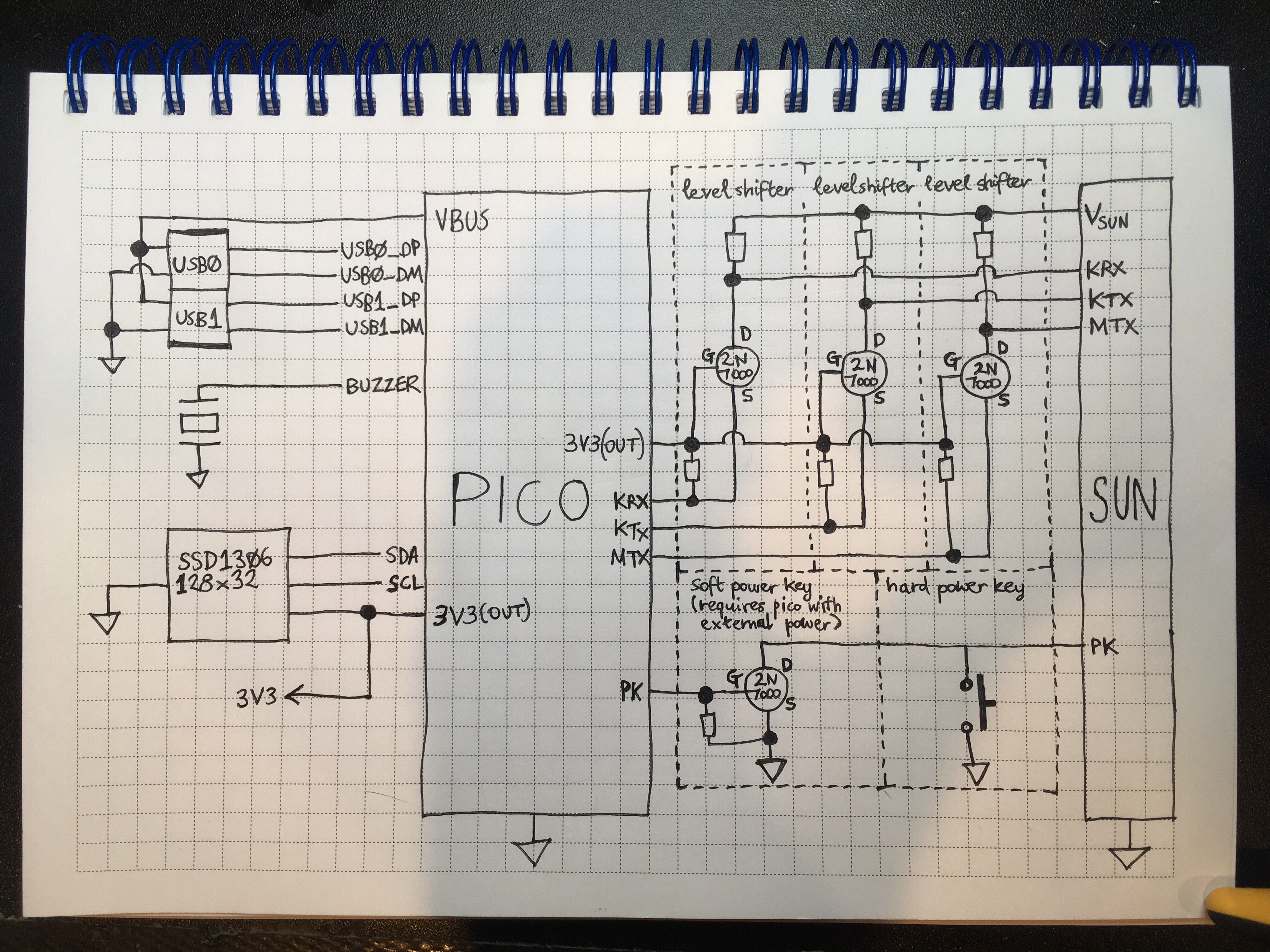
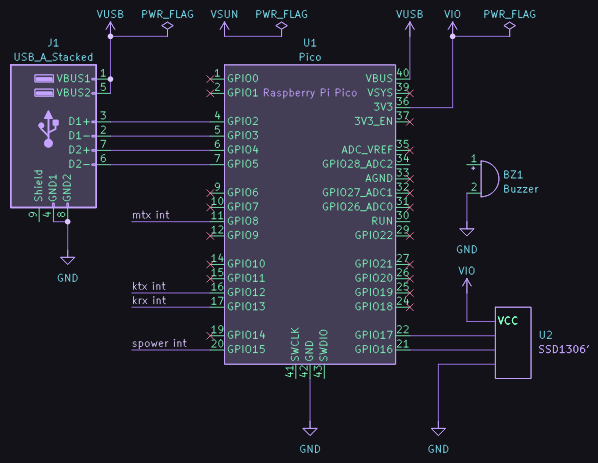
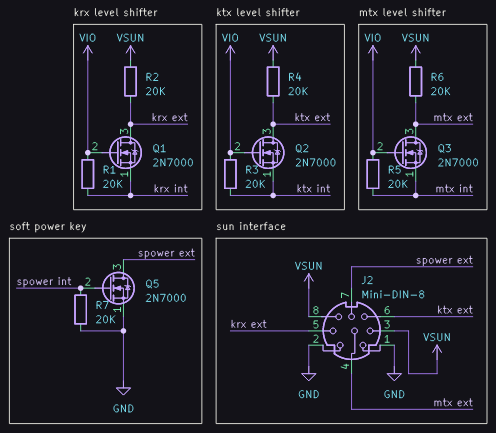
mistakes aside, i soon learned a few other lessons.
when drawing schematics, symbols can (and should) diverge from the physical pin layout where it would improve readability. if you don’t like the symbol you got from (say) snapeda, you can modify it or even draw your own!
the general convention for schematics is to use capital letters and underscores (no spaces) for net labels, and ensure all pins and wires are snapped to the 0.1″ grid. notably, this means you should always use R_Small, not R.
if you’re using kicad and sending your boards to jlcpcb like me, install jlcpcb tools. it’s a great plugin that lets you look up parts in jlcpcb’s database, save part numbers and component rotations to your schematic (though this feature seems to be broken), and generate your gerbers and other files in the correct format.
here are some other lessons i learned about
!
you should familiarise yourself with the behaviour of the “electrical rules checker”, “design rules checker”, “update pcb from schematic”, and symbol/footprint library features. playing around with them and understanding how they work will save you time in the long run.
always set up your stackup, constraints, and netclasses before you start drawing any traces. i used these settings for jlcpcb based on their pcb capabilities and pcb assembly capabilities:
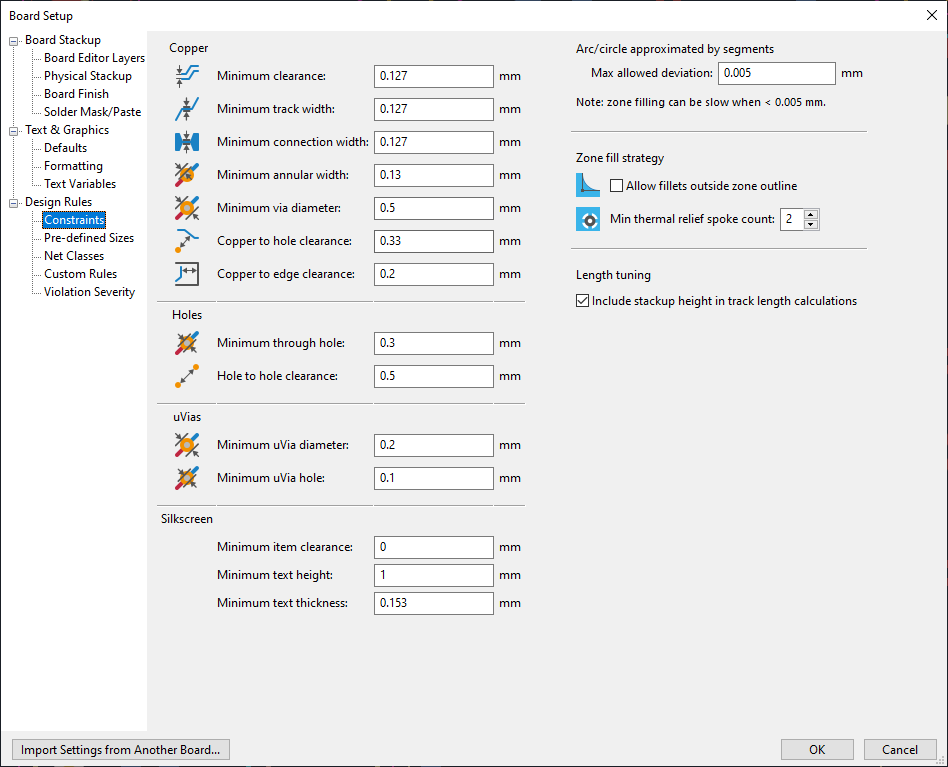
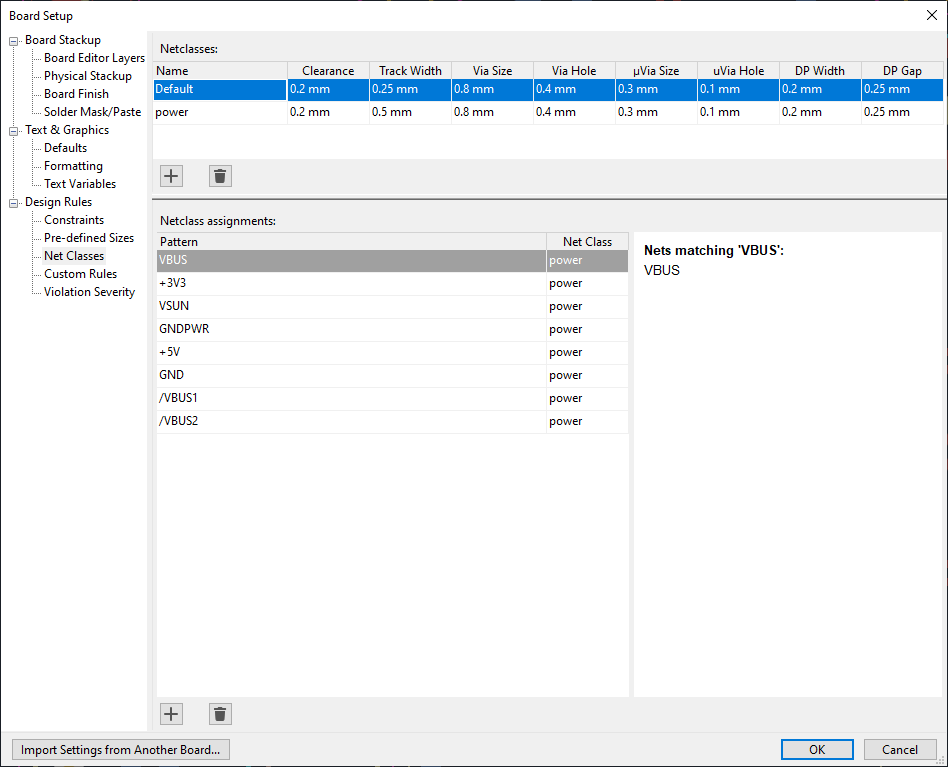
power supply traces that carry a lot of current need to be wider, to reduce their resistance and in turn compensate for the increases in voltage drop and heat dissipation.
according to this calculator, even with jlcpcb’s allegedly thinner traces of as low as 28.25 μm, we can pull up to 750mA over a 0.25 mm trace or 1230mA over 0.5 mm with only 10 °C temperature increase, and the voltage drops per inch are also acceptable for our small board.
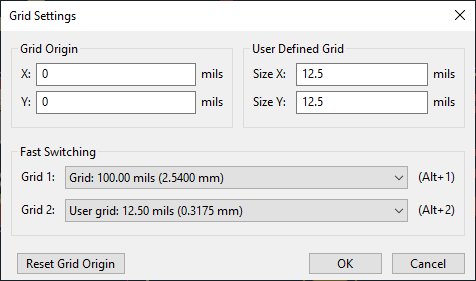
unlike schematics, pcb layouts don’t need to be aligned to a 0.1″ grid, and limiting yourself to that can make it impossible to place and route small SMT components cleanly. so despite making the board size a multiple of 0.1″ (100 mils), i laid everything out on a grid of 12.5 mils.
kicad 7 was released just as i started designing these boards. talk about good timing! two new features that i found useful for the pcb layout are “pack and move footprints” and native support for teardrops.
“pack and move footprints” helps with laying out components in high-level functional groups, which is especially valuable when you’re just starting a layout and all of the footprints are in one big pile. if you select some symbols in the schematic and switch to the pcb editor, their footprints will also be selected, and you can press P to gather them up and move them together as a group.
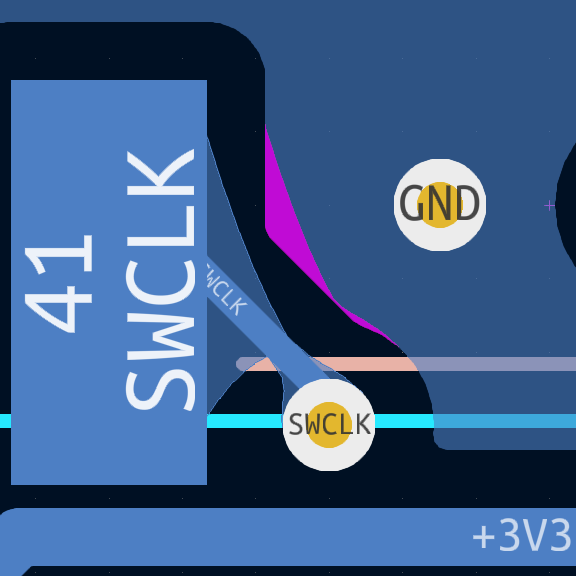
kicad can add teardrops! teardrops are a neat feature that can improve structural integrity under thermal and mechanical stress, make your pcb easier to manufacture successfully, and most importantly they look cooler.
there’s a small footgun to this though. “add teardrops”, “remove teardrops”, and “fill all zones” are all imperative operations, so you need to remember to fill all zones after you add or remove teardrops, just like you needed to after drawing any traces. otherwise you can end up with zones that get too close to traces or vias, like the copper fill shown here in magenta.
according to the pico datasheet (§ Powering Pico), we can power a pico with anything between 1V8 and 5V5, so here’s what we know:
“ORing” two power supplies is a bit more involved than just bridging them together, because when both power supplies are connected, we need to isolate them from one another to prevent backfeeding. both VBUS and VSUN are nominally 5V, but let’s say in reality VBUS was 4V9 and VSUN was 5V2. if they were bridged together, then the 0V3 potential difference would mean current would flow from VSUN into VBUS, which would be pretty rude and potentially damage the device providing VBUS.
the problem with ORing circuits is that there’s always some voltage drop. this wastes energy as heat and can eat into our voltage tolerances, creating problems if the output needs to be the same voltage as the inputs. that said, we can minimise this drop to the point where we have something that works well enough.
here are the three approaches we tried. the first two were stolen directly from the pico datasheet’s examples of how to supply VSYS from VBUS or an external supply. note that in those examples, the pico provides the diode from VBUS to VSYS, but in our case, to keep things consistent between approaches, we’ll provide our own diode and connect the output directly to VSYS.
the simplest power ORing circuit is to put each power supply behind a diode. this blocks current in the reverse direction at the expense of a voltage drop, known as the forward voltage, and we can minimise this voltage by using a schottky diode.
according to its datasheet, the MBR120VLSFT1 can block up to 20V of reverse voltage at the expense of a 0V34 voltage drop, and even if one diode’s input was at 0V and the output side was at 20V, only 15mA would leak back into the 0V supply.
we can simulate this circuit in kicad to see how the output voltage behaves at different combinations of VBUS and VSUN, by setting up the Sim Command as a DC Transfer with two sources. to get realistic results, we need to give kicad a spice model for our diodes, which we can find on the web by searching for “MBR120VLSFT1 spice model”. there are a few things to watch out for:
Source 1 gets used as the x axis, so the increment step can and should be small, but Source 2 creates separate signals (coloured lines), so a small increment step will result in many lines that will each need to be double-clicked if you want to remove them from the plot
kicad will crash if you forget to assign a model to any of the symbols in your schematic, so you’ll want to run simulations against a minimal circuit that only has the relevant components
if you use a non-spice diode symbol (read: anything outside the Simulation_SPICE library), the pins will be numbered “wrong” by default, because kicad symbol libraries use the ipc convention where pin 1 is cathode (K), but spice uses a convention where pin 1 is anode (A)
here we can see that when either of the inputs are 5V, the output will be around 4V8, and in general the output voltage is around max(VBUS,VSUN)−0V2.
if we replace one of the schottky diodes with a p-channel enhancement mosfet, we can eliminate the voltage drop on that input when the mosfet is “on”, which happens when the gate voltage is far enough below the source voltage. this minimum potential difference is known as the threshold voltage (VGS(th) or Vt).
according to its datasheet, the threshold voltage of the DMG2305UX is between −0V5 to −0V9. this is only an indication of when the mosfet will start turning on, in this case just enough for −250µA to flow through the drain. not an indication of when it will be fully on.
i measured actual voltages of VSUN and VBUS on borealis (SPARCstation 5) and a variety of usb chargers and ports. VSUN was 5V2, while VBUS was generally between 5V0 and 5V1, so i decided VBUS needed the mosfet more.
we can simulate this circuit, and just like before, if you use a non-spice mosfet symbol (read: anything outside the Simulation_SPICE library), the pins will be numbered “wrong” by default, because kicad symbol libraries use the ipc convention where pins 1-2-3 are gate-source-drain (G-S-D), but spice uses a convention where pins 1-2-3 are drain-gate-source (D-G-S).
here we can see that when VSUN is zero (red), the output will equal VBUS as long as VBUS is at least 0V9, and when VBUS is zero (green), the output will be around VSUN−0V2, but when VBUS is 5V (purple), the output drops below VBUS as VSUN reaches 4V1 and stays that way until VSUN reaches 5V2.
let’s look at why the output changes so much when VBUS is held at 5V:
these simulations were all done with R1 at 1kΩ, which at 5V is only 5mA. if we used a more realistic current of say 200mA (25Ω), the output voltage drops by as much as 0V6 when VSUN is close to VBUS. at a more extreme current of 1A (5Ω), it drops by as much as 0V7, and we even start to see up to 0V1 voltage drop while the mosfet is on due to its RDS(on)!
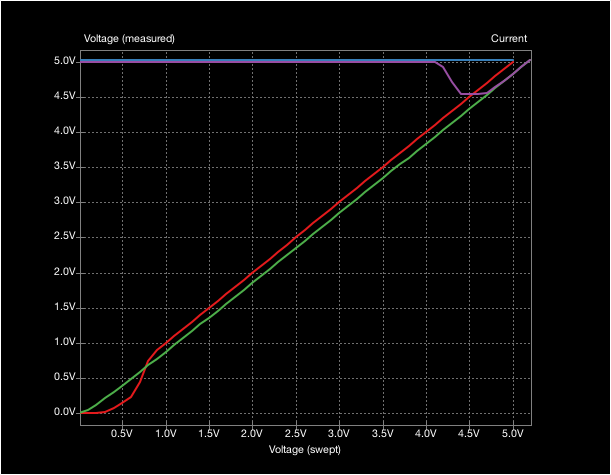
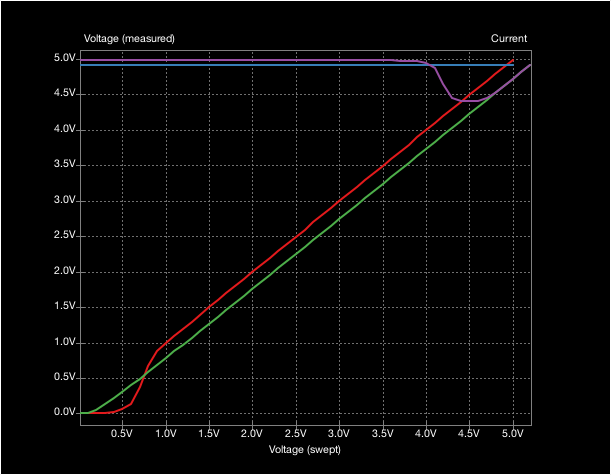
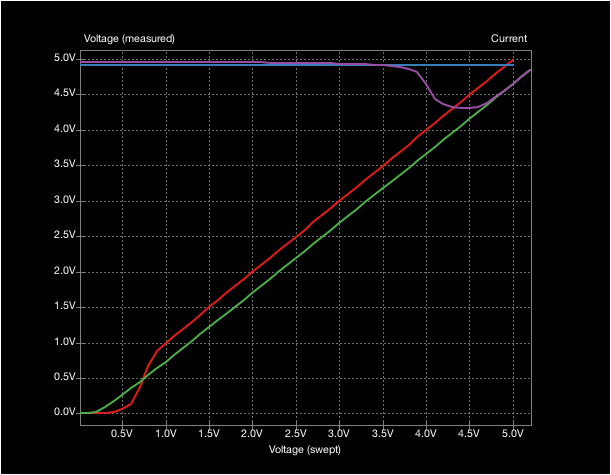
ultimately it’s not a great idea to rely on the favourable characteristics of one particular workstation. instead we want to maximise our performance under nominal voltages and tolerances.
we can do even better than this by using an “ideal diode” like the MAX40200. these are designed to be used like a schottky diode for ORing, but are actually a mosfet with a comparator under the hood. this is related to active rectification, which is pretty much the same technique applied to AC-to-DC conversion.
as long as the load current is reasonably low, the voltage drop of a mosfet (Iload × RDS(on)) can be lower than the (roughly stable) voltage drop of a schottky diode. this also improves efficiency at low voltages, because a schottky diode that drops 0V3 at 5V is a 6% loss.
you can learn more about ideal diodes in this 25-page paper by texas instruments.
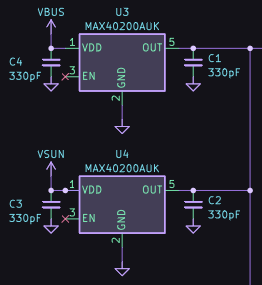
per the datasheet, we need at least a 330pF capacitor on the input and at least a 330pF capacitor on the output.
i wasn’t able to get the vendor’s simulation model to work in the spice that comes with kicad, but we should still be ok to use it as long as we read the datasheet carefully like we would for any component.
replacing our gpio-based usb host ports with otg-based ports that use the rp2040’s native usb hardware might make our usb support more reliable, but there are two issues that affect our design either way, at least in terms of compliance.
one is the
.
usb host ports, including the ports on usb3sun, need to supply a VBUS between 4V75 and 5V50. our power supply design means that the input we receive from a workstation or external debugger needs to be at least 4V75 plus the voltage drop of our ideal diodes, which can be up to 175mV at 1A.
in theory, our host ports would be non-compliant if we expose the micro-usb port in a future revision (§ next steps) without any other changes, because then we could be a usb device when powered externally. and as a device, we can only expect 4V375 on our upstream VBUS, or 4V625 if we have permission to draw 500mA. oh yeah, did you know usb devices are supposed to ask before drawing more than 100mA?
to be honest, i think our host ports are already non-compliant. for example, the sparc keyboard spec doesn’t define the voltage and current limits of its +5V pins, and without any limits, we have no way of knowing whether +5V is at least *tap tap tap* 4V925.
afaict the only way to make them compliant is to replace the ideal diodes with a proper voltage regulator that can boost the input if necessary, but i’m also not sure this matters too much in practice.
the other is
.
on the spectrum of performance and complexity from like… serial to pcie, usb is somewhere in the middle. usb 2.0 can be kinda fast and kinda tricky to get right, but it’s generally not too difficult.
the usb data lines are a differential pair, which for reasons beyond my understanding need to be routed carefully. generally this involves:
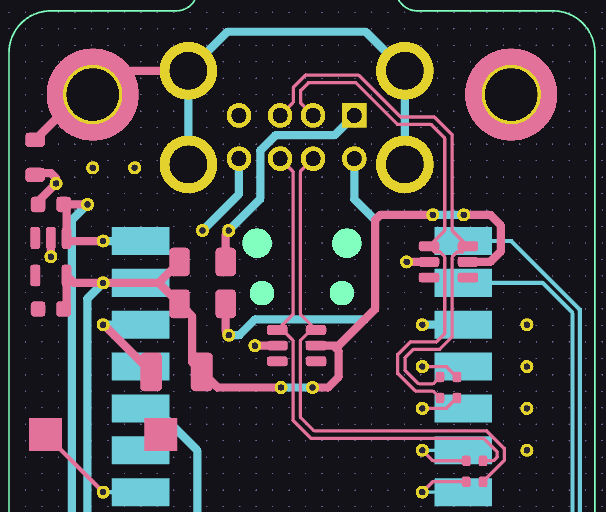
this is very important for high speed usb, but our host ports only support low speed and full speed, so this probably doesn’t matter too much. that said, i did my best to route the pairs as if we needed to support high speed, if only to learn how to do it.
i used kicad’s “route differential pairs” (6) tool for this, and it worked well enough once i started holding Ctrl to disable grid snapping at all times. when grid snapping is enabled, kicad tries to ensure that the destination under your cursor is both aligned to the grid and satisfies the differential pair routing rules, and the intersection between these sets of points is often zero.
you can learn more about routing usb in this post (and video) by zachariah peterson, or this video by cole brinsfield:
https://www.youtube.com/watch?v=aAqJYWu5Y8c
unlike the breadboard prototype, the pcb versions of usb3sun have components that protect against excessive current draw, both during normal operation and during a fault, plus electrostatic discharge and electromagnetic interference.
excessive current draw during normal operation can cause the power supply voltage to drop, which can negatively affect other components that depend on that rail.
putting a 100uF bypass capacitor on +5V, parallel to (and near) the trace that feeds VBUS1 and VBUS2, allows devices connected to the usb ports to satisfy brief spikes in their current draw without disturbing the voltage of the +5V rail, since they can instead draw most of that current from the capacitor.
the flipside of this is that the capacitor needs to draw current to charge itself, which can create a spike in current draw when initially powering up the adapter.
you can learn more about this in the usb 2.0 spec (usb_20.pdf § 7.2.4.1).
excessive current draw during an electrical fault can damage power supply traces and other components like the current switches (ideal diodes). this can happen if a device connected to one of the usb ports malfunctions, which is probably rare, but it can also happen in more likely situations, like a misplaced screwdriver in one of the usb ports shorting its VBUS{1,2} to ground.
to protect them against this, we use two polyfuses, one on VBUS1 and one on VBUS2, that are each guaranteed to trip at ≥1A (the trip current) and guaranteed not to trip at ≤500mA (the hold current). the latter value is notable for usb, because ordinary usb devices are not permitted to draw more than 500mA at any time.
unlike an ordinary fuse, polyfuses generally don’t need to be replaced when they trip, though they can take a long time to fully reset back to their original resistance (if at all).
electrostatic discharge can induce voltages far beyond the limits of many of the components, such as our ideal diodes which are only rated to 6V. to protect our circuit against this, we need esd protection diodes.
for the sun interface, we use the ESD5Z5V0, a tvs diode that protects VSUN by shunting any excess voltage beyond 6V to ground. this tvs diode is unidirectional though, so it won’t protect VSUN against negative voltages, and for now we haven’t protected the data lines.
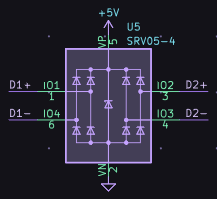
for the usb interfaces, we use the SRV05-4, which protects VBUS and the four data lines by combining a tvs diode with four pairs of steering diodes. the tvs diode protects VBUS unidirectionally, the lower steering diodes shunt negative ESD voltages to ground, and the upper steering diodes shunt positive ESD voltages to VBUS, which may in turn get shunted to ground via the tvs diode.

to protect the usb ports from high-frequency electromagnetic interference on the order of 100 MHz, we use a ferrite bead (GZ2012D601TF) between the shield and ground.
unlike the other protection features, i don’t understand this one too well, and it was also unclear to me what the best practices are for emi protection on usb ports, so i borrowed the approach used here from the unified daughterboard, another keyboard-related usb hardware design.
you can learn more about emi protection for usb hardware in this 19-page paper by intel. notably it seems the best practices vary depending on whether you’re running at low speed or full speed, whether you are a host or device or hub, and whether you have a board-mounted receptacle or a captive cable.


i sent rev A0 to the board house and it worked perfectly! the design was correct to the best of my ability, so this wasn’t unexpected, but the first revision is always nerve-wracking, more so when it’s your first ever pcb design.
the improvement in ergonomics by moving from the breadboard prototype to a proper pcb cannot be overstated. with the breadboard, wires would come unplugged all the time. this can be scary when it’s ground and an external debugger is attached, because i’ve seen potential differences of as much as 55V between the two power supplies when that happens.
that said, the usb host ports didn’t work at first. and with the usb stack we’re using, it really helps to have access to UART0 for debug logging, but i forgot to expose pins for that anywhere, so i had to solder a bodge wire. more on that in § usb shenanigans.
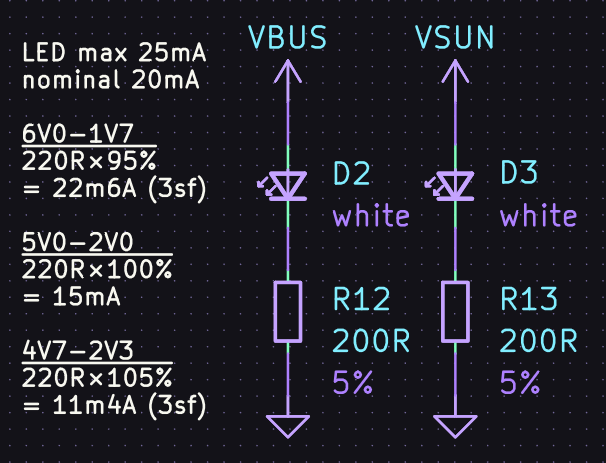
this design uses the same kind of four-pin module for the oled display as the prototype, which you can find countless clones of on aliexpress under “ssd1306 0.91”. this is easier to solder by hand than the eight-pin flexible ribbon version, which is important since jlcpcb doesn’t stock either of them (so they can’t assemble it for us).
there was nothing to support the end of the module opposite the header though, which makes the board unnecessarily fragile. i haven’t tried, but i think a misplaced finger could easily snap the solder joints, and potentially even rip the pads off the board.
debugging the usb stack was tricky. for one, attaching a debugger affects timing, which can make downstream devices appear to disconnect. and any upstream usb connection would use the same usb stack, so you can’t use the usb-cdc-based serial console for debug logging, since that would be a circular dependency.
as a differential diagnosis, i uploaded the same firmware i was using for testing to my (known good) breadboard prototype, and the usb ports stopped working there too. armed with the suspicion that it was the firmware’s fault, i found that the new firmware, built over three months later, used updated dependencies that led to some regressions.
one of them was that for reasons that are not yet clear, we stopped getting hid-related callbacks from the usb stack. the other was partially our fault. we had a workaround for a bug that was fixed upstream, and the workaround and the fix did pretty much the same thing. that thing wasn’t idempotent though, and doing it twice causes a panic.
i think the takeaway here is that you should always pin your dependencies to avoid unexpected regressions (and make builds more reproducible). this is currently easier said than done, so for now we only pin our direct and/or usb-related dependencies.
the next (and current) revision fixes most of the shortcomings of rev A0, adding debug header pins for UART0, a 3d printed support to prop up the display module (§ supporting the display), and tactile switches for reset and “hard” power key.
rev A1 also polishes the pcb layout in a bunch of ways:
@ariashark also suggested i add some led indicators to check the state of the two input power supplies, independent of whether the firmware is running. i have two opinions about leds, which are closely related:
i picked the elegantly named 19-213/Y2C-CQ2R2L/3T(CY), a yellow led, in the hope that heeding the latter would also take care of the former. leds need their current limited externally or they will be damaged, and their brightness increases when the current increases. based on the nominal and maximum current ratings, i chose a resistor value that would yield 15mA normally and 23mA in the worst case.
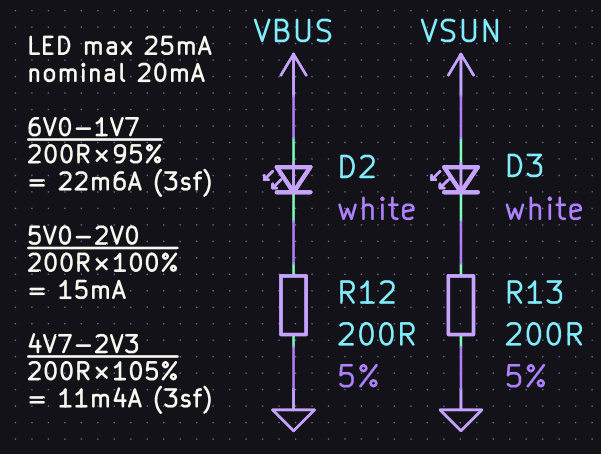
i regret to inform you, my dear reader, that yellow leds can still be too bright. 0402 resistors are too small for me to swap out by hand, but i fixed the overwhelming brightness of the leds by blacking out the top of the packages with a marker.



rev A1 adds two mounting holes under the display module to hold some kind of support. since @ariashark had recently set up our new 3d printer, this was a great time to design and print my very first model.
at first i thought i would need to make the support clip into the pcb. i decided to go with simple cylindrical posts, because it needs to be flush with the bottom of the pcb, and besides, there’s no real way it can fall out once the display module is assembled.
i ended up drawing the model twice, once in fusion 360 and once in freecad. fusion 360 is apparently what most people use to draw 3d printing models, but i honestly kinda hated it, and i would argue it detracts from the open-source-hardwareness of usb3sun. both models printed equally well, but i only bothered pushing the freecad model to github.
my first experience with
was being forced to create an account and log in to use this piece of software that i had just installed on my computer. this is ostensibly for licensing reasons, since you can only have 10 files on a free licence, but to me this is almost as bad as nvidia asking you to log into your fucking graphics driver.
it takes 31 seconds to launch on my computer, excluding opening any file, and locks up for several seconds every time you open or save a file, which is indefensible when i have a ryzen 7950X. the ui widgets flicker randomly for no good reason, and the whole thing just feels janky.
i have no idea why anyone would pay money for this.
was not a panacea either.
the documentation is pretty lacking, so i had to rely on forum posts to answer basic questions like “how do you define a constant?” or “why can’t i extrude this face?”. and the latter didn’t even really help, because it was actually about scripting freecad with python.
the extrude tool took me a while to figure out. i wasn’t able to just extrude the shapes i drew in the sketcher, because i first needed to “make face from wires”. due to a minor ui oversight, i wasn’t able to use variables in the length until after extruding with some arbitrary length. i also needed to punch in direction vectors by hand, which was surprising given that all of the points in my sketch were coplanar.
one thing that’s fun about freecad is how you define constants. unlike “change parameters” in fusion 360 — not to be confused with “edit parameters” in freecad, which is a settings editor — they implemented a whole-ass spreadsheet feature, which means you can organise your constants and format your flavour text to your heart’s content, or even split your constants across multiple spreadsheets!
that said, i feel like parameters in fusion 360 get you 70% of the way for like 20% of the effort. parameters can still refer to other parameters, and you can still organise your constants by giving them prefixes and comments, and you don’t have to type “<<Spreadsheet001>>.” before everything, so overall those seem more ergonomic.
usb3sun is more or less done, but there are still a few improvements we can make.
changing the values of the led resistors from 200R to 680R will reduce their luminous intensity from ~80% down to 15% (relative to 20mA), which should be a lot more comfortable to look at without needing modification during assembly. note that every rev A1 unit will ship with its leds modified in this way to limit their brightness appropriately.
the microcontroller can toggle SPOWER with a low-side mosfet switch, but it can’t yet read the state of SPOWER, so we can’t send the make (30h) and break (B0h) codes for power when the “hard” power key is pressed.
many of the parts on the bill of materials are considered “extended parts” by jlcpcb, which incur extra fees because someone has to physically load a reel into the pick-and-place machine. finding alternative “basic parts”, which are always kept loaded, would reduce the cost of making these adapters.
it’s difficult for the end user to update the firmware, because the micro-usb port isn’t physically accessible after assembly, so you need a picoprobe and debug tooling. there are three ways we can make this easier, in ascending order of effort:
adding another micro-usb port — the pico has test points for the usb port on its underside, which we can line up with small plated holes and fill them with solder. we would need to reroute D1+ and D1−, and it might complicate the routing a bit.
over-the-air updates — we can load a firmware update over UART0, or even easier, from a usb mass storage device. this wouldn’t require any hardware changes, but i have no idea how well this would work in practice, plus you wouldn’t be able to use this if the existing firmware is hosed.
embedding the rp2040 directly — we can “inline” the microcontroller and everything it needs into the pcb, eliminating the pico and allowing us to move the micro-usb port anywhere we want. this would probably make the adapter cheaper and easier to assemble, but redrawing the schematics and pcb layout would take me at least 30–50 hours, which is only worth doing if i sell more than like 3–5 units.
if you think you’ll find usb3sun useful, and you’re ok with the limitations of rev A1, consider buying one on tindie! we’ve already sold two three, but there’s currently one in stock and one being assembled. after those, we’ll need to order and assemble another run.
did you love this? hate this? have any questions or comments? please let me know in the comments below, or on mastodon or twitter!

![“ariashark also suggested i add some led indicators to check the state of the two input power supplies, independent of whether the firmware is running. i have two opinions about leds, which are closely related: most leds on consumer electronics are too bright [and] blue leds are the spawn of satan (derogatory)”](/posts/attachments/1daea606-4cbd-48c5-8db6-7cf57c068b1d/image.png)
usb3sun is an adapter that lets you connect usb keyboards and mice to old SPARCstations.
i wrote about the prototype version back in january, but since then i’ve turned it into a proper pcb, and after a couple revisions it’s more or less ready for sale!
stay tuned for the full writeup :)




why is the left lane blocked in this one, but not that one?
the yes men fix the world (2009)





this chost was chosted purely for a support ticket, since i would much rather subject everyone to its existence forever than have it clog up my post hole forever :3
binary snack pack (bsp)
constraint snack pack (csp)
digital snack pack (dsp)
internet snack pack (isp)
java snack pack (jsp)
kerbal snack pack (ksp)
language snack pack (lsp)
retail snack pack (rsp)
travelling sn
![Ian [Jackson]: “In summary, the security and bug history of systemd is worrying.” / Evidence > “systemd security bug list” > “Hi Ian, Here’s the email about systemd security holes that I kept forgetting to send you. I hope it’s (still) useful. […]”](/posts/attachments/29408d2f-5a75-4f22-bff3-58aac3eedbe4/Untitled13.png)
, a nine-part series
http://aaonline.fr/search.php?search=&criteria%5Btitle-contains%5D=Debian+init+case

i asked my old gp for a copy of my patient record in the same xml format they use for transfers. like many gp places in australia nowadays, they use best practice (bp premier).
anyway here’s a rudimentary viewer for bp premier xml patient records:

in australia, you have the right to access your records from any medical practice you have been a patient with, under the privacy act 1988.
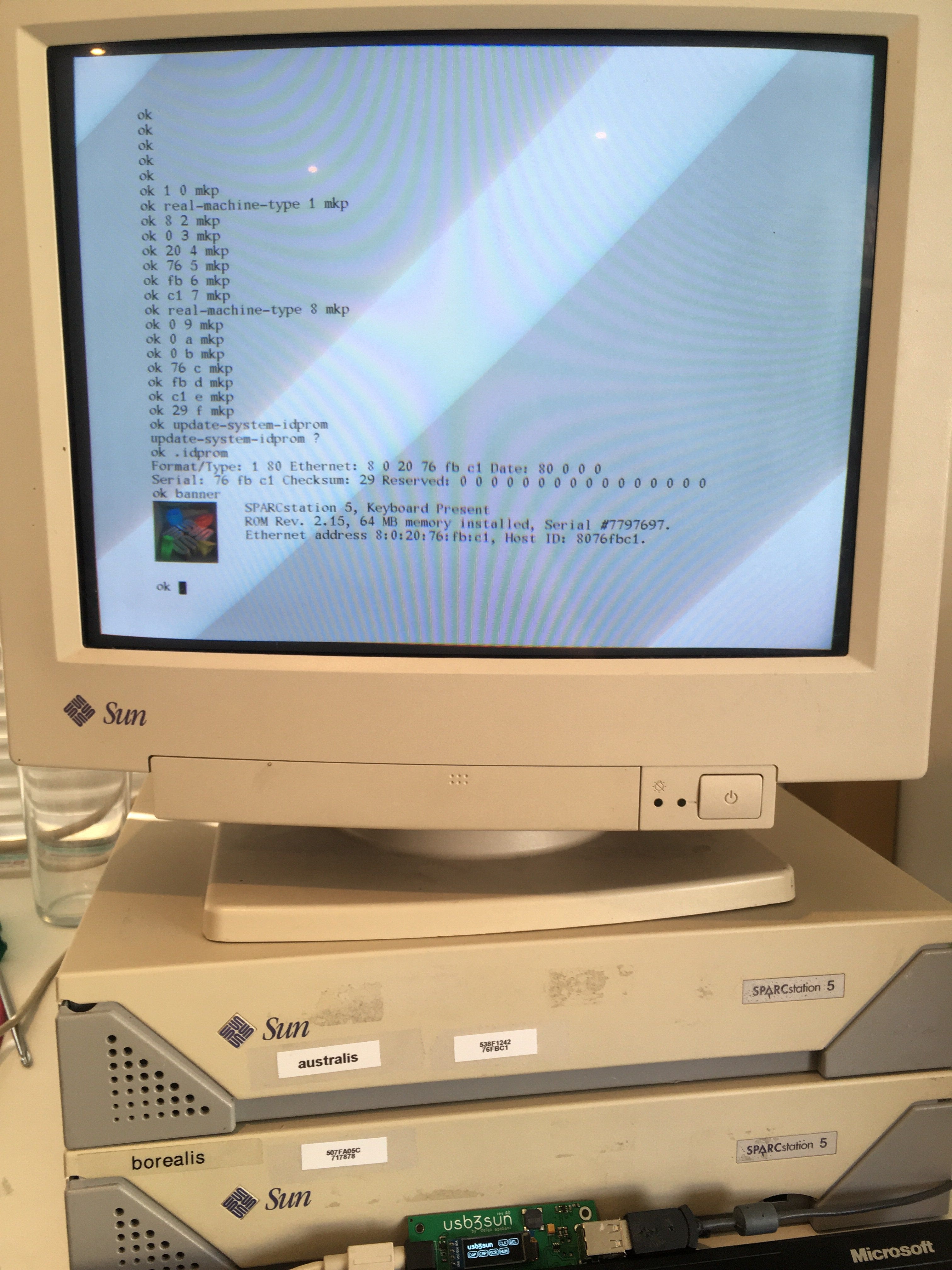
previously we explored borealis, one of our SPARCstations 5. we replaced a tantalum cap, ironed out a bunch of bugs in usb3sun, hacked together a macro to help with idprom reprogramming, installed solaris 7, connected to the internet, and grabbed our first screenshots of the machine running hotjava and netscape 4.
since then, we’ve (+bn) made some repairs to the SS5 cases, booted the two IPC lunchboxes with dead power supplies for the first time, installed NeXTSTEP on borealis, and found traces of a possible history before even its previous owner.
SPARCstation 5 cases have a top cover that lifts at the back and hinges at the front, with three hooks coming out of the ABS that mate loosely with holes in the front of the metal chassis.
unfortunately, it’s very easy for these hooks to get stuck on something and snap off while opening or closing the lid, to the point where we had broken almost all of them over the course of our tinkering. in fact, we still haven’t figured out how to reliably avoid doing so, though it probably doesn’t help that i’m a pretty clumsy person. old ABS is also inherently brittle, as any collector of 90s computers (especially apple computers) can attest to.
to repair these hooks, we used super glue (ethyl cyanoacrylate) with isopropyl alcohol as a primer. retail adhesives often lack any details about their ingredients on the packaging, but you can generally find out online by looking up “<retail name> msds”.


back in part 1, we found that our two IPC lunchboxes had power supplies that were destroyed by leaky caps, so we were unable to boot them. and unlike the Ultra 5, the IPC power supply is not ATX-compatible, so replacements are hard to find.
the IPC uses the same 12-pin interface as the one in the SPARCclassic datasheet (§ B.15), which unlike the 18-pin SS5 interface (§ 4.2.1) can’t be switched on and off by the mainboard. despite the different pinouts, IPC and ATX power supplies use the same style of connector (molex mini-fit jr), and the pinout appears to be a subset of ATX 20+4 (assuming POK = power good), so what if we could repin an ATX power supply without needing to recrimp any wires?
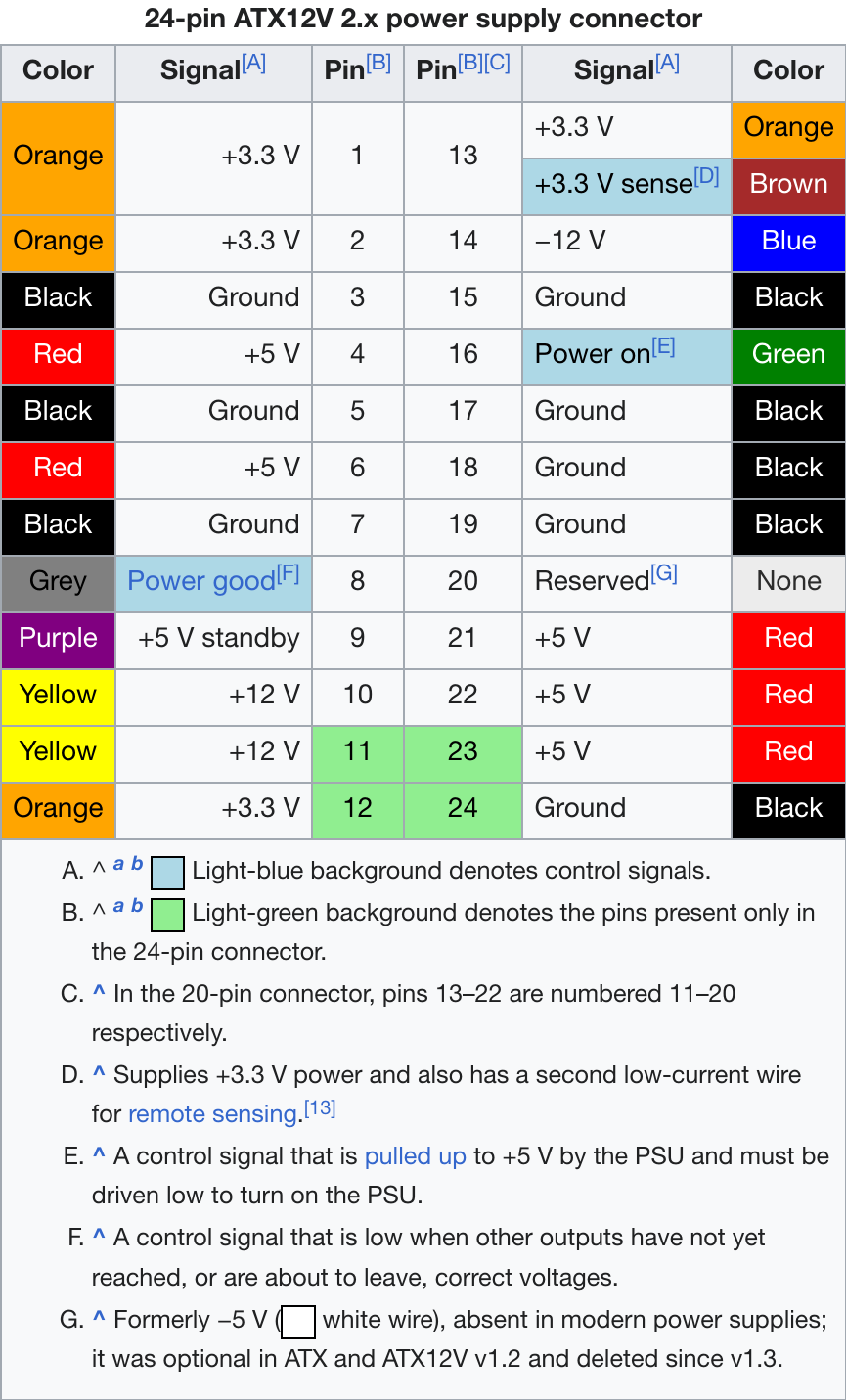
you can get an official mini-fit jr extraction tool for around 40 AUD (26 USD), but instead we found a guide to removing these pins with just two staples. getting enough of a hang of it to remove the first pin takes some patience, but it soon becomes fairly easy.


with an empty IPC housing and the corresponding wires extracted from the ATX 20+4 connector, all we had to do was push the wires into the housing, making sure to orient the open side of the terminals up towards the thumb latch. but the power supply refused to operate with its grey “power good” wire connected to the POK pin on the mainboard, with the PSU fan pulsing briefly then shutting off.


suspecting an overcurrent protection fault, we tried again with the POK pin unconnected, and both machines booted! this is not ideal, because it prevents the mainboard from knowing if the power supply is actually ready and operating at the correct voltages, but it’s a start.
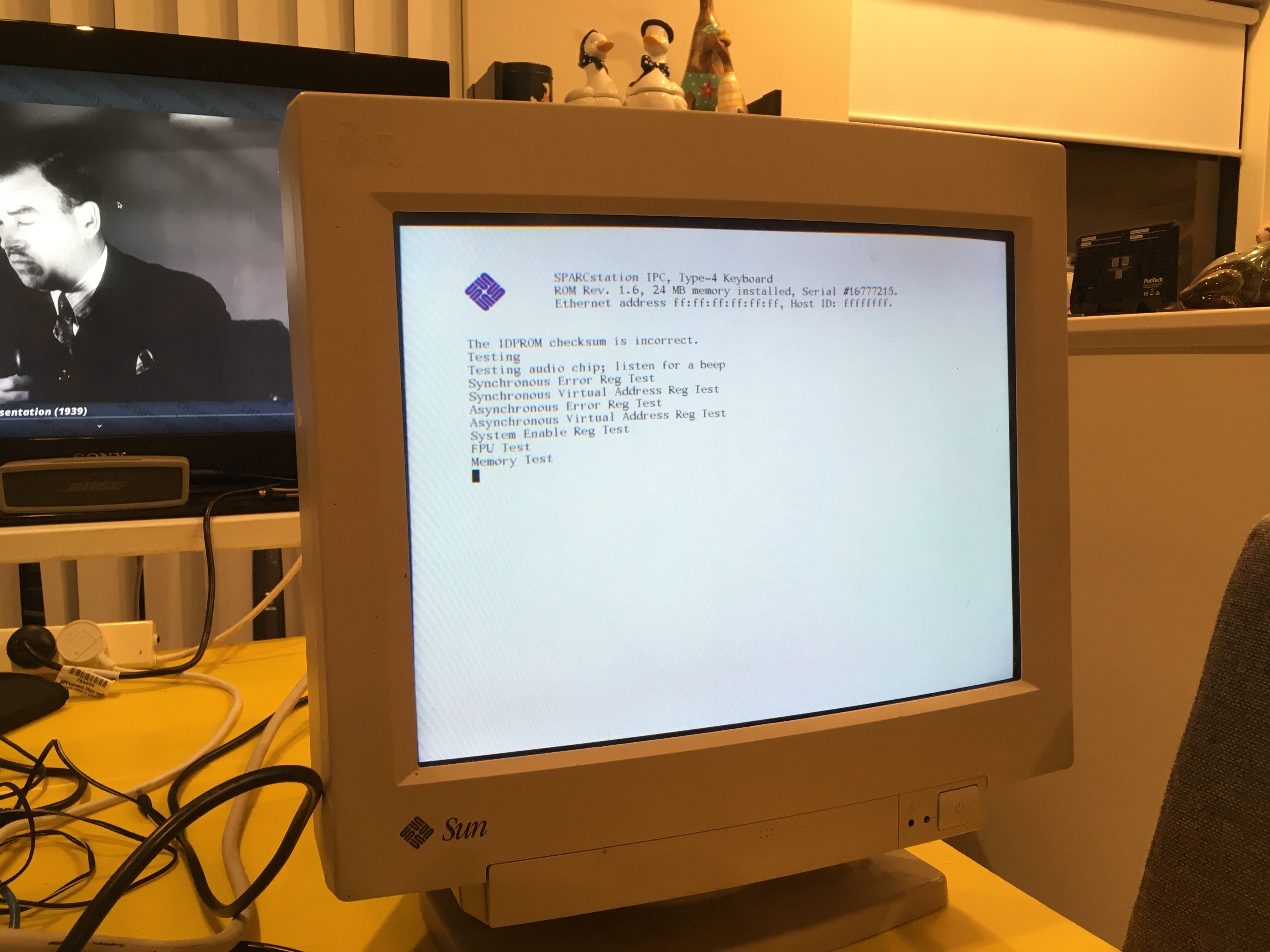
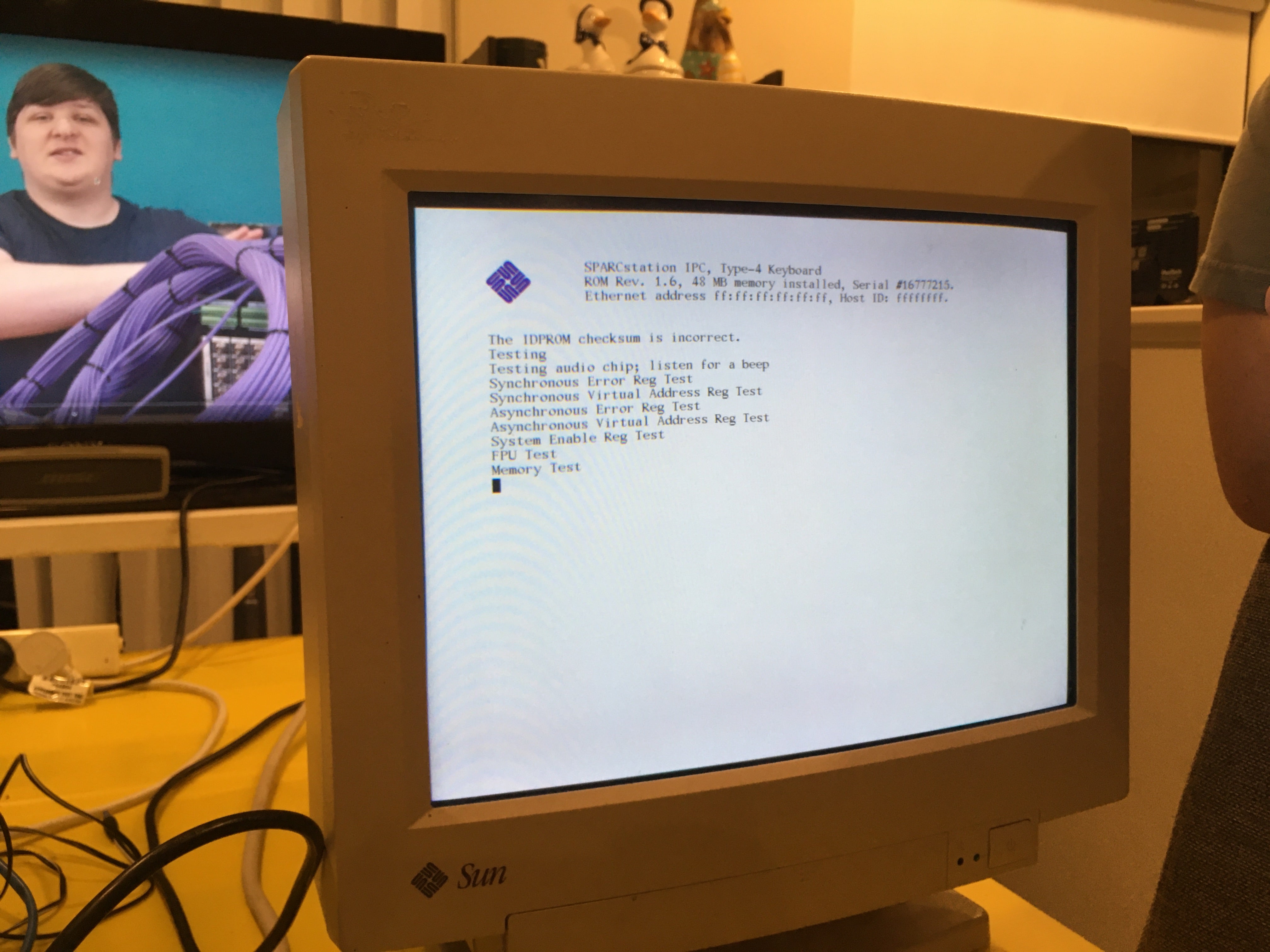
we weren’t able to boot from any of the scsi hard drives in our sun machines though. the drives show up on the bus, but any attempt to boot from them would yield “not responding” errors. that said, it’s entirely possible we were using the wrong syntax.
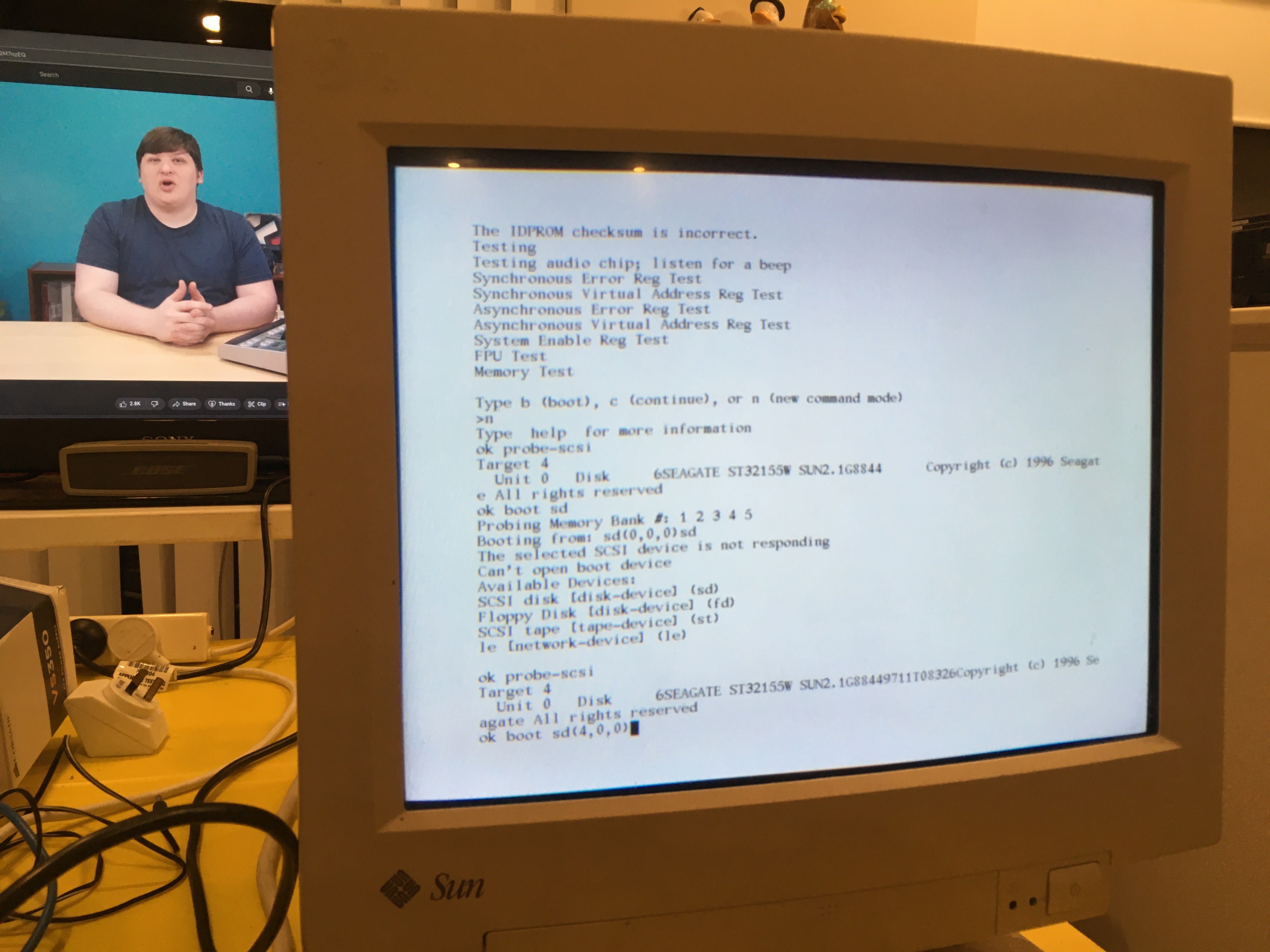
it would be great if we could find an optical drive for these machines, because without one we’re limited to booting off the hard drive or floppy disks.
sun4m machines like the sparcstation 5 can run solaris, netbsd, openbsd (up to 5.9), and linux (in theory), but did you know they can run NeXTSTEP?
yes, the operating system by the same NeXT whose workstations were used to develop doom and the first web browser.
you see, between 1991 and 1993, NeXT pulled out of the workstation market and went software-only. they ported NeXTSTEP to other platforms, starting with the pc in version 3.1 and then pa-risc (hppa) and sparc in 3.3, the final version.
since our ss5 pizzaboxes happened to each have a compatible cpu, we were able to try it on one of those. we picked the slower 70 MHz borealis, since we wanted to save the 85 MHz (now australis) for a long-term solaris 2.5.1 install.
booting the disc we burned, we got random read errors and a weird “Watchdog Reset” error each time. cleaning the disc got rid of the read errors, but not the watchdog reset, so we burned another. watchdog reset.
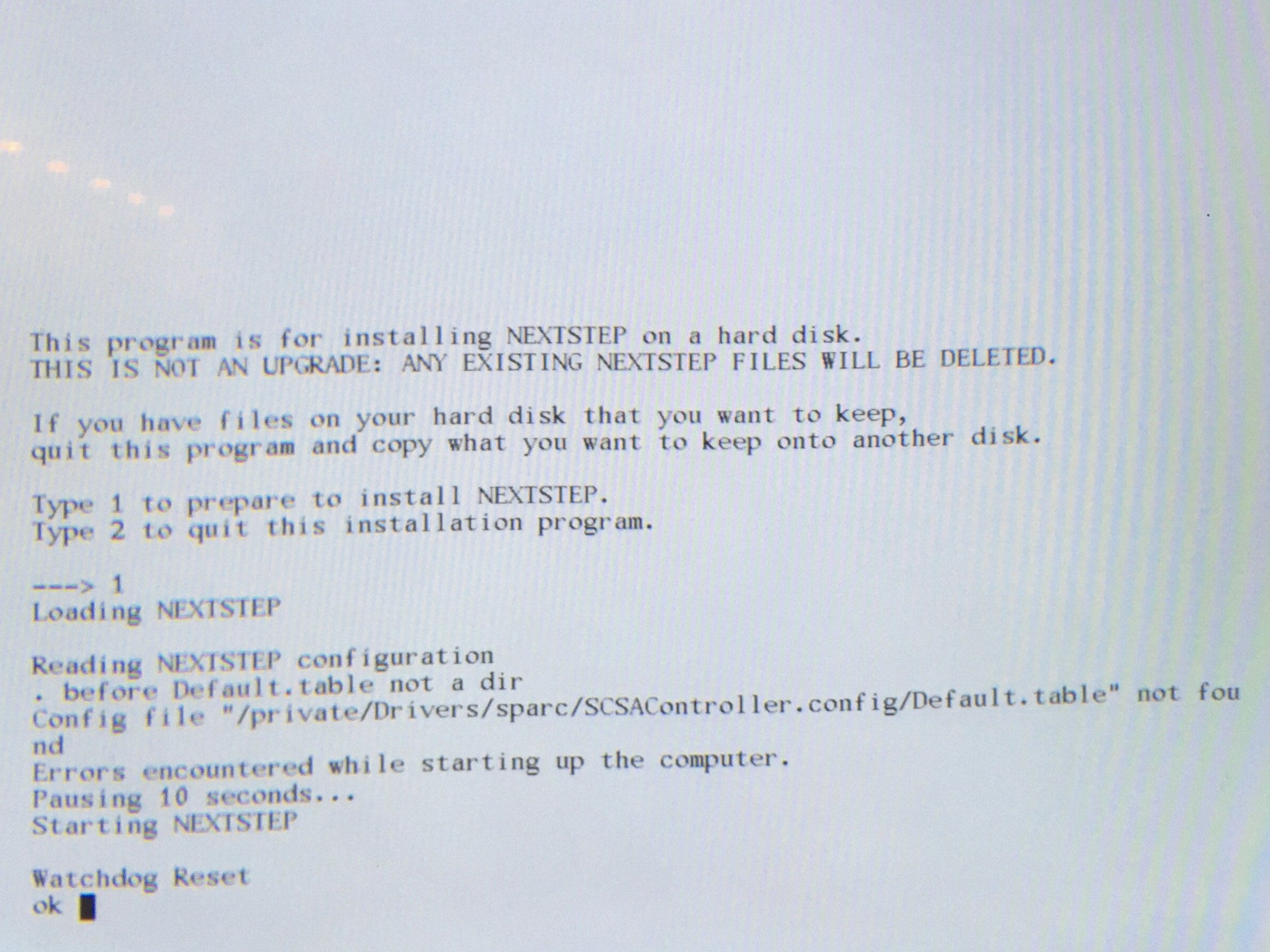
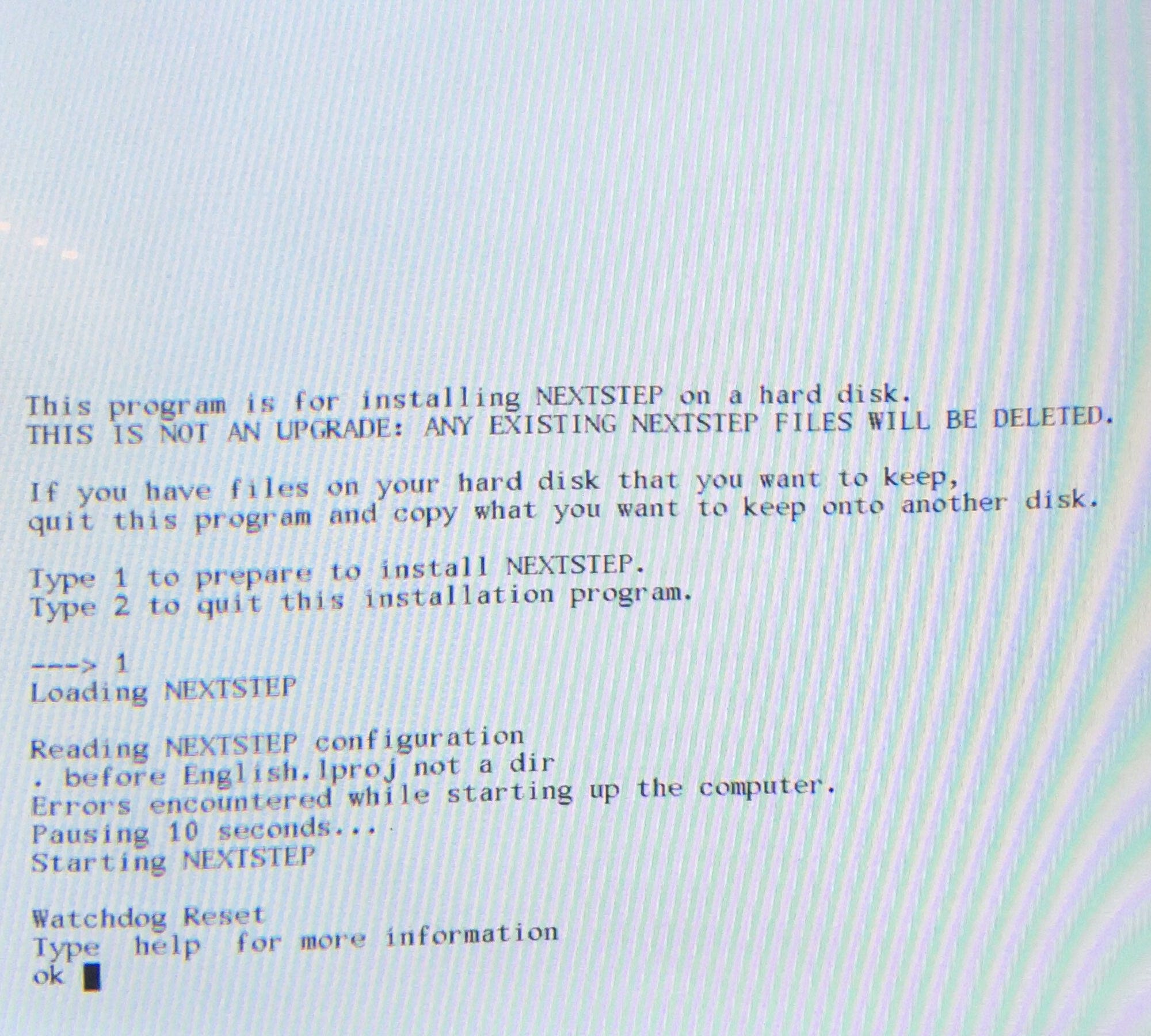
eventually i remembered that a corrupt idprom breaks networking in solaris, because it makes the machine’s default mac address invalid, so by analogy, programming the idprom might help here. on our first attempt, it didn’t help, but when we tried again and booted the installer in verbose single-user (-v -s), we got to a shell!
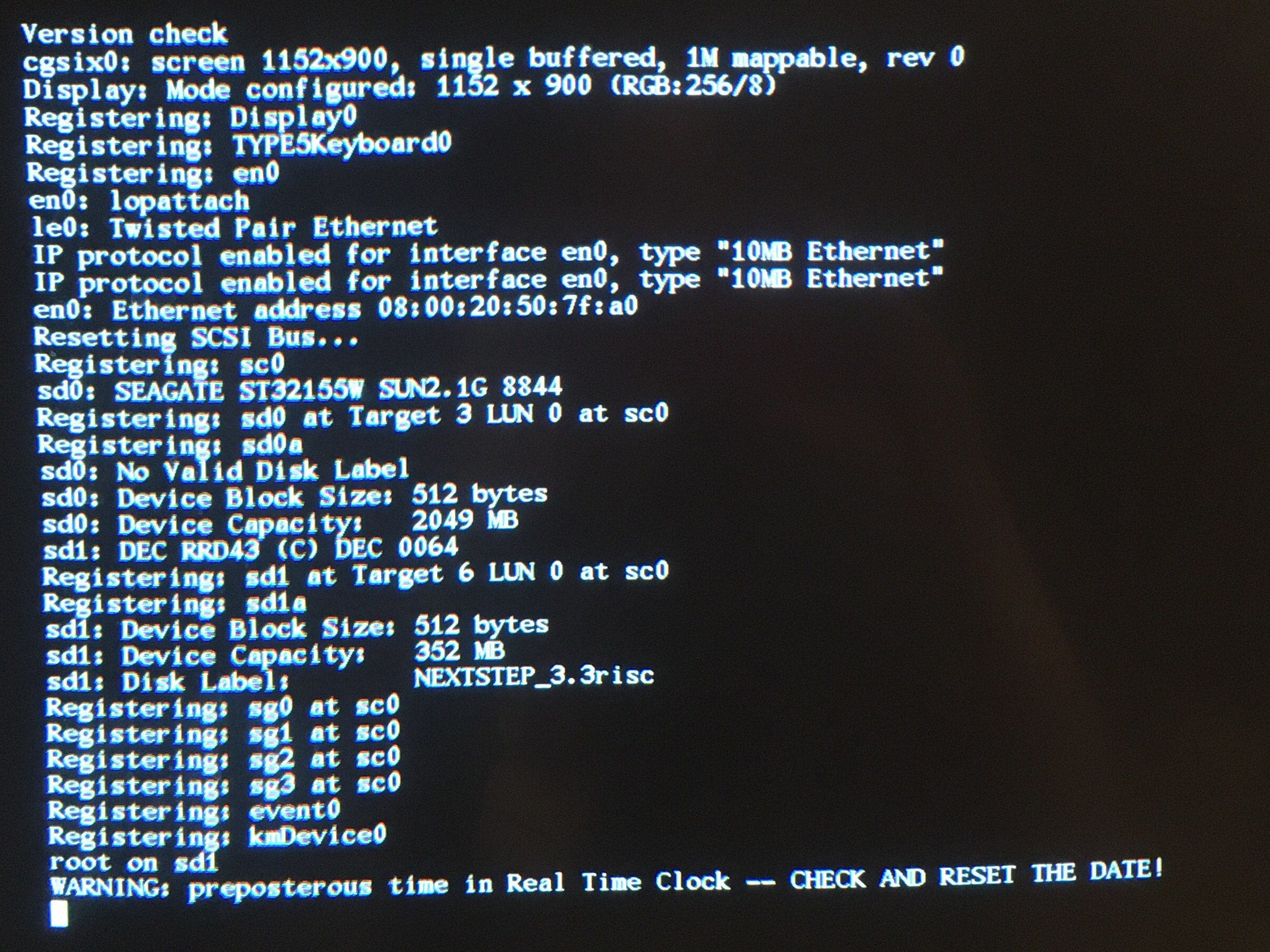
on the fediverse, we learned that nextstep is known to refuse to boot on sparcstations when the idprom values are invalid. thanks Michael Engel!
with the installer now booting correctly, we finished what we later found out was just the text-mode phase, copying a bunch of files over the course of twenty minutes or so.

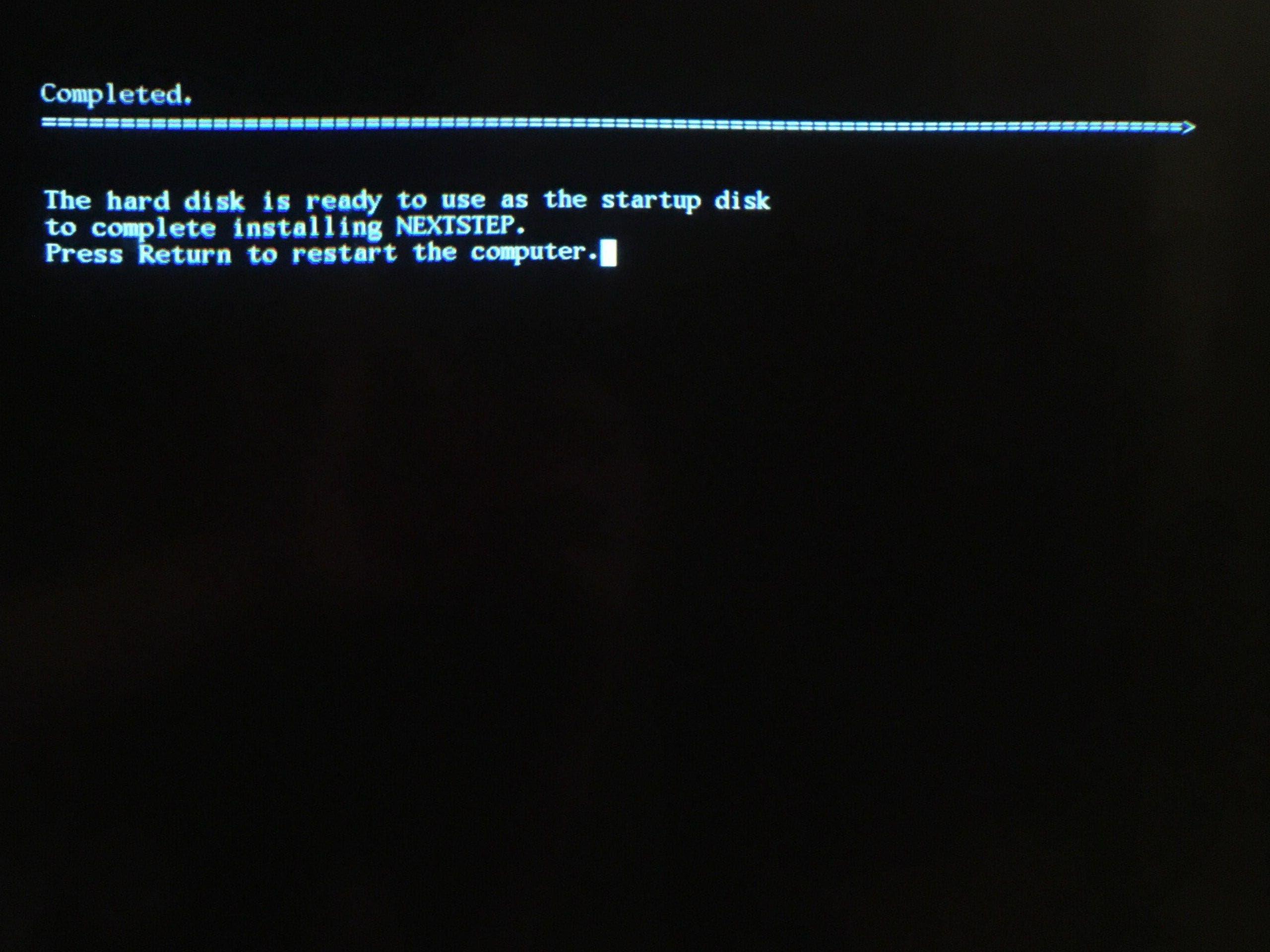
you see, there was also a graphical phase, which added well over an hour to that.
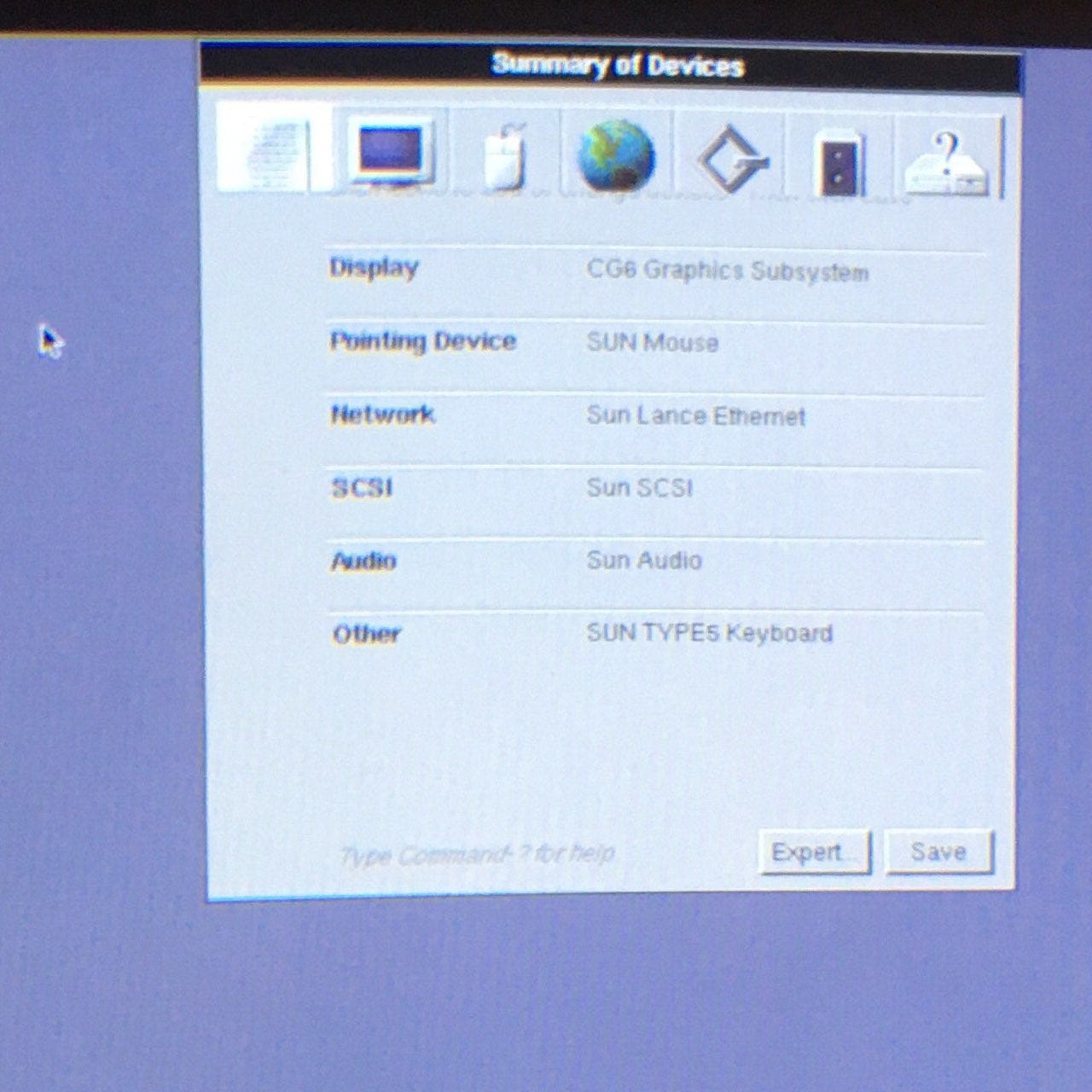
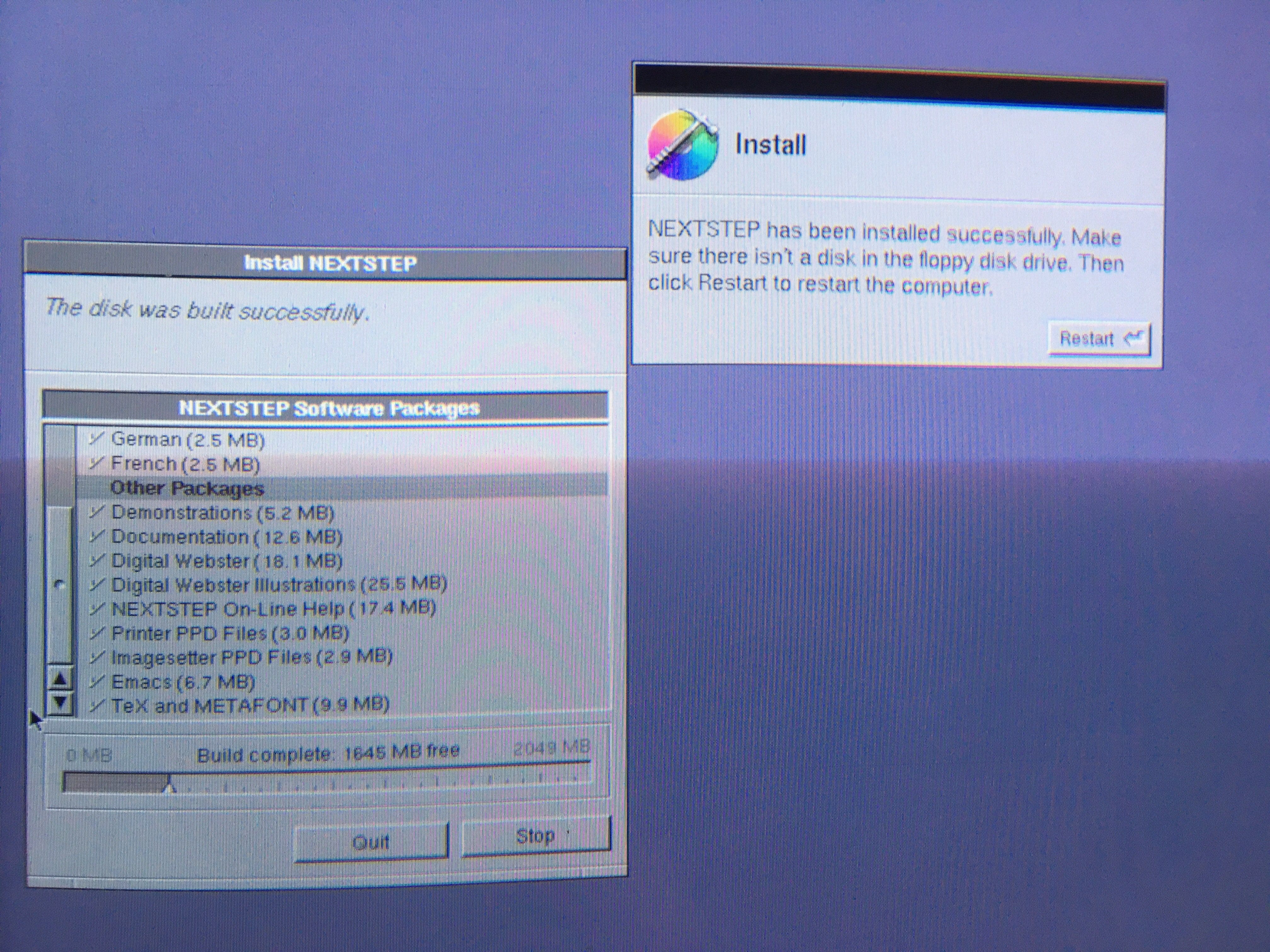
nextstep is a lot like macOS 10, because after apple acquired NeXT, they rebuilt said successor to mac os 9 on top of it. this reminds me of how microsoft forked “nt os/2” and rebuilt the future of windows on top of that, after pulling out of their collaboration on os/2 with ibm.
as a result, many of the distinctive features of macOS 10 like



actually came from nextstep. but the influence went both ways:
existed in both nextstep and older versions of mac os!
one way to make sense of this is to look at the birth and death of NeXT. it was founded by one of the old co-founders of apple, who had (at the time) recently been forced out, and many of the workers that built it were also ex-apple. so NeXT was essentially a fork of apple, and in 1996, it returned from whence it came.
this is not the only time a radical fork has been reintegrated upstream. gcc, the c compiler sharing a name with the free compiler suite it was the heart of, got forked as “egcs” in 1997, but they were ultimately reunited with the release of gcc 2.95.
xhtml was once meant to be a radical xml-based successor to html by the original creators of html. it got even more radical in xhtml 2, which never really went anywhere because it was incompatible with existing web content, unlike earlier versions which could at least be written in an awkward html polyglot that kinda worked in internet explorer 6. the more descriptivist side of w3c, which were primarily the browser vendors, broke off to continue working on the old html, and three things happened:
solaris (2.)7 runs incredibly slowly on borealis, and even if we double its memory to 128 MiB on loan from our other sparcstation 5, things aren’t much better. when the machine was announced, sun was still on solaris 2.4, and solaris 2.5 was released soon after, so solaris 7 probably only had a chance at running well on the higher-end sparcstations 10 and 20.
our other sparcstation 5 has a faster cpu, so why don’t we swap in the nice 2 GB hard drive and install solaris 2.5.1 there?

i burned two copies of the install cd, and both of them threw a wide variety of read errors that ultimately led to boot failure. i told @ariashark about this, and it suggested i try the other machine. the sharks being wise as ever, the installer booted without any problems, so i figured the drive was faulty.
while swapping the cd drives, i noticed that one of them was mounted with wedges of paper instead of the proper rollers. two of the three wedges appear to come from branded stationery for the defence science & technology organisation, which is like the australian military’s research sidekick.

hopefully we can give australis a better life!


it’s been like three years, of the <3 years of cohost’s existence

the uk goverment is launching a campaign about how successful our tech industry is
it's called, i shit you not: "the unicorn kingdom"


you're sitting in the middle of a beautiful forest. birds are chirping, but it's still quieter than you remembered outside could be, living in a city as you have most of your life, and when the sun goes down, you'll remember what stars look like. you relax, sighing more softly than you need to, then silence envelops you once again. in your left ear, you hear an internet explorer navigation click
my favorite part about this bit is that if you're under 30 you almost certainly won't get the actual cosmic horror of it
okay here's the explanation
Back in 1998, even though modern, stable web browsers didn't exist and the term webapp did not exist (or referred to serverside stuff mostly written in ASP) the concept of the Awful WebView App was already in full swing. the distinctions vs now were
but the other thing is that they all used Internet Explorer's COM embed object, because chromium hadn't been invented yet. And the thing about IE is that every single time you clicked a link or otherwise navigated to a different page, it played an utterly unnecessary clik noise. we all hated it, and app devs who used this technique never turned the sound off, because - even more so than now - the fact that an app was Just A Webpage was a 100% guarantee that the developers were bottom dollar incompetents making software under duress for a company that felt nothing but malice for its users (Symantec, Mcafee)
so you'd invariably end up with some miserable piece of sludge running on your machine that you couldn't get rid of, or couldn't even identify since it was some hidden process installed by a driver, and for God knows what reason, they would occasionally decide to reload the hidden web view. and you'd just hear
clik
and wonder how the fuck a browser could be open, or what on earth it had just done
PS: you have to understand that at the time, even for those of us who had always on internet, it was really not normal or at all comfortable to think about your computer doing stuff that you hadn't explicitly asked it to do. I just thought you should have that context. It wasn't always like this.
but only when you’re using an actual browser, not like electron apps or w/e
“And thus is the case of the structured bathroom experience — it has ripped society apart at the seams, confusing and confounding young humans and complicating their lives to the point of ridiculousness.”
When researching Phoenix Hyperspace for my highly upsetting post on the subject, it was hard to avoid news articles proclaiming that it had been sold off by Phoenix (when they gave up wholesale on their idea of making anything other than BIOSes) and bought up by HP. However, that's where the trail ended; attempts to find out what, if anything, HP had done with it proved fruitless. That is, until two days ago.
When researching an only tangentially related subject (the Dell Latitude Z600, which runs a completely different instant-on linux) I stumbled across a mention of HP QuickWeb, described as another fast-booting Linux distro. Digging into this, I uncovered quite a shocking amount of information I had managed to miss before, on account of there being no standardized terminology for any of this stuff.
The discovery process on all of this happened so quickly that I don't really want to drag it out the way I did in the previous post. Once I knew the terminology, it took me maybe six hours to make it from beginning to end. The journey is less important than the destination in this leg of the story, so let me just summarize much of it, broken up into Important Data Nodes:
HP did in fact buy Hyperspace in late 2009 - but they didn't do anything with it right away.
Prior to the acquisition, they already had an instant-on Linux - one based on Splashtop, under the name QuickWeb.
It's amazing that I missed this, because they sold it across their whole range for several years. Netbooks (Mini 210), consumer machines (Envy 13/14), business (Probook 4730s, 4530s, 4430s), executive (Elitebook 8540w, 8440p) - and these are just some examples. There were many more. I was able to walk into RePC the day after I learned about this and walk out with two machines that support it, that's how common it was.
Laptops with QuickWeb support have a little button with a globe icon that boots QuickWeb instead of your normal OS. Note that not all HPs with globe buttons can do it; on some, that button just opens a web browser within Windows. There is no way to tell which is which. For instance, the Elitebook 8460 and 8470 look exactly identical, but only the former supports QuickWeb.
A couple years after the acquisition (AFAICT) HP finally decided to do something with Hyperspace: They quietly replaced the existing QuickWeb with one based on Hyperspace, with no fanfare or announcement of any kind. I can find no information linking the two - the only way I was able to prove this was by downloading two revisions of QuickWeb, extracting them, and finding strings for Splashtop in one and Hyperspace in the other.
As with the other Hyperspace (and Splashtop) implementations I showed in the previous post, the actual OS is completly uninteresting. In fact, it doesn't even have the unholy host filesystem access feature, or the office suite, or the ability to save files at all. It's simply a web browser, Skype, an email client, and some news and stonks widgets.
Additionally, HP did not base their implementation on Hyperspace Hybrid or Dual. It's the very basic version: a fast-boot Linux that dual-boots with Windows.
It is not, however, a conventional MBR-type dual-boot setup, nor is it using Phoenix's wacky hidden BEER partition table nonsense. Instead, the OS is simply stored as files on a FAT32 partition called HP_TOOLS; it's not even hidden, the user can see it in Windows.
Since this era of HP laptop had early UEFI, and UEFI can read FAT32, they used custom firmware code to just look for a partition with that specific name, then it finds "HP_TOOLS\QuickWeb\QuickWeb.efi" and boot it. EFI is a big step in making the PC more boring (good meaning)
Okay, let's have some pictures.

This is the "globe" button. As noted, it doesn't mean a machine definitely has QuickWeb.

This is Quickweb - specifically, a version I haven't yet been able to locate. This is from an old blog post. It's obviously Splashtop-based, since it's clearly branded in the screenshot, but it seems to be much closer to the original offering, with a widget based "desktop" and a number of bundled apps including Skype, chat, email, music and a photo viewer. I found a couple other screenshots that make it clear that the latter two apps are still the terrible Adobe Flash crap that they were selling in 2009.
I have seen references in HPs docs to QuickWeb version numbers, but no clear rubric. I suspect that this version is "QuickWeb 1," the next one is "QuickWeb 2", and the Hyperspace version is "QuickWeb 3."

The above is what I suspect was "QuickWeb 2." It says version 1, but who knows whose numbering scheme that is. It's still Splashtop-based, but HP has removed the branding. I was able to install it on a machine (EliteBook 8440p,) but it seems to have absolutely no features other than a web browser - this is the sole UI. It appears to be a huge downgrade, reason unknown.

This is the Hyperspace version, which I think is "QuickWeb 3." Functionally, it's a middle ground; it has Skype and email, plus these widgets (which, again, still work; I connected to wifi and both the CNN and BBC headline widgets populated.) Otherwise, it is still very barebones, not much better than "QuickWeb 1" from the looks of things.
As noted, there is nothing worth discussing about the OSes themselves. It's mostly just fascinating that Hyperspace continued to have a life at all, and kind of a disappointment that HP's vision of its future didn't include any of its advanced implementations, and in fact didn't even include the office suite or anything that made it more interesting than Splashtop.
Anyway, let's get into the new shit.
While investigating QuickWeb, I began finding mentions of something called QuickLook. At first, it wasn't clear if this was two names for the same thing, but it became apparent that QuickLook was a distinct product, because I learned that certain models (e.g. EliteBook 8440p) had another separate button for launching it.
Let me reiterate: Certain HP laptops have three power buttons that launch different OSes. That slaps all on it's own.
But what is Quicklook?

It's not an "OS." It's a program. Literally - it turns out to be "HP_TOOLS\QuickLook\QuickLook.efi", a standalone EFI application. Normally you only see those in the form of OS bootloaders, BIOS config utilities, or maybe a very limited motherboard/laptop vendor recovery or firmware flashing tool. But EFI apps are just binaries, and EFI is a limited "OS" that provides a set of libraries, so you can conceivably write many complex programs to run inside of it.
HP decided to write Outlook.

")
QuickLook is an email and calendar app that you can launch directly instead of booting a normal OS. I need to stress that, as far as I can tell, this is not Linux, this is not DOS, this is not anything. This is a bespoke standalone program, written in C (there are .c files mentioned all throughout the .EFI, which is just a Windows-format .EXE with a different name.) It leverages EFI's basic mouse/keyboard/graphics APIs, like "Absolute Pointer Protocol" and "Graphics Output Protocol."
To reiterate, because I need to know you understand: HP wrote an email/calendar client completely from scratch that runs inside your system's BIOS.

When you press the QuickLook button (the left blue icon above; the right is QuickWeb), the machine powers on, POSTs, and then hard code in the EFI firmware checks for an attached hard drive with a partition called HP_TOOLS, then boots straight into Quicklook\QuickLook.EFI, and then that is what is running on your machine. Not Windows, not Linux. Your PC is natively running QuickLook.
So, how does it handle networking, SMTP/IMAP, and all the complexities of Outlook, without actually being Outlook? How does it read and write to your .OST database on your main NTFS partition without risking corruption? Well, naturally, it doesn't. This is another filthy hack.
When you install QuickLook, it installs a plugin for Outlook (only supported on 2003 and 2007) which periodically, at a configurable interval, copies the entire contents of your inbox and calendar to an XML file in HP_TOOLS. If you send an email or edit a calendar event from QuickLook, it just writes it to an XML file, and when you boot into Windows again, the Outlook plugin reads it and replicates those actions within the real user DB.
What I said was a lie: HP didn't reimplement Outlook at all. They wrote a generic email and calendar app, then wrote an Outlook connector for it.
This has implications.
When I first started Quicklook, it complained that there was no user data, and I had to install the Outlook plugin to fix that. But at this point, you may be wondering: if it's not actually touching the Outlook data file, then why do we even need Outlook, or Windows at all? The answer, as far as I know, is that you don't - and HP doesn't even claim that you do.
HP provides a document explaining how QuickLook works, which includes instructions on how to build the HP_TOOLS partition manually and populate it with the needed files. There is no claim that you must set this up using their official installer.
I haven't tried yet, but I can't think of a reason you couldn't do this from Linux, by simply making the partition and copying the files over. They aren't "blessed." There are no secret MBR entries. EFI is modern software, not a taped together pile of shit based on code from 1983 that only barely understands x64 and thinks it's booting from a floppy drive or a cassette port. It knows what AHCI is! It can just read the fucking filesystem! It doesn't need a hand up from some absurd preboot bodgery. This whole thing is just a bunch of files.
In addition, the data files are not complex:

There is nothing stopping you from writing your own script that reads a mail file from anything else - Thunderbird, or pine - and produces these files. QuickLook shouldn't care.
Not, of course, that you'd WANT to use QuickLook. It doesn't boot that much faster than a modern OS on an SSD. Nowadays, it's utterly pointless, and additionally, it runs like shit.
While UEFI is "an operating system" for many intents and purposes... it's not a very good one. Its APIs are very limited and unoptimized, and that's probably why the UI updates at maybe 10fps. The mouse cursor doesn't even move smoothly. It really looks and feels like crap, and that's most likely because HP's devs had to write their own widget set, there's no 2D graphics acceleration, no multithreading, and the API may not even allow access to the framebuffer except through extremely crude, unoptimized full-screen updates.
Think of how the BIOS config on your motherboard from 2012 performed, then imagine trying to use that as an operating system. Oof. So just like Splashtop and Hyperspace, it's pointless, but it is neat - though sadly not as neat as the absurd ACPI horseshit from the last post.
However, I had not yet reached the end of my discoveries.
I was able to install QuickLook and QuickWeb on the machines I bought by simply downloading them from HP's driver site. Bless them, sort of. But while trying to find a specific version for a particular machine, I saw a link to a download for something called "HP DayStarter." The description was... concerning.
The HP DayStarter displays Microsoft Outlook calendar information and custom messages while Windows loads on supported notebook models with supported operating systems.
My reaction was "I'm sorry. What," and it kinda still is.
I found this screenshot:

Daystarter purports to show you your calendar while Windows is booting. And, okay, so what - they're just replacing the bootsplash image, like we all did on Windows 98 and XP when we were 13.
No. It steps through your week as it boots. And you can hit keyboard shortcuts to pause or clear it. This is a program that runs while Windows boots.
I don't... really... need to explain that this isn't possible. As-written: no, this isn't a thing, this can't be done, and I don't just mean "it's hard and messy," I mean this should not be possible.
I am no systems programmer (nor have I passed the bar) but I know a little bit. The moment any Windows based on NT begins booting, the system is in protected mode. As the name suggests, this is a security feature, to prevent programs from doing things that endanger the reliability of the system.
As soon as the Windows kernel begins executing, it has total dominion over the PC. Nothing else is allowed to run - nothing else can run. The CPU is executing only the Windows kernel code. If anything else attempts to write to system memory - such as the VGA framebuffer - without the kernel's permission, it would result in a hardware-level exception, which the kernel would trap and discard.
I'm overstating the point however. It doesn't matter that something else couldn't touch system memory, because there's just simply no way to execute other code. At this point in the boot process, your computer is like a MOS 6502 from 1979. It's a Turing machine. Each byte of machine code from the Windows kernel is executed in order, it does exactly what Microsoft coded it to do, and then the instruction pointer either advances or jumps to another location that the Windows kernel chooses.
There are no cracks into which to get your fingers. It's like asking "what if my hand passed through this brick wall, how would we handle that scenario?" It's not going to happen because it's logically impossible.
So I installed QuickLook and rebooted the laptop.

Holy fucking hell. They really did it, the madmen. But how. Fucking how did they do this, when it should be physically impossible?
The first answer that comes to mind is "they hacked the OS", but A) it would instantly get reverted by Microsoft SFC, B) it would instantly break as soon as you installed any OS patches, and C) nah. Just nah. HP did not write a program that binary-patches NTOSKRNL.COM. That isn't even on the table.
But... what else is left? What could they possibly have done to accomplish this?
If you can believe this: It's worse than Hyperspace Dual.

We don't have full documentation on how this works, but we have enough to assemble a working theory.
What we do know is that the Quicklook plugin for outlook creates a DayStarter folder on HP_TOOLS, and whenever a sync occurs, it reads your calendar and spits out 7 JPEG files. For instance:
 of a Daystarter splash-screen calendar showing the Steven Jobs meeting")
This is one of the files it generated. These, again, are simply files in the FAT32 filesystem.
When you enable HP Daystarter (it's a setting in the BIOS setup), I believe that there is a piece of hard code in the firmware that activates. In other words, this is not an EFI application being loaded off the HDD like QuickWeb and QuickLook. There's no "Daystarter.efi", and that makes sense - if you booted into that, you wouldn't be booting Windows.
Maybe it's chainloading into Windows? Well, this machine shipped with Windows 7, which didn't even get UEFI support until very late in its lifespan. It was almost certainly shipped in UEFI-CSM mode (aka BIOS mode,) and that's how it's working on my specimen. So they wouldn't be able to launch an EFI app, then chainload into a BIOS app - at least, all the universal bootloaders I've tried claim that this is impossible, and I'm sure if that wasn't the case they would be willing to do it.
The theory partly suggested by mxshift (who isn't on here, but we chat on discord and they do x86 firmware programming) is that Daystarter gets loaded by HP's EFI (i assume before it goes to CSM mode) and traps a certain interrupt or IO access. As Windows is starting, it keeps updating the VGA framebuffer to move the progress bar. Daystarter traps that event, throws it away, and instead writes its own content to the framebuffer. It also uses this opportunity to check the keyboard buffer for an F4 or F3, so it can take user input.
But wait - how is that code running? Windows is in protected mode at this point, what would be allowed to supersede it?
Per the slide reproduced above: Daystarter runs from goddamn System Management Mode.
I had never heard of SMM before today. Apparently this was introduced on the 386SL CPU (supposedly, to implement software-based thermal management features) and operates with a privilege level even higher than ring 0 (where the Windows kernel lives) with access to do virtually anything. It's a well-guarded feature, apparently, but hey - HP writes their own firmware. They can do whatever the hell they want.
So Daystarter is - naturally! - a horrifying abuse of a hardware feature not intended for this at all. I'm told SMM has been leveraged before for many things it wasn't intended for, such as the implementation of USB legacy keyboard support, but this feels like it's just not justified.
Because, let's be real here: This is absurd! This is all so fucking absurd!
I have this long running theory about computer hardware manufacturers: They're miserable, and terrified.
I have written many times, from different angles, about what I think capitalism sees in Technology as a whole. The basic loop has been the same for over a century:
Invent a thing
Convince a group of people (hopefully "everyone") that it will make them happier
Make lots of profit by selling people your vacuum cleaner
MARKET SATURATION! Everyone has a vacuum and nobody needs a new one.
Invent a new vacuum with a stronger motor OR a quieter motor OR a longer hose OR a better beater OR lighter weight
Make lots of profit by selling people your new vacuum; they throw out their old one.
Now look at PCs, from the perspective of a vendor like HP or Dell:
Assemble a thing out of parts you had nothing to do with: an Intel CPU and chipset, Realtek audio, nVidia GPU, and so on
Convince a group of people that yours is the cheapest or most reliable
Make lots of profit by selling people the exact same thing your competition has
This is a much tougher row to hoe. The whole latter part of the loop is missing. How does Dell convince you that their machine has a new greeble, a new button, a new lever? They can't. It's impossible for them to add one, the PC doesn't work that way. The basic motherboard has to be wired up exactly the same way in every single machine in the world; all functions beyond basic CPU, memory and boot have to be provided by standardized components - USB, PCIe, or m.2. They have to work the same as all others of their type.
This means that Dell can't sell you a machine with a feature that isn't just a PCIe card or a USB device. Sure, maybe they could invent a device that uses those interfaces and refuse to sell it through any other channels except with their PCs - but I challenge you to come up with such a device that A) would be so compelling that it would make someone buy a Dell just to have it, and B) wouldn't be cloned as a generic product a week later. It's impossible.
It's even worse for motherboard vendors. All these companies are is turnkeys. They take the Intel socket of the month, Intel chipset of the month, and whichever other jellybean parts are current and glue them together. Is it easy? Probably not, but nobody cares.
Yeah, people have always had opinions. They'd say "all Gigabyte boards are trash" - it's patent nonsense, and we all know it. People used Gigabyte or Abit or ECS boards for years with no real trouble. Sometimes a bad chipset came out, like the nForce, but that wasn't the board mfgr's fault. The only thing they ever really fucked up was the capacitor situation, and you better BELIEVE the vendors all rode THAT shit when it was finally acknowledged as a real problem. There were (and I think still are) motherboard boxes with MASSIVE wordart text proclaiming JAPANESE POLYMER CAPS as the highest-billed feature.
Because, yeah - what the hell else can a motherboard vendor offer? They aren't allowed to do anything! Their board HAS to work exactly the same as all others or it's useless trash. And how could they add any functionality anyway? They're essentially selling you the middle of a machine. All the parts you bolt on see it as a black box that's supposed to work a very specific way. It's logically impossible for anything the motherboard does to affect how the computer works; it's simply a junction box.
In the mid 2000s, Abit and ASUS and MSI were going batshit. They couldn't figure out what to do - the market for DIY PCs was huge, probably even moreso than now, but the only levers they had access to pull were thermal management and overclocking - so you better believe they rode it as hard as they can. That's when we started getting these grotesque, screen-filling overclocking apps with gallons of Graphic Design dumped on them; huge virtual gauges trying to turn "adjusting a voltage rail by .01V" into Some Matrix Shit.
It's also when Asus sold at least one board with a complete 5.25" front drive bay panel dedicated to resetting your CMOS settings.
Yeah, I know, I know. Overclockers did need to do that a lot. But that's not why ASUS made such a big deal out of it. It was this great big army-green panel with caution stripes and a molly cover over the switch. Asus was so fucking pumped that they finally got to expose the one actual function their board had. Motherboards can't have buttons! This was the only one that could ever exist, and for 15 years it only got pressed once every five years. Asus were beside themselves that they finally got to have a feature.
I saw CMOS reset switches dressed up in so many ways, because that's all they had. And when EFI came along and gave motherboard vendors something, anything at all to customize, they ate it up. Every single motherboard has a completely different (and uniquely unnavigable) CMOS setup because, again, this is the only lever they can pull.
So, comparing to the situation in question:
Imagine being a product designer at HP, in the very weird year of 2010, and having some fucking VP storm in and go "We have to deliver Features for Executives. We're selling $1500 notebooks to them, but Dell has exactly the same set of ins and outs as us. We need Features."
You just stare at the guy, and slowly go, "We're... a motherboard. That's all we are, Bob. We can't have features. Everything that happens once the computer is on is inside Windows, and we aren't allowed to touch it."
And Bob tells you you're fucking fired, and turns to the next person and says the same thing. He repeats this until someone blurts out the dumbest idea anyone's ever had, and Bob goes "That's it, make that."
What do executives do on their computers? Outlook. It's the only program they run. It's why you can't sell them anything - what, more RAM? Outlook runs fine in two gigs, even now, especially then. More CPU power? Same answer. A GPU? To do what? And that's all a computer manufacturer can do - stick in more jellybean parts that someone else made.
How do you make a computer somehow better at Outlook? The answer is that you can't, it's impossible. Windows controls the whole machine and Microsoft controls Outlook, HP can't stick their fingers in and somehow enhance the Outlook experience. So, they touched the only thing that Microsoft didn't control: The pre-boot experience.
Does it make sense to write a whole separate OS, just so an executive doesn't have to wait an extra 30 seconds to see their email? Of course not. This was also 2011, and SSDs existed. It would have cost less to just bundle an SSD, and would have worked better. Sleep and hibernate were also pretty functional by then. It would have been, and almost certainly was, faster to just put your machine to sleep and wake it up normally. But no, we need a feature. So HP wrote one of the only standalone EFI applications in existence.
And then they were out of ideas. Quasi-Outlook can now load in 15 seconds! Uh. Now what? What's left to attack?
Well... what if they are intending to get into Windows? We can't speed that up (on a 5400rpm spinning disk that our absolutely oblivious cost-reduction specialists forced us to include) - so what if we were able to at least display their calendar 15 seconds sooner?
Was this worth it? Worth inventing completely new forms of software, worth injecting code into the fucking thermal management layer that overrides parts of the Windows boot sequence and risks corrupting main RAM and rendering the machine unusable, all for a fucking 15 second speedup? Of course not. But it's the only lever they could pull, and it's better than getting fired because your position, and your business, and the company you work for, have been redundant for a decade.

march 28, 2023
trying to get back into this. still no desktop PC back yet, still in limbo, as all of my life seemingly perpetually is. need to start selling prints, so I can buy some things I need for a new workstation, but I left my printer in Seattle. it has been a long, cold, dark winter. I am very tired. I hope the sun breaks through soon

20 december 2017

14 may 2022
march 28, 2023
trying to get back into this. still no desktop PC back yet, still in limbo, as all of my life seemingly perpetually is. need to start selling prints, so I can buy some things I need for a new workstation, but I left my printer in Seattle. it has been a long, cold, dark winter. I am very tired. I hope the sun breaks through soon
20 december 2017
NAME
mdadmdma - manage MDMA devices aka midomafetamine
SYNOPSIS
mdadmdma [

its always the auto users who cry the loudest about a good negev play :^)
they call you subhuman and you just reply “but i have double your kills?”
and now i bark like pochita
https://codepen.io/plfstr/full/zYqQeRw
i am fucking CRACKED at this. i got 76
i knew half of those because i a) use a lot of markdown and b) dug around in the HTML tag list a lot for web security stuff lol
oops i totally forgot about frames and legacy text styling (font, big, small, center), but it looks like the quiz only has <iframe> and none of the latter anyway. i was also sad to see that it excludes <plaintext>, which literally has a dedicated tokeniser state.
my best guess is that the quiz excludes everything under § 16.2 Non-conforming features, which i think is prescriptivist bullshit >:(
a, b, i, q, s, em, strong, p, h1, h2, h3, h4, h5, h6, header, nav, section, main, footer, aside, html, head, body, script, style, meta, link, base, abbr, samp, var, u, rt, ruby, table, colgroup, col, thead, tbody, tfoot, tr, td, th, dl, dt, dd, ol, ul, li, summary, details, article, form, input, textarea, select, option, optgroup, map, area, img, picture, source, video, audio, object, embed, br, svg, math, kbd, pre, code, blockquote, address, time, hgroup, button, label, template, slot, div, span, hr, canvas, dialog, title, figure, figcaption, mark, menu, rp, wbr
(bold for things i feel smug about knowing, italic for “non-conforming”)
if you ignore the linear mode, they're better characterised as current-controlled diodes, because if they're off there's a leakage current and if they're on there's a forward-biased diode
a FET is more like a switch in that it Has Resistance if its on and has Open Loop Resistance if its off (and the energy you use to operate it is on the order of nanojoules, but thats beside the point i guess)

i wonder how many people have realized that the hex numbers in my bio are the unicode codepoints for &ΘΔ lol
i wonder how many people have realised that the 🏳️‍⚧️ in my bio is a mojibake trans flag
like swap eyeballs every night” — 🪐

i’ve been reading the excellent Web Browser Engineering and following along in rust. you can too! the whole book is free online!
so far i’ve done a rudimentary html parser, dom tree, layout tree, and paint, with only ~2000 lines of code. now i’m working on a toy css engine.
no ‘float’ or ‘height’ or ‘font’ shorthand yet, but i rewrote the layout code so it actually somewhat makes sense now. styles are still applied in file order without any cascade, but thankfully acid1 doesn’t rely on that.
i also added anonymous boxes, ‘display’, ‘font-size’, ‘font-weight’, ‘font-style’, ‘margin’, ‘padding’, ‘border’, and matching compound and complex selectors.
https://github.com/delan/wbe.rs/commit/3c0a3dd6c4a5fc4213347d730efeacd7538acd19
the css1 spec is tiny by today’s standards, by the way. you can read the whole thing in a couple of hours, and two thirds of it is the property definitions, of which there are only 52, or only 21 if you don’t count longhands. fun facts about css1:
but most of the fundamental decisions that make css so wonderful were already there:


* not quite the shittest, i mean have you seen pre-2006 browsers doing acid2?
i’ve been reading the excellent Web Browser Engineering and following along in rust. you can too! the whole book is free online!
so far i’ve done a rudimentary html parser, dom tree, layout tree, and paint, with only ~2000 lines of code. now i’m working on a toy css engine.
no ‘float’ or ‘height’ or ‘font’ shorthand yet, but i rewrote the layout code so it actually somewhat makes sense now. styles are still applied in file order without any cascade, but thankfully acid1 doesn’t rely on that.
i also added anonymous boxes, ‘display’, ‘font-size’, ‘font-weight’, ‘font-style’, ‘margin’, ‘padding’, ‘border’, and matching compound and complex selectors.
https://github.com/delan/wbe.rs/commit/3c0a3dd6c4a5fc4213347d730efeacd7538acd19
the css1 spec is tiny by today’s standards, by the way. you can read the whole thing in a couple of hours, and two thirds of it is the property definitions, of which there are only 52, or only 21 if you don’t count longhands. fun facts about css1:
but most of the fundamental decisions that make css so wonderful were already there:
i’ve been reading the excellent Web Browser Engineering and following along in rust. you can too! the whole book is free online!
so far i’ve done a rudimentary html parser, dom tree, layout tree, and paint, with only ~2000 lines of code. now i’m working on a toy css engine.
no ‘float’ or ‘height’ or ‘font’ shorthand yet, but i rewrote the layout code so it actually somewhat makes sense now. styles are still applied in file order without any cascade, but thankfully acid1 doesn’t rely on that.
i also added anonymous boxes, ‘display’, ‘font-size’, ‘font-weight’, ‘font-style’, ‘margin’, ‘padding’, ‘border’, and matching compound and complex selectors.
https://github.com/delan/wbe.rs/commit/3c0a3dd6c4a5fc4213347d730efeacd7538acd19
the css1 spec is tiny by today’s standards, by the way. you can read the whole thing in a couple of hours, and two thirds of it is the property definitions, of which there are only 52, or only 21 if you don’t count longhands. fun facts about css1:
but most of the fundamental decisions that make css so wonderful were already there:
i’ve been reading the excellent Web Browser Engineering and following along in rust. you can too! the whole book is free online!
so far i’ve done a rudimentary html parser, dom tree, layout tree, and paint, with only ~2000 lines of code. now i’m working on a toy css engine.
i’ve been reading the excellent Web Browser Engineering and following along in rust. you can too! the whole book is free online!
so far i’ve done a rudimentary html parser, dom tree, layout tree, and paint, with only ~2000 lines of code. now i’m working on a toy css engine.

and a whole can of wet food heavier
RSD is sooooooooo annoying. I experience the emotional equivalent of a ticketed misdemeanor and my brain/body lose their shit like it was a federal felony. The most annoying part is my consciousness is not asked for its opinion– I am fully aware this is a wildly disproportionate reaction, and I'm just as incredulous as anyone about it! But knowing this is ridiculous doesn't do anything to prevent 4-48 hours of feeling Aggressively Awful.
At least I didn't luck into the "feels like I'm being physically stabbed" full-impairment version this time. 😒 I would like to thank modern pharmaceuticals for fixing me up to the point where I merely feel Bad™ but can more or less go about my day.
that might give the chrome profiler and chrome://tracing a run for their money! how long has this been a thing?!
https://github.com/NsCDE/NsCDE
I'm not sure I understand the elements of social realism the developer perceives in the CDE aesthetic, but I do appreciate that someone is dusting off late-'90s workstation look & feel and applying it to a modern window manager, because now I can make a computer look The Way A Computer Is Supposed To Look, without having to suffer through quite so many bad habits of software of the late '90s
"join our discord" is the new "pinterest result on google." anti-information. your pursuit ends here. facts will not be found today. it's like if you asked someone on the street what time it was and they said "come into my church and take communion and I'll tell you"
discord is an organized, focused, hell-bent project to ensure that no! information ever! gets accidentally preserved. the purpose of a system is what it does, so discord's purpose is to lose things. "everything anyone has ever said on a topic" is the goal but they take what they can get
it used to be terrifying when the support / faq / help link on a website went to a forum. then they started going to wikis, and we all turned around and screamed at springy the spring sprite to take it back, we didn't mean it. we love zinc.
then they turned into discord links, and when we looked back at springy, we saw only satan
it's just an incredible one-two-three punch of "did you just tell me to go fuck myself?"
because you get part A: "almost everything we've ever said about our software project is in, basically, a 10 gigabyte text file spanning 8 years of conversations, many off-topic. here's a fulltext search. it replaces near-homonyms, so your search for the exact keyword 'CLOUT' will be silently altered to 'CLOUD'."
and part B: "you can't even look at it without loading it up in a separate program, possibly getting punted into a Welcome To Our Server process, having everyone on the server see your name (hope you weren't investigating something made by people who hate you!) and then having four people @ you the millisecond you join with generic welcomes (hope you don't have social anxiety!)"
and then part C: "if you gather up the courage to actually ask us for help after the fulltext search fails, we will insult you until you cry, even if you don't have social anxiety."
the best advice i can possibly give anyone is "every time one person joins your discord, one thousand people decide your project is off-limits to them and leave the page, never to return."
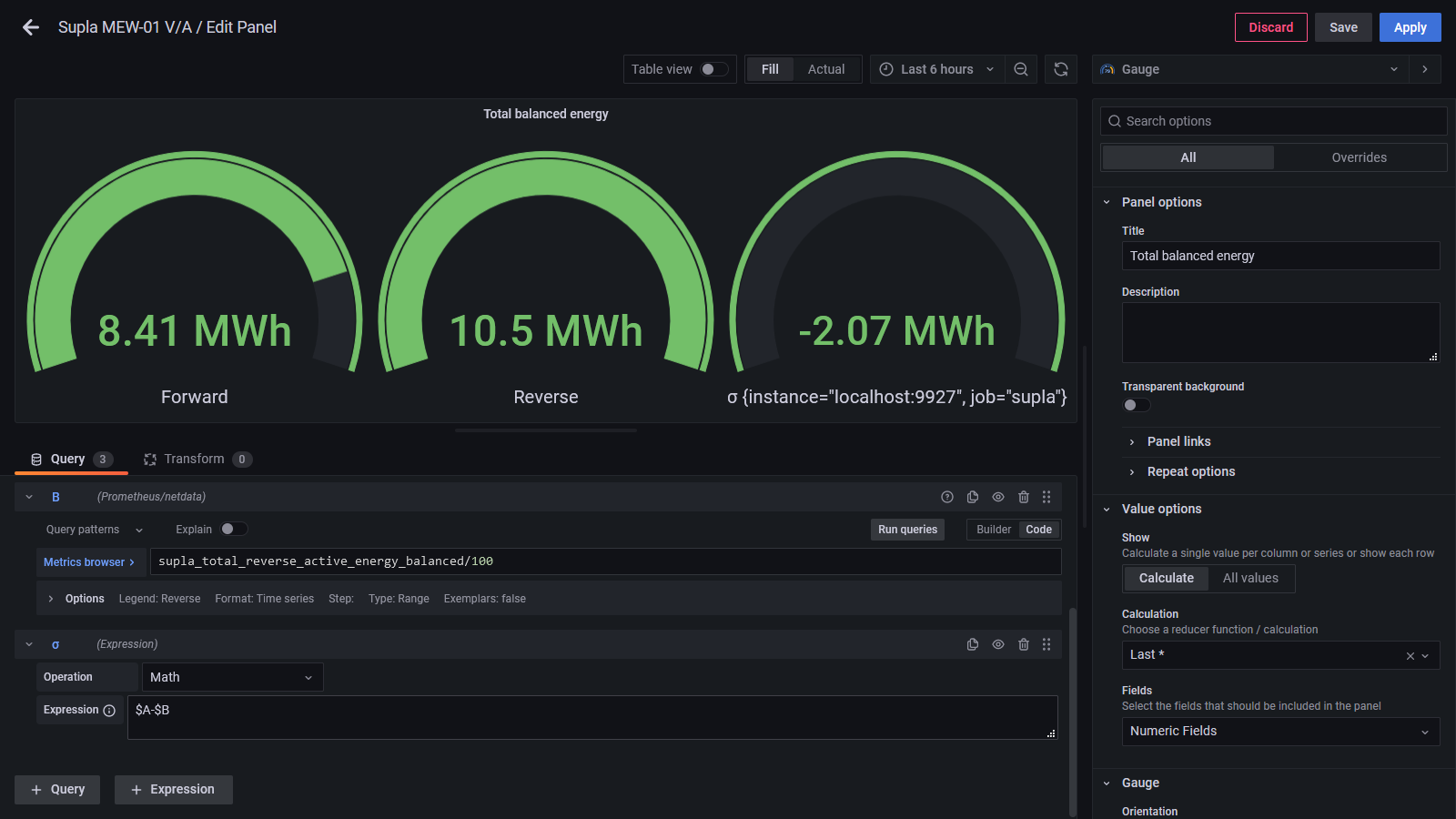
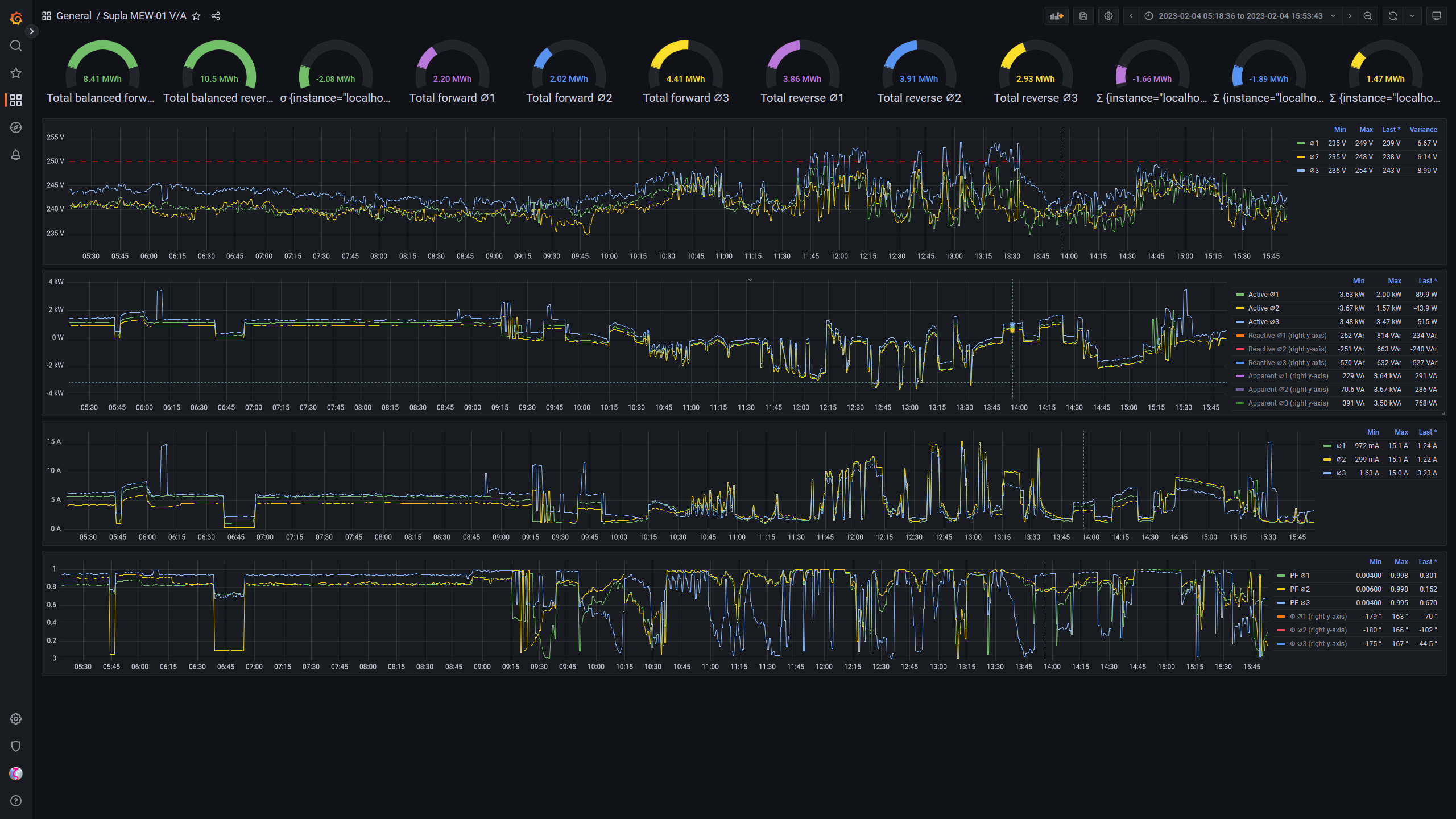
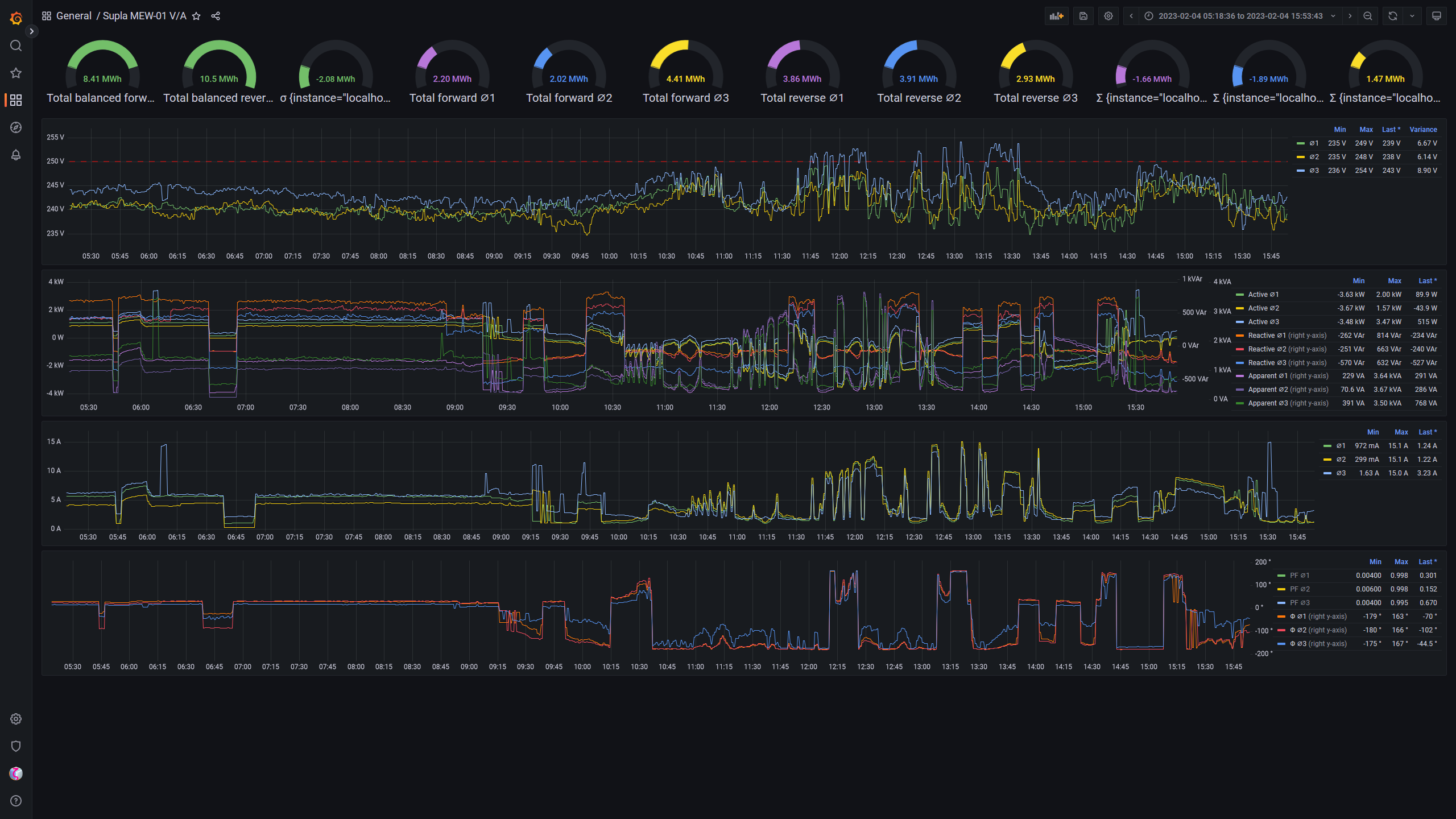
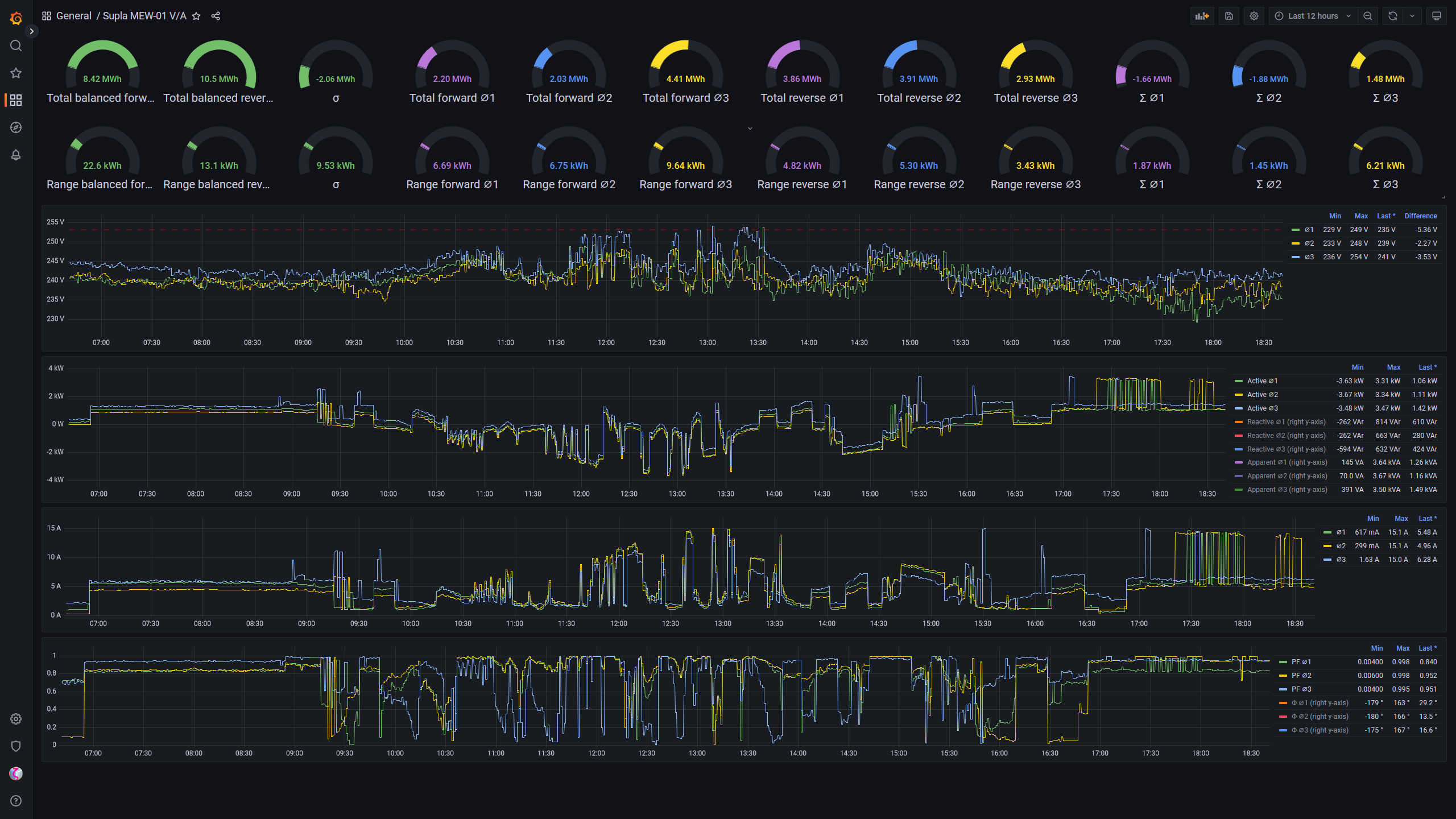
so overall – while this meter was installed – we've eaten 8.42MWh and generated 10.5MWh
so we've generated 2.06MWh net
but we can also see why we got a leccy bill
on phases 1 and 2 we generated 1.66 and 1.88 MWh net, but on phase 3 we sucked off 1.48MWh
(because each phase is billed separately)
load imbalance 😔
Firstly, succumb to the knowledge that SVG files can have javascript embedded in them. Here is an example of some SVG art I made with a color-picker built into it.
Secondly, a fun fact: In SVG, a block of javascript code can live inside a tag alongside vector graphics. This means if you copy that group to another SVG document (e.g. in inkscape) the script will come along too.
So consider: an alternate history where SVG won over HTML. One where someone wrote some javascript that dynamically resizes the SVG viewbox depending on display resolution, and implements a grid-based layout system. I'm 50% sure this is possible, someone would just have to implement it.
So given paragraph 1, 2, and 3 together: I'm imagining that you could distribute scripts for SVG web pages as fancy vector graphics with the javascript inside its group tag. So if you were to load one of these alternate universe web pages into a graphics editor, you'd be able to see all the libraries it uses arranged in a neat row just outside the canvas extents.
 Anyway, I just think that would be neat
Anyway, I just think that would be neat
@blackle’s post reminds me of an old project. i made a mini metro map for perth, australia, but the source code is actually an svg drawing that uses an embedded script to generate the map in the format the game expects: https://bucket.daz.cat/mmm/per/drawing.svg
maps for this minimalist rail transit strategy game are in a json-based format, and include the visible geometry of land masses and water bodies, plus invisible geometry for things like the regions that stations can spawn in. there’s no level editor available to the public though, so the official guide suggests the following workflow:
that first step is ok, but the rest are
what if we could use coding and algorithms to solve these problems without doing a bunch of tedious and error-prone conversions by hand?
let’s add a script and textarea field to the end of the svg element. the textarea element is from html, so we need to wrap it in a foreignObject.
<svg ...>
...
<foreignObject width="74vw" height="60vh" x="13vw" y="13vh">
<xhtml:textarea id="out" style="width:100%;height:100%" />
</foreignObject>
<script href="drawing.js" />
</svg>we can make a variable containing most of our city.json, with holes where all of the geometry needs to go. these holes grab the relevant paths by id, and pass them to our convert function for conversion to absolute points.
const result = {
"customName": "Perth",
"customCountryName": "Australia",
"customLocalName": "Boorloo",
"customLocalNameLocale": "nys",
"obstacles": [
{
"points": convert("#back"),
"note": "back",
"visual": true,
"inverted": true
},
{
"points": convert("#swan"),
"note": "swan",
"visual": true,
"inverted": false
},
{
"points": convert("#lakejoondalup"),
"note": "Lake Joondalup",
"visual": true,
"inverted": false
}
],
"cityAreas": [
{
"label": "Vincent",
"density": 1.25,
"paths": [ { "points": convert("#vincent") } ]
},
{
"label": "Maylands",
"density": 1.21875,
"paths": [ { "points": convert("#maylands") } ]
},
{
"label": "Subiaco",
"density": 1.1875,
"paths": [ { "points": convert("#subiaco") } ]
}
]
};the convert function walks through the pathSegList of the given path, adding or replacing coordinates as needed to make them absolute, then negating y for the result.
function convert(path) {
const result = [];
let prev = null;
path = document.querySelector(path);
for (const seg of [...path.pathSegList]) {
const type = seg.pathSegTypeAsLetter;
let next = type >= "a" ? [...prev] : [0, 0];
switch (type) {
case "Z": case "z":
break;
case "M": case "m":
case "L": case "l":
next[0] += seg.x;
next[1] += seg.y;
break;
case "H": case "h":
next[0] += seg.x;
next[1] = prev[1];
break;
case "V": case "v":
next[0] = prev[0];
next[1] += seg.y;
break;
default:
throw new Error(`unexpected path command type ${type}`);
}
if (prev == null || next[0] != prev[0] || next[1] != prev[1])
result.push([next[0], -next[1]]);
prev = next;
}
return result;
}now we can serialise the object into a complete mini metro map. we can later edit the geometry if needed, and inkscape will ignore (but keep) the foreignObject and the script, so any changes we make will be reflected in the output! yay!
document.querySelector("#out").value =
JSON.stringify(result, null, 4);it makes sense that there’s no dedicated level editor in the traditional sense. the devs have better things to do than reimplementing half of inkscape, which already does a good job of tracing geometry from maps.
but maybe the devs could make a “mini-metro-sdk.js” that you could plug into any drawing, open it in a browser, then build the rest of your city.json interactively, clicking on paths to configure them as game objects. imagine something like this:

or that post on twitter/fedi about how cool atkinson hyperlegible is

i emailed toby (unci), the creator of monofur and eurofurence, and found out he’s still making fonts to this day! but there’s no page with all of his work in one place right now, so here’s an unofficial mirror:
https://bucket.daz.cat/uncifonts/
this includes the six typefaces from 2000 and earlier:
plus newer families from 2009 through 2020:
I really hate it when programmers abbreviate "count" as "cnt". It's two more letters, motherfucker
We talk a lot about accessibility and disability. But what we don't often hear discussed is the concept of "technological disability". That is, disability primarily due to limited technology. So let's talk about it a bit.
To get into the mindset, I want you to imagine a scenario. You're hiking in the woods and get lost. Your phone battery dead, a 3G connected Kindle your only access to wider civilization. You open up the browser to call for help, but every website you try just crashes. Damn.
This example might be contrived, but there are hundreds, maybe even thousands, of examples of devices like the Kindle. Devices that had access to the internet, in some limited form, but it was just enough for the time those devices were made. The Wii and other Nintendo devices, PSPs, low-end laptops and tablets, old PDAs and smartphones, etc.
These devices were passable at best when they came out, but now? They often can't even browse the web at all.
Modern websites use tons of memory and often a fair bit of compute too. High resolution images, more content per page, huge amounts of JavaScript powering the UI. These sites are often a struggle for even modern low-end devices.
Some might say this isn't a real problem, that at this point, nobody uses such ancient devices. But in our opinion, this is simply a matter of perspective. Technological progress is constant but updates and upgrades are not. Devices that function today, might not support a required software or hardware feature tomorrow. Think of Windows 11, an entire class of CPUs that were too old were excluded (in addition to the TPM support requirement).
Some of the beauty of the web is, to some extent, how we get to ignore the device we access it from. Software often has specific requirements about the hardware it runs on, but websites just load, we don't think about the device.
But the internet has shifted over time. Where once you felt forced to contort the page to be usable on IE 6, you now see sites which only care about working on the latest version of Chrome. Where once there was reduced functionality without JavaScript there's now no-functionality without JavaScript. Where once images enhanced content, now images are the content.
That's not to say this is bad. Technological progress is a good thing, and we don't want to comment against that. Some software progress means that device progress needs to keep up. But there's something to be said for not neglecting those who can't keep up when it's not actually necessary.
Websites like Amazon, BBC, CNN, Facebook, Google, Reddit, Twitter, YouTube, Wikipedia, etc. are ancient by internet time. They worked on a whole host of devices that today probably can't even open many of them due to unsupported encryption standards, much less actually use the sites.
This is the modern version of reddit on a Kindle: 
and this is the ancient version linked below: 
And much of the internet functions this way, except without a working version.
We're not advocating for support of insecure encryption. But we are saying that only supporting an encrypted version of a read-only website is perhaps not ideal.
There's also overlaps with more traditional accessibility and disability topics. Not making your site depend on images and giving images useful descriptions is helpful for the visually impaired. Not making a UI that depends on complex JavaScript helps with too many situations to name.
And if you can't make the main site useful, providing access to a simpler version of the site that just displays a few posts, in text, and uses basic forms without JavaScript to submit? Priceless.
At the very least, we think it's important to at least think about these issues, and acknowledge their existence. These users still exist, their needs are likely not profitable to support but profitability shouldn't be our indicator that something is worth doing.
Big tech companies knew the importance of this when it was profitable. See:
Reddit still has the ancient iOS version (though even that is somewhat annoying on Kindle as it renders very small and zoom on Kindle works by zooming the page as an image, not increasing text sizes)
In conclusion, we'd like to see more effort spent here, or at least some meaningful discussion and acknowledgement that this isn't a theoretical issue. We're sure there are good modern examples of this done right and it would be nice to see them. The overlap with more traditional disability topics is worth further exploration as well.
on the one hand, is wonderful. with things like evergreen browsers, living standards, experimental feature flags, and polyfills, the modern web evolves at an exciting pace that far exceeds any other platform.
and the old web was unquestionably worse. the waterfall approach of “standards then reality and not the other way around” made early web standards slow and out of touch. this resulted in messy browser wars, and encouraged authors to turn to proprietary and inaccessible platforms like flash. traditional release cycles meant waiting years to try new features, plus years for those features to actually reach users.
that said,
it disables people, as @irides explains, and it contributes to forcing everyone else onto an unsustainable treadmill of new hardware to keep up, which in turn feeds our destructive sandwich of resource extraction on one end, electronics waste on the other, and obscene energy consumption everywhere in between.
it also limits browser diversity, because if more or less every popular website requires an evergreen browser that supports everything, it becomes hard to make an independent and relevant browser without a megacorporation’s time and money. that’s why opera is chromium now, that’s why edge is chromium now, that’s why everything but like firefox and safari and epiphany are chromium now.
and yeah, i know i’m preaching to the choir a bit by saying this on cohost. in reality, there are a bunch of systemic reasons why this probably won’t change any time soon. planet-scale websites by for-profit developers will always treat a million users as disposable if it lowers development costs enough for their other billion users.
in theory, allow us to have our cake (developer experience) and eat it too (backwards compatibility). for example, nowadays it’s common to use the latest javascript features and just compile it down to ES5 (2009) or even compile it exactly down to what’s supported by an arbitrary percentage of the market.
but they’re not magic. you can polyfill features, but you can’t exactly polyfill computing power or bandwidth, not to mention the resultant code is often slower than if the feature were available natively. just because you can emulate the cutting edge, doesn’t mean doing so will result in anything remotely usable.
the point of this is not to say we should all go back to centering shit vertically with negative margins, var that = this, cranking out a gif for every rounded corner on the page, and web apps that rely entirely on being spoonfed gobs of html by some server every time you click on something.
the solutions are progressive enhancement, graceful degradation, and most importantly, giving a shit about people unlike ourselves. and if we respect the web’s fundamental behaviours rather than trying to bleach them into a clean white canvas in order to inevitably recreate it all in javascript, we can do more for more people with less.
the web is not meant to be a pristine medium to convey a pixel-perfect reflection of our programmer-artistic vision. it’s meant to keep us on our toes and violate our assumptions, that’s what makes it so versatile. it’s meant to be messy, that’s what makes it fun.
you can’t expect that old kindle to do everything the web can do today, but sometimes you just wanna message a friend or go down a wikipedia rabbit hole or look at some cute cat pictures, and you should be able to do that no matter what kinda device you have.
what song is like Racists by Anti-Flag in spirit, but has a german verse in the middle?
https://www.youtube.com/watch?v=ZS0sq3BeDOM&t=76s
answer: Control Alt-Right Delete by The Briggs
Ihr sagt nun 'Sieg Heil'
Ja, ich lach' mich tot
Ihr versteht nicht was ihr sagt
Wenn es das Reich noch gäbe, wäre es nach euch auf der Jagt
Ihr seid nicht das Herrenvolk
Ihr seid out-back, white trash hillbillies in suits

previously, we cracked the Ultra 5’s root password, dumped all but one of the scsi drives, built a usb input adapter, and revived borealis, the older SS5 shown above with a poorly drawn cat face (hi @lethalbit). see also:
since then, we’ve (+n) replaced the failed cap on borealis, learned how to reprogram its idprom, installed solaris on it, connected it to the internet, ironed out a bunch of usb3sun bugs, and more!
i installed the replacement for C0909, a tantalum cap that failed spectacularly but wasn’t actually load bearing. i decided to use lead-free solder for the first time (ty nathaniel), but it nonetheless went smoothly.


unsurprisingly, the nvram battery is dead, so the machine forgets the date and time along with idprom details like the default mac address when powered down for long enough. this yields a default mac address of 00:00:00:00:00:00 in solaris, which won’t work, so you’ll need to either set one after the fact…
$ ifconfig le0 ether 08:00:20:xx:xx:xx
…or program the idprom by hand, one octet at a time, which is so tedious that i’ve added a macro feature (not yet released) to usb3sun to automate that:
https://twitter.com/dazabani/status/1612487561964064768
note that the demo above had a bug where the macro player skipped the important line that actually updates the checksum. less importantly, note that the hostid i used there was essentially arbitrary, because i don’t know where to find the original.
in theory, the SS5 can run anything up to and including solaris 9, but the installer refuses to boot with only 64 MiB of memory. solaris 8 seemed to install, but then it took forever to fail to boot, so i ultimately settled on solaris 7.

the install went ok, and i was able to log in, but at first i struggled to get anywhere beyond that. it was like almost all of my clicks were being ignored, menus would open and never close, and moving the mouse would constantly select text.
turns out my input adapter had been inverting the mouse button states this whole time. when moving the mouse, we would send updates with all of the buttons “pressed”, and the buttons were only ever “released” while pressing them.
this took me days to figure out, because the guide i had been using as a protocol reference incorrectly said that the button bits are 1 when pressed and 0 when released. eventually i started doubting the axioms of my reality and found the Mouse Systems Optical Mouse Technical Reference Manual, which clearly states “(0 means depressed)”.
playing with the adapter under solaris helped me find a fix for that, a fix for the power key pin mode, a fix for the mouse baud rate, a fix to better comply with the sparc keyboard spec around idle commands, a fix for the erroneous click sound when releasing a key, a fix for the bell sound being mostly silent, and a fix for the led indicator parsing.
i also fixed the backslash key on most of my keyboards, because usb hid has separate codes for Keyboard \ and | and Keyboard Non-US \ and | (the keyboard i used to write the keymap had the latter). i wonder if this is somehow related to iso 646, which allows “national variants” to localise ascii by replacing #$@[\]{|} with more relevant characters.
usb3sun 1.0 includes all of that, plus detailed instructions for building your own prototype adapter! check out this demo to see what it can do:
https://www.youtube.com/watch?v=jpe8N0bX2XU
CDE is the newer of the two desktop environments you can log in with under solaris 7, the other being OpenWindows. i like how the widgets haven’t yet succumbed to the flat design trend that is so insufferable nowadays.
OpenWindows applications can also run pretty nicely under CDE, and i like the attention paid by those to the keyboard UX. for example, you can tab your focus onto the grip between panes to resize them, and buttons can be grouped together in the tab order to make them easier to skip.
the rest of this section is dedicated to the solaris 7 web browsing experience. that’s not a very fair or representative topic, just what i felt like writing about this time.
the SPARCstation 5 has onboard twisted pair ethernet, so you won’t need an aui transceiver like you would with the SPARCstation IPC. since solaris 7 uses static ip config by default, i needed to add a default route to reach the internet:
$ route add default 192.0.2.1
hotjava 1.0.2 is the default web browser. it has no support for css, nor does it support ssl, at least in the international version. as a result, it completely fails acid1, and is incompatible with ssl compatibility proxies like oldssl-proxy.
netscape communicator 4.51 can also be installed from a separate cd, but netscape 4.7 might just be the latest and greatest browser you can easily run on solaris 7.
installation was a little tricky, since solaris 7 doesn’t come with gzip. i wasn’t able to figure out how to install it either, so i premasticated the tarball on another machine:
$ gunzip -k communicator-v47-us.sparc-sun-solaris2.5.1.tar.gz
$ tar xf communicator-v47-us.sparc-sun-solaris2.5.1.tar.gz
$ cd communicator-v47-us.sparc-sun-solaris2.5.1
$ zcat netscape-v47.nif > ../netscape-4.7-solaris2.5.1.tar
but netscape refused to actually run unless i disabled X11 host access control, a common problem when running netscape as root (yeah yeah, i know).
apparently netscape 4 has a bug in the way it modifies $HOME to remove trailing slashes, turning the root user’s home directory of / into an empty string. this interacts poorly with the way libXau(?) in solaris 7 constructs the path to ~/.Xauthority:
$XAUTHORITY is present, just use that$HOME, which is now \0\0result[1] != '\0' (false in this case), append "/"".Xauthority", yielding uhh… .Xauthority\0step 3 was presumably intended to avoid adding a second slash when $HOME is /\0, but the code also avoids adding a slash when $HOME is \0\0, yielding .Xauthority\0, which is relative to the working directory. to be fair, that’s Not Even Wrong, depending on your interpretation of an empty $HOME.
a better workaround for running netscape 4 as root on solaris would probably be
$ env HOME=/. /path/to/netscape
netscape 4.7 supports some css, but that support was still no match for acid1.
it also supports javascript 1.3, some pre-standard DOM interfaces like document.forms and document.images, as well as the netscape-only document.layers. alert() seems to be non-blocking if you call it in a loop, which i think is a bug.
i took these screenshots with OW Snapshot, OW being OpenWindows. by default, screenshots are saved in Sun Raster format, but with the .rs extension.
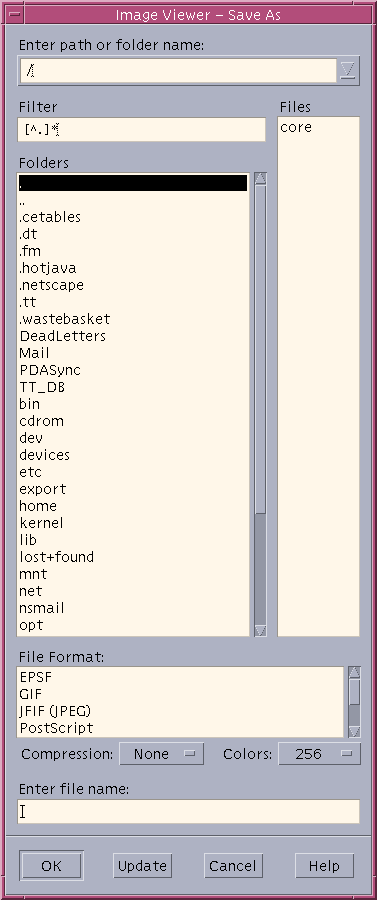
to get the screenshots off the machine, i used ftp. this was daunting at first, because setting up an ftp server can often be annoying, but it was easy with pyftpdlib:
$ cd $(mktemp -d)
$ python3 -m venv .venv
$ . .venv/bin/activate
$ pip install pyftpdlib
$ mkdir upload
$ python3 -m pyftpdlib --directory=upload --port=2121 --write
borealis has a 70 MHz cpu and its original hard drive, so it’s pretty slow. it would be fun to compare the performance with my newer SS5, which has the 85 MHz option (and a TurboGX gpu instead of a CG6).
it would also be nice to max them both out with 160 MHz upgrade kits and 256 MiB of memory someday, but their most pressing needs are probably nvram replacement and scsi emulation. who knows, maybe i’ll even try an nvram battery mod!
Drove by the Palantir building today and didn’t even stop to urinate on it



because it's bothering me today
Nothing works! Because Apple won't give these apps the permissions required to actually do anything! Some evil plot to sell more Macs, I guess.
There is literally no Android phone on the market even approaching the size of the iPhone Mini. The Zenfone 9? That's about base model iPhone size, except a few mm narrower. Ooh. The Sony Xperia series? Actual lightsabers, with a price tag to match.
I want USB-C and headphone jacks and the ability to wake up in the morning and tell my alarm that I'm good, actually. And I want that without having to destroy my hands in the process, or being forced to wield a small tablet.
Phones. They suck.
which makes iOS all the more frustrating sometimes


bring your romans inside.
ess than 2 Gbyte.

SPARCstations have a unique serial-like interface for keyboard and mouse input, using a single 8-pin mini-din port. i have a bunch of these workstations and a keyboard, but no mouse, and surprisingly this can be a fatal blocker for just installing solaris!
sun peripherals are rare and expensive nowadays, so it would be nice to be able to use any old usb keyboard and mouse. making this adapter has been a fun and useful first electronics project, but now i’m pretty much happy with my prototype.
previously i found that the rp2040-based raspberry pi pico was (bootlicking vendor notwithstanding) a pretty powerful platform that would probably work well for this project. it has a bunch of gpio, native uart + usb + i2c support, and a cool programmable i/o feature for protocols that are too fast to bit-bang in software.
i also found that while no one really sells this kind of adapter anymore, someone has designed one and released the code for it, and it’s based on the pico too! USB2Sun has keyboard and mouse support, though there are no led indicators (num + caps + scroll + compose), audible indicators (bell + click), or cold boot with the power key.
i could have just flashed that and called it a day, but where’s the fun in that? and could we design one that’s a bit more ambitious?
if that sounds interesting to you, here’s another 3700 words about this project, and all the things i learned about electronics, usb, sun machines, and programming for the rp2040.
https://www.youtube.com/watch?v=kvl7X9Ww6q4
there are two ground pins, two 5V pins, keyboard rx, keyboard tx, mouse tx, and a pin for the power key. the data pins are all 5V serial with negative logic at 1200 8N1, with the five-byte serial mouse protocol (aka Mouse Systems protocol) and sun’s own keyboard protocol (documented thoroughly in the sparc keyboard specification).
the sun side was pretty straightforward, though the sun and usb keyboard protocols use fundamentally different ways of representing key presses, so converting the latter to the former was non-trivial.
as for the mouse, most sources i could find say that the Mouse Systems protocol is 1200 8N1, and this works, but it yields a sluggish cursor that’s very annoying to actually use.
i cheated a bit and looked at the sun mouse driver in the linux kernel. turns out sun mice can run at anywhere from 1200 up to 9600 baud, and the driver detects this on the fly!
the rp2040 has native usb host support, but i didn’t have the necessary otg adapter or usb hub to use it with the pico, and i didn’t want to lose access to it as a usb device, because serial over cdc was convenient for debugging. but more about debugging later.
it turns out we can run a usb host (or two!) over gpio using programmable i/o! and my bucket of front panel bits did have several
one small challenge with these breakouts, and most of the usb header cables that they come with, is that the pinout is two-dimensional and hence not really breadboard compatible. at best we end up bridging the D+ pins and the D- pins between the two ports, so we can only use one port at a time.
even if you can get your hands on a rare usb header cable that’s split on one end (see below), the cables also tend to have proper twisted pairs and possibly shielding too. that’s great if you want a long cable with usb 2.0 signal integrity, but otherwise it’s just annoying having a cable that’s both too stiff and too long.

i solved this at first by soldering jumper wires directly to the pads of the header.

this worked well enough, but hear me out, wacky zany idea here, what if we made it breadboard compatible by uhh… “rerouting” the header pins a bit? that way we can move our prototype around as a single unit!


this was a bad idea that worked for about two (2) minutes. plugging in the breakout board and plugging in usb devices (and unplugging them) puts a lot of force on the board, the rigid coupling directs that force to the joints between the pins and the board, and removing the black plastic “backbone” that held the pins together at an even 0.1″ pitch was union busting. weakened and alone, the solder joints and pads soon ripped off the traces.

the best way i found to solve this problem was to make my own header cables with a dupont crimp and housing kit.

on the surface, talking to a usb keyboard and mouse was pretty straightforward. the HID_device_report.ino example for tinyusb gets us 50% of the way there. define a few callbacks and you get hid reports, tinyusb handles the rest.
the callback for unplugging a hid device (tuh_hid_umount_cb) didn’t work for some reason, so maybe we would leak resources if we unplugged a device and plugged another one into the same port? the callback for unplugging any device (tuh_umount_cb) works fine though. oh well, we can deal with that later.
more worryingly, many of the usb keyboards and mice i tried either didn’t work properly or didn’t work at all!
the first keyboard i tried appeared to be dead. it works fine elsewhere, but with our adapter, no tinyusb callbacks, hid or otherwise. it’s the microsoft wired keyboard 600 (045E:0750), so maybe it might be the fancy media keys or how it shows up as a composite device?
the second keyboard i tried went exactly the same. it’s the microsoft wired keyboard 400 (045E:0752), which has no fancy media keys and shows up as a single hid device, so maybe these microsoft keyboards are just non-standard somehow, i mean doesn’t linux need a separate hid-microsoft driver for them?
only the third keyboard i tried actually worked. most of the mice i tried worked, but my main mouse, the endgame gear xm1r (3367:1903), was sending some
they were longer than the 3 octets i was expecting, and the dx and dy values seemed to be signed 16-bit values, not signed 8-bit.
this is because hid devices can send reports in any format they like, as long as they can describe that format in the descriptor. mice can control the width and range of dx and dy, among other things, while the things keyboards can control include:
but many devices can or will send reports in one particular format:
this format is known as the
a fixed report format defined in the hid spec for usb hosts that don’t want to bother implementing the flexible but complicated report descriptor stuff. this includes pc firmware, as well as tinyusb’s host driver for hid. reading the tinyusb code suggests that we ask keyboards and mice to use the boot interface, but i guess they can just… decide not to?
so that part’s working as intended. if we want to support keyboards and mice that don’t support the boot interface, we need to write a hid report (and descriptor) parser. now at this point, you may be wondering about those microsoft keyboards. those i didn’t figure out until the day i wrote this chost, because of
when i plugged in a microsoft wired keyboard 600 or 400, tinyusb gave us none of the usual callbacks for that device or any device i was also plugging into the other port. it was like the usb stack crashed (well the host part at least).
ok then, let’s debug that. tinyusb has a bunch of debug logging you can toggle by defining CFG_TUSB_DEBUG to a level between 0 and 3 inclusive. long story short, it goes to UART0 (aka Serial1), so we need to disable any code that uses it for sun i/o and point our terminal at that with a picoprobe or just another pico that pipes Serial1 (UART0) to Serial (cdc).
here’s the thing right. get this. you ready? are you in the right headspace to receive information that could possibly hurt you?
this screamed race condition. we were doing something Too Fast for these keyboards. i set the debug level to 2, then started binary searching tinyusb’s usbh.c, commenting out half of the TU_LOG2{,_INT,_MEM,_VAR} lines, then half of those that remained, and so on.
eventually i narrow it down to this line in tuh_control_xfer
TU_LOG2_VAR(xfer->setup);
where i added a
osal_task_delay(100);
and voilà, the keyboards now worked without any debug logging.
speaking of debugging,
once again with no observable symptoms. i was able to work around this for a while by using analogWrite, but i wanted to use tone.
@ariashark and i spent a whole day getting to the bottom of this one, and that’s with a picoprobe, which basically turns a second pico into a gdb relay and usb-to-uart adapter, at the expense of slow firmware uploads.
long story short, we found that the pico pio usb driver was using pio state machines without actually claiming them. tone uses programmable i/o too, so it ends up clobbering one of the state machines that was being used for the usb host.
// claim state machines so that tone() doesn’t clobber them
// pio0 and pio1 based on PIO_USB_DEFAULT_CONFIG and logic in pio_usb_bus_init
// https://github.com/sekigon-gonnoc/Pico-PIO-USB/blob/52805e6d92556e67d3738bd8fb10227a45b13a08/src/pio_usb.c#L277
pio_cfg.sm_tx = pio_claim_unused_sm(pio0, true);
pio_cfg.sm_rx = pio_claim_unused_sm(pio1, true);
sun keyboards and usb keyboards have different sets of keys, and they encode keys differently.
sun keys send a make code when pressed and a break code when released, while usb keyboards (at least under the boot interface) send a list of usage ids or selectors (Sel) for the keys that are currently pressed. usb boot keyboards send eight modifier keys as a bitmap of dynamic flags (DV), rather than by their usage ids.
defining a mapping between these keyboards is not so simple, and there’s more than one right answer.
but the question we first need to answer is,
for sun keyboards, there’s the sparc keyboard spec, which pretty much just documents how the sun type 4 keyboard works, no more, no less. both conveniently and annoyingly, that’s the keyboard i already have.
but the sun type 5 and sun type 6, which were also available in the sun keyboard interface, add a bunch of new keys, complementing Delete with the full nav cluster of Insert Home End Page Up Page Down, dedicated arrow keys ← ↑ ↓ →, as well as a ⏻ (power) key.
since i don’t have either of these keyboards, i had to piece together the codes they represented from:
you might have noticed the strange LF(n) TF(n) RF(n) BF(n) notation in the links above. this seems to be a historical artifact of the sun type 3 keyboard, which had “left function” keys and “right function” keys, in addition to the usual “(top) function” keys. many of these have since been renamed, but they still live on. here’s a type 4 annotated with the equivalents:

yes, that means in sun land, the numpad is made up of “right function keys” and “bottom function keys”.
usb keyboards support far more keys than you would find on a typical 104-key pc keyboard, and the full repertoire is defined in the hid usage tables spec.
this includes most, but not all, of the keys unique to sun keyboards. for example, we’ll want to map the usb Help key to the sun Help key, in case someone finds a keyboard that actually has it, but we’ll also need to find an alternative.
most of the keys on a sun keyboard have
in usb land.
there are also some
for sun Props and =, the latter being the numpad version, we have usb CrSel/Props and Keypad =, though those are rarely found on pc keyboards. sun has Return and Enter, the latter being the numpad version, while usb has three keys with similar names:
for sun Power, we have usb Power, though that’s rarely found on pc keyboards. the footnote also insists that it’s “not a physical key”, the same treatment given to key codes like ErrorRollOver (01h), which is hid-speak for “too many keys or ambiguous”.
for sun Pause, Pr Sc, and Break Scroll Lock, we have usb Pause, PrintScreen, and Scroll Lock. but on most pc keyboards, Pause is Pause Break and Scroll Lock has no Break. since the sun type 5 keyboard moves Break to the Pause key, like on a pc keyboard, i figured sun clearly didn’t care too much which one was Break.
for sun Control, we have usb LeftControl or RightControl. sun keyboards have always had one Control, located in the spot where Caps Lock or left Control would go on pc keyboards, so i chose LeftControl. for sun Alt and Graph Alt, popular convention[citation needed] maps these to usb LeftAlt and RightAlt respectively.
as for the

wait what? the fuck is a triangle key?



i think i need to retake primary school maths, because apparently diamonds are triangles now.
anyway these are more commonly known in the unix world as meta keys, and usb calls them Left GUI and Right GUI. helpfully the footnotes for those clarifies that they are equivalent to the windows keys, apple keys (command), and sun meta keys.
those two keys also share a footnote with usb Application, or the context menu key on pc keyboards, that reads “Windows key for Windows 95, and Compose”. so by elimination, this is the key for sun Compose.
several sun keys have no equivalent commonly found on pc keyboards, or no equivalent in usb land at all, and for these we need
how can we distinguish our alternate bindings from other keys? ideally we want a key that isn’t being used by anything else, like RightControl… but as far as i can tell we’re also free to use the non-numpad Insert Home End Page Up Page Down ← ↑ ↓ →.
those nav cluster and arrow keys exist on the sun type 5, which is not available in usb, so you would think sun assigned them new sparc key codes right? but the type 4 keymaps in illumos, which are also used for sun type 5 (and non-usb version of type 6), have no dedicated slots for them.
does the Insert key on the sun type 5 just… type a 0 when num lock is on? i mean if they’re the same key code it would have to, unless the keyboard sends a Num Lock on either side?
unlike sun keyboards, which are apparently guaranteed to be nkro by the sparc keyboard spec, cheap pc keyboards tend to be 2kro plus any combination of modifiers, so let’s use RightControl as the basis for all of our bindings.
now this is where things become more art than science.
most in our position, like USB2Sun and this sun-compatible kvm switch, use a spatially accurate layout, which is ideal for users with muscle memory from actual sun keyboards. i didn’t grow up with any sun workstations though, so i went with a more windows-like layout:
but no matter what choices we make, alternate bindings that contain real sun keys have an
you can’t press key combinations involving both the target key (like Again) and the keys that represent it (like Y). worse still, combinations of two alternate bindings can become ambiguous. does RightCtrl+F1+Y mean Help+Again or Help+Y or F1+Again?
the fundamental way to solve this is to know which combinations are likely or unlikely, which only really comes with experience (and scouring docs). for example, combinations of Stop and various letters are used by the SPARCstation 5 firmware (§ 2.1):
ok promptdiag-switch? to truesun type 5 keyboards have a power key. this works like an ordinary key if the machine is already on, but it can also switch on some machines, like the SPARCstation 5.
since it didn’t exist on the sun type 4, it’s not documented in the sparc keyboard spec, and the SS5 service manual (§ B.6) just tells us pin 7 is “Power Key In”. so how does it work?
 `
`
the USB2Sun readme says “shorting minidin pin 7 to 5V rail” powers on the system, so without thinking about it too hard, i understood that as “pulling pin 7 up to 5V”. it then reads “5V rail is unpowered when the system is off”, but it took me a while to truly understand the implications.
i was using a generic bidirectional level shifter to convert between 3V3 and 5V i/o, and i had one channel free, so i figured i could use that to pull the pin up to 5V. but no matter what i tried, including pulling the pin down to ground instead or replacing the level shifter with an amplifying bjt, i could never avoid spuriously powering on my SS5 for some combination of:


furthermore the SS5 would power up if pin 7 touched pretty much anything, including the ground pins, the 5V supply pins, the other three pins, the pico’s vbus (a slightly different 5V), the pico’s 3V3 outputs, and possibly my fingers. it turns out the power pin is ~5V2 at all times, and all seven of the other pins are at 0V when the SS5 is off.
@nroach44 probed the output of the level shifter with his oscilloscope and found that it was 5V while the pico was off or under reset, which led us to believe that the pico starts with all gpios high until your program can pull it low. this contradicted the datasheet, but we’ll come back to that.
at some point, i must have forgotten to connect the ground of my pico and something else (possibly my SS5, though it’s fine), and the ~50V dc bias of the apple charger fried my pico. i had a few spare picos, but i still ragequit the project for a few weeks.
my oscilloscope arrived in the mail, and with it a way to see what the fuck was going on without a 120 km return trip. one thing i learned was that it was the level shifter that was high by default, not the pico. but more interestingly, i found that when powering up the pico from cold, at the usb cable or the wall, under reset or otherwise, all of the gpios would briefly spike up to somewhere between 1V5 and 3V (pic below is 10x probe).

the power key seemed to work by checking if current flows from the power pin, or in other words, if there was a potential difference from the pin’s ~5V2. @nroach44 suggested i replace the circuit with an n-channel mosfet with the gpio at the gate, drain to the sun, and source grounded. the gate acts as the switch, controlling whether current flows from drain to source. contrast this with how a bidirectional level shifter works:
When Lx is driven low, the MOSFET turns on and the zero passes through to Hx. When Hx is driven low, Lx is also driven low through the MOSFET’s body diode, at which point the MOSFET turns on. In all other cases, both Lx and Hx are pulled high to their respective logic supply voltages.
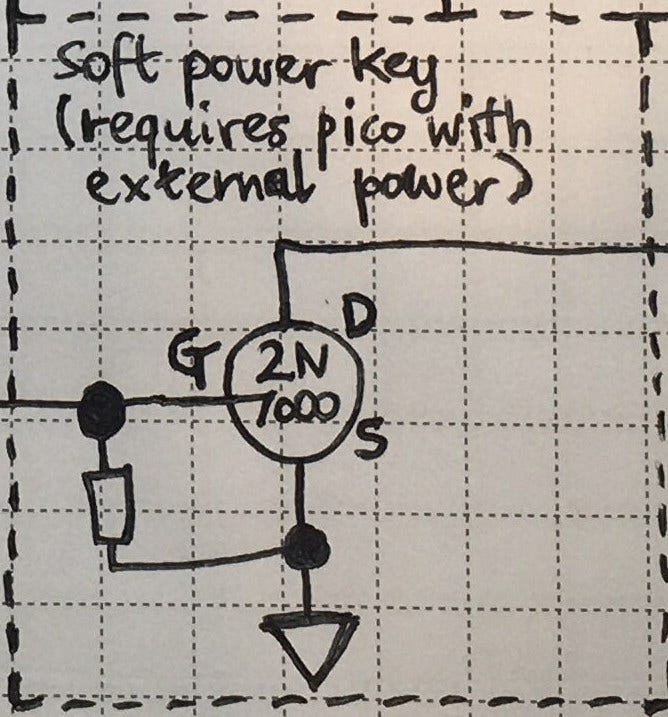
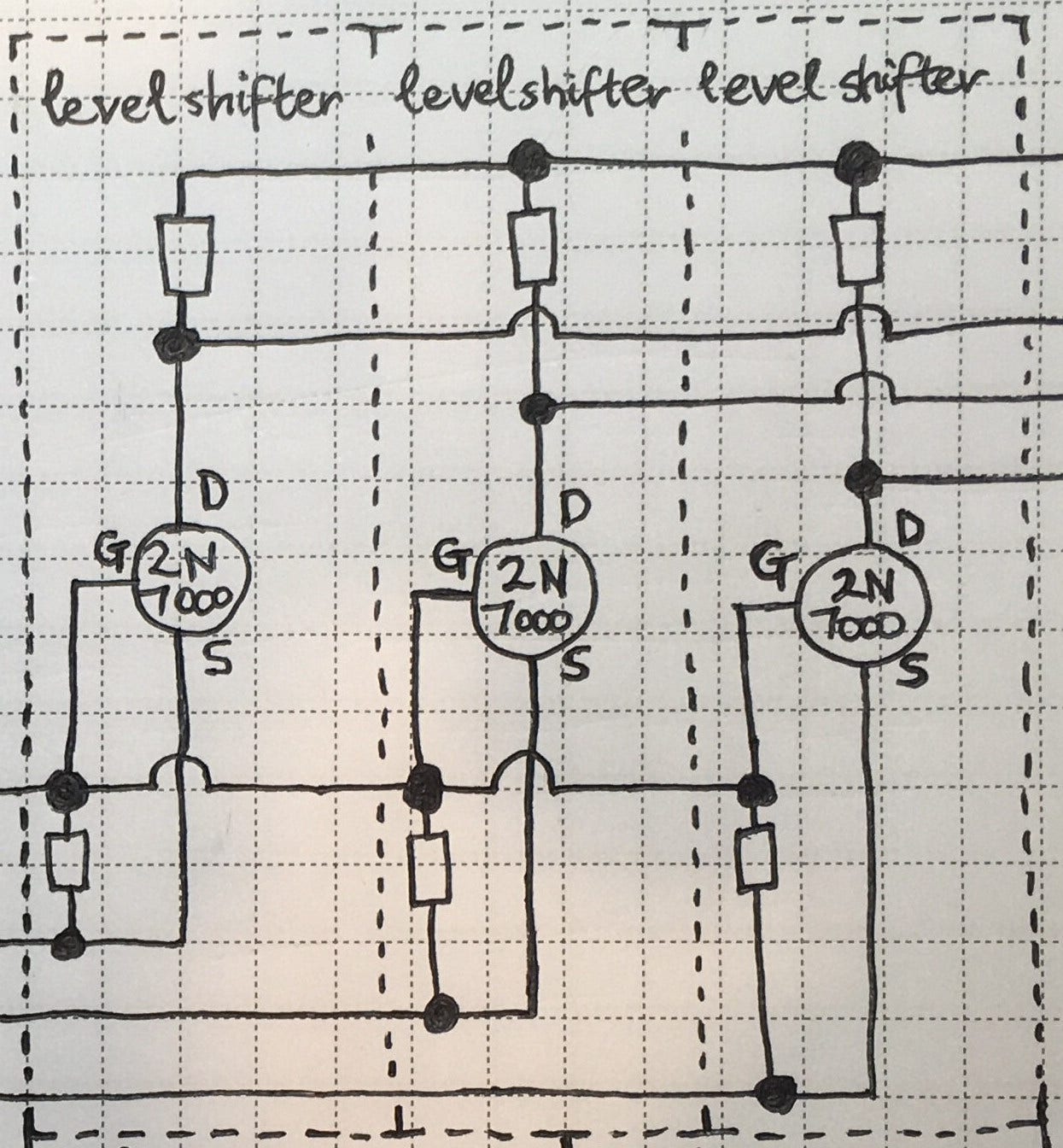
sadly this power key circuit only works if we can power the pico somehow, so you’ll need a usb cable and charger rather than just running vbus off the sun. i probed every single hole and pin reachable from outside the SS5, and the only thing powered is the power pin, which we can’t draw any current from without spuriously powering up the machine, so in practice a simple push button would outperform it.
i guess it’s time for me to learn some pcb design. hi @ariashark!
buy like five picos. one for your project, one for picoprobe, one as a usb-to-uart adapter, and a couple more in case you fry a pico with 5V i/o (less dangerous) or a flaky ground (more dangerous).
speaking of which, make sure your grounds are thoroughly connected, if not redundantly connected.
i’m sure i’ll think of more and edit them in, but i wanna go to bed first.
it’s good! took a couple hours for me to get used to the different feel and snaking sliders etc, but i think i’m just gonna stay on lazer and stop playing legacy.
i love the argon pro hitsounds too (epilepsy warning, contains rapidly flashing colours):

fuck i’m gonna have to censor my laptop when i go to conferences now won’t i? ahh well

it’s tyool 2008. you just started high school (year 8, not year 7). you go to the canteen and what do you find? nudie nothing but 4½ oranges™©® double pulp? pfft, no. that would be a very good choice, if you wanted a Proper orange juice, and if your canteen even sold it, but who could afford that shit with $3 a day^ of lunch money?
the internet (and the photo above) would have you believe that the magical liquid in question looks like one of these…


…but that wasn’t always the case! it actually looked more like this:
^ or $0 a day, if you weren’t white


(we cracked the top case by accident (but i reckon this looks better anyway))
by @ariashark, assembled by both of us
* experimental, might wipe at any time
https://www.youtube.com/watch?v=LgXrhrFFClY
updated version in nixpkgs landing soon:
your video (audio) looks (sounds) like i would have sent it as a crusty .3gp (.amr) to my high school buddies over infrared in 2009

my real no thoughts head empty arc.
day 1: not too bad, pretty lethargic but i watched wtyp for most of it and even managed to cook
day 2: very very tired and almost impossible to read any long prose, bad sensory time until i had some weed, but hey, i managed to brush my teeth
day 3: better, psych day, cooked again, and played and beat parappa the rapper
day 4: about the same, played and beat parappa 2, cooked yet again, and went to the pharmacy
day 5: better again, christmas with @ariashark and kk9
day 6: about the same, more christmas with kk9, though playing jackbox i felt like paul erdős staring at a blank piece of paper that one time
day 7 (low dose v50+d5): excellent, really recaptured the magic of amfetamine! cooked chicken and rice, redid the barrier spray, and played a bunch of osu and valorant
day 8 (low dose v70): not exceptional but still good, cooked bolognese, built keyboards with aria, and played some more osu with said keyboard
day 9 (low dose v70): about the same, built an oscilloscope, washed bedding, and watched knives out with aria
overall another successful tolerance reset, such that 70 mg lisdexamfetamine is more than enough for me again, and easier than last year too!

“average pp map has 2000 overweightness” factoid actualy just statistical error. average pp map has 300 overweightness. Harumachis Georg, who is 30 seconds long & has over 5400 overweightness, is an outlier adn should not have been counted
my real no thoughts head empty arc.
a great bunch of videos by BadEmpanada.
the term “self-determination” should be about rejecting colonial power, but has grown to cover many disputes with very little in common.
in practice, whenever convenient, states use it as a rhetorical device to justify self-interest annexations and/or further colonisation.
https://www.youtube.com/watch?v=1W_UH4fmyj0
“[…] terms such as genocide are appropriated, monopolised, and weaponised by the most powerful [entities], who try to ensure that they are defined and understood in such a way that they can be used against their enemies but not themselves”
https://www.youtube.com/watch?v=m316DcYhb8w
those entities did the same thing with the term “terrorist” (and previously “anarchist”), weaponising it to delegitimise their enemies, and in turn creating the need for terms like “freedom fighter” on a euphemism treadmill.
maybe we should do away with those?
a great bunch of videos by BadEmpanada.
the term “self-determination” should be about rejecting colonial power, but has grown to cover many disputes with very little in common.
in practice, whenever convenient, states use it as a rhetorical device to justify self-interest annexations and/or further colonisation.
https://www.youtube.com/watch?v=1W_UH4fmyj0
“[…] terms such as genocide are appropriated, monopolised, and weaponised by the most powerful [entities], who try to ensure that they are defined and understood in such a way that they can be used against their enemies but not themselves”
https://www.youtube.com/watch?v=m316DcYhb8w
those entities did the same thing with the term “terrorist” (and previously “anarchist”), weaponising it to delegitimise their enemies, and in turn creating the need for terms like “freedom fighter” on a euphemism treadmill.
and not “hacked on the sticks”
and if you are doing std::mem::uninitialized shit you may as well be wearing a clowns suit
look i get how finite prescription repeats can encourage doctors to review your situation and make sure you haven’t racked up twenty different meds, half of which you don’t need anymore but are creating myriad interactions with the other half.
but there must be a better way than forcing me into consults every six months, with multiple doctors, to continue taking any of my medications. some of which i’ve been taking since 2015 and all of which i’ll need for the foreseeable future.
my pdoc charges 300 aud/session (−$119.50), and yet on multiple occasions, writes me scripts with not enough repeats.
my gp charges 83 aud/session (−$39.75), and is consistently booked out 2–3 weeks in advance unless i go with one of the other doctors, who are often too 👻 scared 👻 to write some of my scripts because they “don’t really know hormones”.
both require making phone calls to book, to add insult to injury, and it doesn’t have to be like this! my last two (and @ariashark’s last) general practices all had online bookings, and aria’s last also did online script requests for a small fee.
.oO( maybe youse wouldn’t be so swamped all the time if we weren’t forced to waste your consult slots just for scripts? )
bonus: agomelatine comes in packs of 28, unlike all the other daily meds i take which come in packs of 30, so it always runs out a bit faster. but even if it was 30, there are 181–184 days in any six month period, so writing me 30 days plus six repeats of anything and telling me to come back in six months literally doesn’t add up!
bonus bonus: my current gp can no longer jump through the necessary hoops to write me two boxes of 25 mg at a time for some reason, so i need to get it from my pdoc or fill it twice as often to take 50 mg/day. (i think they need to call the authority number, which is weird because it’s not on the pbs?)
look i get how finite prescription repeats can encourage doctors to review your situation and make sure you haven’t racked up twenty different meds, half of which you don’t need anymore but are creating myriad interactions with the other half.
but there must be a better way than forcing me into consults every six months, with multiple doctors, to continue taking any of my medications. some of which i’ve been taking since 2015 and all of which i’ll need for the foreseeable future.
my pdoc charges 300 aud/session (−$119.50), and yet on multiple occasions, writes me scripts with not enough repeats.
my gp charges 83 aud/session (−$39.75), and is consistently booked out 2–3 weeks in advance unless i go with one of the other doctors, who are often too 👻 scared 👻 to write some of my scripts because they “don’t really know hormones”.
both require making phone calls to book, to add insult to injury, and it doesn’t have to be like this! my last two (and @ariashark’s last) general practices all had online bookings, and aria’s last also did online script requests for a small fee.
.oO( maybe youse wouldn’t be so swamped all the time if we weren’t forced to waste your consult slots just for scripts? )
So exactly one person is posting speedruns of GITCL on speedrun.com and normally I don't like looking at speedruns but... I mean... obviously I'm gonna look at one of my own game. Unsurprisingly it is insanely fucked up but also thankfully not nearly as fucked up as I feared? Like it's "oh lmao I guess that was exploitable" fucked up, not "how did I ever think this game worked properly" fucked up, at least!
That said it is bonkers to me that the no DLC speedrun is TWICE THE LENGTH as the one where you do the DLC, despite the fact that you... have to do the DLC. Which has a ton of mandatory random encounters and a boss that I'm continually nervous that I gave too much health to. (Whenever I revisit her for testing purposes, the Jill fight always takes long enough that I'm like "uh, maybe this was a bit much.") Anyway it turns out the reason why is because they figured out a combination of things that lets you do like 1000 damage in a single hit against normal bosses, and positively absurd numbers against bosses with elemental weaknesses. I had no idea the numbers could go this high. This is a game where 99 is considered a lot. The toughest bosses have like 8000 HP. If I had known, I would have implemented a Final Fantasy style max damage!

Anyway despite all that it's... actually, I'm kinda satisfied seeing it? The goal with the DLC items was to give players stuff that could POTENTIALLY be exploitable, but in a "you gotta understand the systems to know what to combine it with" sort of way, not a "this straightforwardly does more damage than everything else" sort of way. And I guess that turned out to be the case! I bet this was really fun to figure out.


And in the no DLC run, honestly, the big fights actually seem to pretty much line up with how I balanced them—even in hyper efficient play, they actually do stay roughly within the player damage spread that I intended, nothing is straightforwardly a pushover. That's pretty cool! Wow! GITCL was definitely a learning experience for me to develop and I had to figure out a lot of stuff about balance as I went along, but like... if the systems can withstand this much pressure and still be fun, I feel like that's a huge W! Watching this insane bullshit actually does make me feel like I got a lot of things right. Well, other than not having a damage cap lol.
watch me type on my sparcstation 5 with a usb keyboard :D
https://osu.ppy.sh/beatmapsets/1896477#osu/3908451
timing’s much cleaner on this one, and the song’s mix of 1/4 and 1/3 rhythm was fun to build patterns around. come watch me hitsound the map: https://www.twitch.tv/azabani
edit: hitsounding done below!
(we cracked the top case by accident (but i reckon this looks better anyway))
by @ariashark, assembled by both of us
The Latin-1 that has some random subset of germanic and maybe like french if you squint and that's apparently fine? The iron curtain has fallen, for better or for worse, since the 80s. If that's the "solution", then leave "C" 7-bit. I'm gonna assume that's a joke.
Are YOU a CSS BABY???
Are your friends doing stupid css tricks and leaving you feeling left out?
Do you wish  Certified Computer Professional
Certified Computer Professional 
Eevee From Pokémon would help you out?
ok i'll do my best
i'm guessing you want to know css specifically for goofing around on cohost, which makes it a little different. several features are unavailable, several other features are only possible with creative trickery, and everything else is kind of an ugly mess
if you want some real guidance then i assume the MDN tutorial is pretty solid but we want to get to the 🥳 Fun Stuff 🥳Fun Stuff
so here is the crash course!!
CSS is (ideally) how you specify the appearance of HTML, including both purely aesthetic stuff (colors and italics and whatnot) and fundamental layout stuff (how things are arranged)
so you have to also understand HTML, which luckily is pretty basic
<p>for example each of these paragraphs is wrapped in "p" <em>tags</em>, thus creating a "p" <em>element</em>. elements can be nested, although there are some rules as to what can contain what — a "p" cannot contain a second "p", for instance, because that just doesn't make sense. but it can contain an "em", short for "emphasis", which makes text italic.</p>"tag" versus "element" is one of those things where the two terms are almost always interchangeable, except for the 5% of cases where they're not, and then if you mix them up nerds will look at you funny but still understand what you mean. sorry, it's like learning idioms in a foreign language
the tags we will be most interested in for our cohosting purposes are the following:
<div>, short for "division" i guess, which is a block element (we'll get to that in a hot minute) with no special behavior. it's basically designed to be a blank canvas for slapping CSS onto.
<span>, short for... "span"? which is an inline element with no special behavior.
in special cases, <details> and <summary> to make clickable things
@noracodes has assembled a full list of allowed tags.
"wow eevee i've been reading for like ten minutes and i still don't know how to make gradient text" ok ok fine hang on
CSS is made up of a bunch of different properties, which you can assign to elements.
the normal way to do this is to have a thing called a stylesheet, which can apply properties to a bunch of HTML elements at once. so like the classic example is that you can make every <h1> on the page — that's a level 1 heading — be colored red like this:
h1 {
color: red;
}there are two mechanisms for doing this — a <link> tag pointing to a stylesheet in a separate file, or a <style> tag containing a stylesheet directly — and unfortunately cohost forbids both of them. which is pretty reasonable since it would let you absolutely fuck up the whole contents of the site. so forget the last three paragraphs.
also that's what CSS looks like. it's a lot of property name, colon, value, semicolon. "value" can look like several different sorts of things though.
instead, what we can do is use the style attribute on any element. so you can write this if you like:
<h1 style="color: red;">hey guys whats up</h1>unfortunately, for cohost purposes, you will then have to put that same style attribute on every single <h1> you use. sorry, them's the rules. if you were making a real website then you would almost never see style="...", precisely because it leads directly to copy/pasting the same blobs of junk all over the place
alright well that's great and all but what are some cool CSS properties?
im getting to it!! here are some common baby properties to get you started. you can look them up on MDN if you want excruciating detail also. slap any of these bad boys in a post like this
<span style="...">Your Cool Text Here</span>color: red;
change the text color. surprise!
font-size: 0.75em;
change the text size. this is a different sense of "em" which specifies a length, and i'll get to that in a bit, but the important bit is that this example will make the text 25% smaller
font-style: italic;
make text italic. use normal to undo it. i think font-style can do something else too like oblique? what is that, italics but the other way? no that looks like normal italics to me. welp no idea
font-weight: bold;
make text bold. you can also do bolder text and even light text, though i think you need font support for variable bolding like that. basically i have never in my life seen anyone set this to anything but bold
font-family: serif;
change the font. you can actually put in a font name here (wrapped in quotes if it has spaces), but guessing which fonts other people have installed is kind of a crapshoot. you can also put a series of fonts separated by commas, and the browser will use the first one that's available.
but the usual thing i do for cohost is use one of the generic family names (which you should always have as the last in your font list anyway), in which case the browser will just pick a relevant default: serif, sans-serif, monospace are the most reliable; cursive and fantasy are possibly more hit-or-miss (i get Comic Neue and Impact, what?); and i have never seen anyone use system-ui, ui-serif, ui-sans-serif, ui-monospace, ui-rounded, emoji, math, or fangsong.
text-decoration: underline;
underline text. this is our first property that can do some fun variant stuff, because it's actually four properties:
so now you can, i dunno, call out your own typographicla errors:
so now you can, i dunno, call out your own <span style="text-decoration: wavy underline red;">typographicla</span> errors:great job! you have already grown into a CSS Toddler
i keep saying "color" and "length" and these are two particular things of things so i should probably touch on those
you can write out colors a whole bunch ass of ways. mdn lists them all but here are the good ones
a color name like red. there are a number of these but for the most part i just use really basic color names off the top of my head when i don't care too much about the specific color
the color name transparent, which is transparent. i believe it's specifically transparent black, but css is clever enough that it works how you'd naïvely expect. if you don't know what subtle problem i'm alluding to then don't worry about it, css has just saved you four paragraphs of tedious explanation
a six-digit hex value in the form #rrggbb, which you can get from any color picker in the whole entire world
a three-digit hex value in the form #rgb, which will effectively double each digit to make a traditional six-digit value. this is especially nice for grays (#999), kinda retro DOS-like colors (any combination of 0, 5, a, and f), or taking a wild swing at a color off the top of your head if you are good at RGB in your head.
a four- or eight-digit hex value, which is like the above but with an alpha (transparency) channel added: #rgba or #rrggbbaa. i'm especially a fan of this for stuff like shadows; #0004 is my go-to 25ish% opaque black.
an HSL color of the form hsl(360, 100%, 50%). i like these because they're fairly intuitive (if you can remember how hue maps to the spectrum) and you can change the hue to get colors that are "about as light" without much fucking around.
if you're unfamiliar: HSL is short for hue, saturation, lightness. or... luminosity or something. truly, no one knows.
"hue" is a number from 0 to 360 specifying where you are on the color wheel — 0 is red, 120 is green, 240 is blue. with a little subdividing you can find some other familiar spots: 30 is orange, 60 is yellow, 210 is azure, 300 is purple, 345 is pink. i almost never have any need to move in smaller than increments of 15
"saturation" is how gray the color is. 0% gives you a gray; 100% gives you a pure color.
"lightness" goes from black at 0%, to the most intense color at 50%, to white at 100%. this one might feel a little funny to some people but i like that you can get pastels just by using lightness of like 95%
additionally you can add a fourth argument for alpha, either as a percentage or a number from 0 to 1. i always thought you had to write it as hsla(...) if you used an alpha channel but i'm looking at MDN now and maybe that's not necessary any more
variations you might see in the wild: hue is obviously a number of degrees, and can be given in angle units, such as 90deg or 1rad or 0.5turn. there's also a new syntax that looks like hsl(360 100% 50% / 25%) but i don't know why they felt the need to do this
you might also see RGB colors written out with decimal numbers as rgb(48, 96, 255) but this is mostly used as an output for tools? i don't know why a human being would write this by hand
the special color name currentcolor refers to the current text color. occasionally useful in css trickery but probably not so much on cohost
there are some recent additions that are more complex, mostly to do with colorspaces, but i've never seen them in the wild.
a length is, generally, a number with a unit after it. there is no space between the number and the unit. so two pixels is written as 2px.
(some other things are written in similar ways but with different units, like 90deg.)
the one exception is that you can (usually) write a zero length as simply 0, because the units don't matter then.
common units include:
px, for pixels. it's not real pixels. but also it sort of is. don't worry about it. generally reserved for small precise things, like single-pixel borders.
em, a printer's term, which in CSS refers to the current font size. this is why you can use it in font-size to scale the font size! the spacing between and around elements is often given in ems. it's nice that it scales relative to the text size, and it saves you from having to think in very fine increments for big chunky amounts.
rem, or "root em", which refers to the base font size for the page. most of cohost's own CSS is given in terms of this. putting a 1rem space around something will scale relative to the page's normal text size, but will stay the same size even if you put it on an element with big text. if you don't change the text size then this is equivalent to em.
vw and vh, which are 1% of the width and height of the browser window. (the part showing the page, not including the title bar and sidebars and whatever.) this is mostly helpful for arranging something compactly on a screen of any size without scrolling (e.g. game ui), but it might also come in handy for trying to get a css crime to scale down to mobile as well. you can also use vmin and vmax, which refer to the smaller and larger of those two dimensions.
sometimes, for some properties, you can also use a percentage instead of a length. (a percentage is not itself a length!) what it means varies, and can be kind of unintuitive, but that mostly comes up with layout stuff, which we'll go into later.
there are, naturally, very many more, but most of the others have very niche uses.
text-shadow: 3px 4px 1px orange, ...;
add a drop shadow to text. that's a lot of numbers, but they are X Y BLUR COLOR. the first two are how far away from the actual text to draw the shadow (negative offsets are ok), and the third is how much to blur the shadow (use 0 or just leave it off for no blur). the color can also go first if you like.
you can specify multiple shadows by separating them with commas. (the first one listed is the one on top, which might matter if you use translucent colors.) you can use this to clumsily emulate a text outline, by
drawing the same "shadow" in all four diagonal directions
however there is also
-webkit-text-stroke: 1px pink;
oh boy! this one has some history. it's not standard and was invented by apple for mobile safari — hence having the funny "webkit" prefix — but web developers are fools who don't remember the IE6 days and made a bunch of stuff that assumed safari would always be the only mobile browser, which caused some problems when mobile firefox was released. mozilla didn't have access to a witch who could fix a whole mobile web's worth of existing sites made by clowns, so they did a big sigh and implemented some webkit-only properties.
most of them were eventually standardized and use of the -webkit stuff gradually faded, but this one was not. probably because it's butt ugly in most cases and what you actually want is a text outline. but i'm mentioning it here because i used it for the first line of this post.
you can fix this with the SVG property paint-order: stroke fill;, which instructs the browser to draw the stroke first and then the text on top, which emulates an actual outline.
however, comically, this only works in firefox! chrome seems to ignore it on html elements. welcome to web development. even in firefox it's a bit funky anyway. also this won't help for certain kinds of other tricks
background
this one does a lot of things. it's actually shorthand for like ten other properties. actually a lot of properties are shorthand for more specific properties, and the cool thing is that css generally lets you put the parts in any order and is designed so it can tell what you mean. the bits most of interest are as follows:
obviously you can set a solid background color.
you can also set a background image, using url(https://...). by default that will just tile, but you can control the starting position, size, and tiling as well. this stuff is pretty cool and flexible (like contain and cover to adapt to the size of the element), but background images are kind of janky most of the time so i don't think i need to super go into it. but for example here is background: url(https://c.eev.ee/cohost/verifyed.svg) center / 1em;. wow! what a nightmare.
it's considered polite to name a color alongside an image background, even if the image is totally opaque. that way the text is likely to be legible even if the image fails to load.
you can also set a gradient and i cannot understate how fucking amazing that was when it first came out. it doesn't seem like a big deal now that we're all about flat design, but in 2007 at the height of the skeuomorphism frenzy, everything had a fucking gradient on it, and web devs were doing the most grotesque stuff to generate them on the fly and whatever. but now you can just write them in css and the browser does it for you!
that one looks like this:
background: linear-gradient(to right, hsl(210, 100%, 95%), hsl(345, 100%, 95%));the linear-gradient() thing is technically a type of image, so it goes where url() goes. the first argument, to right, gives a direction; you can also name a corner (to bottom right) or an angle (45deg) or just leave it off for the default behavior of a vertical gradient. after that is a list of colors. you can optionally put percentages after them to specify where along the gradient they appear, or otherwise they'll just be spaced equally. so red, black is equivalent to red 0%, black 100%. you can even give two positions for a color, and then everything between those positions will be a solid color. and if you do something like red 0% 50%, black 50% 100%, where two colors "claim" the same position, then you'll get a hard transition from one to the other.
a gradient has no set size and will expand to fill whatever it's background...ing. you can change its size like any other image, or there's a repeating-linear-gradient().
there's also radical gradients and conic gradients and some other little tricks you can do, but i guess just peruse the MDN page
also, like with text shadows, you can have multiple backgrounds. so if you use translucent colors, you can stack gradients:
but wait, that's not quite all! there's one cool trick that doctors hate!
one of the background sub-properties is called "clip", and it controls how much of the element the background appears under. you can use it to like, make the background not draw under translucent borders i guess, which is sort of a niche case.
except for one specific value: text, which makes the background draw only under the text. so with background: linear-gradient(to right, purple, teal) text;, you can get gradient text with absolutely no effort at all. just remember to make the text itself transparent, or at least translucent, else the text will just draw on top of the background and it'll look like nothing happened
wow i just discovered something really cool about how gradient backgrounds interact with inline boxes but i'll have to save that for later
also i lied a bit, because speaking of webkit, it still only supports this with a prefix. so you actually have to do it in three passes:
background: linear-gradient(to right, purple, teal);
-webkit-background-clip: text;
background-clip: text;relevantly, one downside of this is that if an ancient browser like chrome doesn't support the text clipping, then you'll just have transparent text on a regular background (or possibly no background at all). and that's not great. there's a gizmo for detecting feature support, but it only works in stylesheets, so we can't use it. whatever, not our problem, we're doing Crimes
filter: blur(1px) ...;
ohh nooo. this one has mostly three uses: immensely clever special effects, cool subtle touches, and the most godawful eye strain you've ever seen in your life.
this is a space-separated list of any combination of filter functions:
blur(LENGTH)drop-shadow(...)brightness(AMOUNT)contrast(AMOUNT)hue-rotate(ANGLE)saturate(AMOUNT)grayscale(AMOUNT)sepia(AMOUNT)invert(AMOUNT)these all do pretty much what they sound like, if you have ever used an image editor. AMOUNT is either a plain number or a percentage. usually values over 100% don't make a lot of sense, but up to 200% is ok for brightness/contrast. invert(50%) is a very roundabout way to make a solid medium-gray box. also there's no "colorize", but you can fudge it by combining sepia(100%) with the others.
you can only put one shadow definition per drop-shadow(), but you can use drop-shadow() itself more than once. though then the first shadow might get shadowed again? i guess i could just try it ok whoa that's kind of cool
cursor: help;
this specifies what mouse cursor you get when you point at the element. this whole paragraph should have a help cursor in fact. there's a whole big list of standard cursor names like pointer, but you can also use a URL to an image, or you can use none if you want to be very rude
opacity: 0.5;
this is not very interesting for plain text. but you can use it with images (if you write them as html rather than markdown, with <img>), and maybe it'll be more interesting later with fancy boxes. honestly though i can't remember the last time i used this; there are so many more interesting ways to mess with opacity in css nowadays
browsers support data: urls, which look like urls sort of but they have the entire file stuffed into them. you can use these in css too if you want to include a rinky-dink image but don't want to upload things. unfortunately i am a turbo nerd and the only way i can conceive of constructing one is with the base64 command already on my system so you're kind of on your own there, but they look like this
data:image/png;base64,wiuh987y349rh90347853y4h7236y4
except they are one mile long.
just slap one of those in url() and you're good to go. cohost even uses these for stuff like the cutout on avatars, which i copied for my avatar at the top of this post. here it is
data:image/svg+xml;base64,PHN2ZyB3aWR0aD0iMjAwIiBoZWlnaHQ9IjIwMCIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj48cGF0aCBkPSJNMTAwIDBDMjAgMCAwIDIwIDAgMTAwczIwIDEwMCAxMDAgMTAwIDEwMC0yMCAxMDAtMTAwUzE4MCAwIDEwMCAweiIvPjwvc3ZnPg==
chef kiss
because cohost actually implements markdown correctly—
RAPHS oh thank you.
ahem.
because cohost actually implements markdown correctly, you can sprinkle line breaks throughout your html and css crimes without fear of an errant <br> ruining your day. in fact, html cares so little about whitespace that you can stick line breaks inside the style attribute, if that helps.
<div style="
color: blue;
background: red;
font-size: 2em;
">
graphic design
is my passion
</div>
i'll spare you the preview of what that looks like. you don't need to indent if you don't want to, either, but it mostly doesn't matter. just make sure you DO NOT leave a blank line anywhere, or it will probably be interpreted as a paragraph break.
if you write a css property without a value, cohost will choke on your whole post and strip all the html. i've done this by accidentally typing something like font-style-italic;. it's kind of annoying to find the problem when this happens but at least you know what to look for.
you can't put a <div> inside of a <span>, for reasons we will get to in a future post. you also can't put a <div> inside of a <p>. so if you're doing nonsense in the middle of a normal line of markdown text, you must use <span>s only.
eggbug tries to read your post like a browser would, and then eats anything that it doesn't like the look of. if something truly bizarre is happening, you might have forgotten an end tag or quote or > somewhere, and eggbug has decided everything following that is suspicious and eaten all of it. that is very good for eggbug but not so good for your post. luckily the problem is likely to be near where things start going awry.
markdown stops working while you are inside html. so you gotta write out all your links and images and bolds and stuff by hand sorry. however @'s do work
that should open a panel that shows you behind the curtain. using the developer tools is beyond the scope of this terrible post, but this should show you both the html structure and the css properties for each element. you can even change those properties live, or add new ones! great both for seeing what someone else has done, and for trying stuff out without switching back and forth between compose and preview. just be aware that this isn't permanent, and as soon as you go to another page (or even switch back to "compose") your changes are lost.
this took an inordinately long time already and we haven't even mentioned box layout yet but i hope this will help some css babies evolve into, i don't know, css tweens? wait, no, those are for later
if there is interest and my adhd cooperates then my rough plan is like, 2. blocks and block properties and the details element, 3. flex and grid, 4. animation and shenanigans
these aren't necessarily relevant they're just the tabs i have open at the moment and may be interesting

commission by Magicdawolfy for my tablet cover!
previously we looked at some sun sparc machines for the first time. we got two of the five running, and managed to dump the ide-based Ultra 5 with a usb-to-ide adapter, but none of the scsi-based machines.
since then, we (+bkn) have cracked the root password of the Ultra 5, dumped most of the remaining machines, got the dead SS5 working, and started building an adapter to use usb input devices with the sun 8-pin mini-din interface.
solaris uses the classic salted-des-based crypt(3), which in theory would make cracking the root password pretty easy. i used my RX 6650 XT (~147 MH/s), nathaniel his RX 6800 (~582 MH/s), and kieran his RX 6700 XT (~500 MH/s).
$ hashcat --session luds -m 1500 -w 2 --increment -a 3 -1 \?l\?u\?d\?s 7GX.9SY2Pb6sY \?1\?1\?1\?1\?1\?1\?1\?1
--session gives this job a name that can be used with --restore-m 1500 is salted-des-based crypt(3)-w 2 competes somewhat aggressively with other gpu work--increment automatically tries prefixes of \?1\?1\?1\?1\?1\?1\?1\?1-a 3 is mask attack mode-1 \?l\?u\?d\?s defines \?1 as any lower or upper or digit or symbol7GX.9SY2Pb6sY is the salted hash\?1\?1\?1\?1\?1\?1\?1\?1 means try eight characters matching \?1, which is the maximum for this hashing algorithm anywaythe good news was, my amd gpu Just Worked™ on nixos with minimal config, whereas hashcat was (as far as i can tell) completely broken for nvidia gpus.
hardware.opengl.extraPackages = with pkgs; [
rocm-opencl-icd
rocm-opencl-runtime
];
the bad news was, the password was going to be the (maximum) eight characters, and our hash rates were bleak. to use mine as an example:
?l?d (26+10)^8/147000000/86400
= .222120646 days
?l?u?d (26+26+10)^8/147000000/86400
= 17.191051397 days
?l?d?s (26+10+33)^8/147000000/86400
= 40.454016631 days
?l?u?d?s (26+26+10+33)^8/147000000/86400
= 522.345388707 days
so we each tried something different. nathaniel stuck with ?l?u?d?s (full ascii) but switched to an RTX 2060 (~647 MH/s), kieran specialised with rockyou-7-2592000.hcmask, and i specialised with ?l?u?d (no symbols). it took us almost two days, but we did it! the password for 7GX.9SY2Pb6sY was G1tfoGro.

in the pc world of the 90s, ide reigned supreme, but scsi was the standard pretty much everywhere else, including old macs and most of our SPARCstations.
the only time i had ever worked with a scsi hard drive was when dumping the proliant 800, but i managed to do that in situ (with great difficulty) by booting damn small linux and attaching an ide hard drive. neither of those things are available to our SPARCstations, so we needed a different approach.
we hadn’t really worked with scsi drives much, only ide. brock and nathaniel had scsi controller cards, and i had some cables, but none of us had the single connector for both data and power (sca). thankfully the adapter we ordered arrived just in time.


the first scsi card we tried didn’t show up on the bus, and appeared to even kill the pci slot for subsequent cards! it was probably dirty contacts, and we managed to get a second card working after some fiddling. it only had a 68-pin connector internally but not 50-pin, so brock found a cute little adapter to convert between just those two.
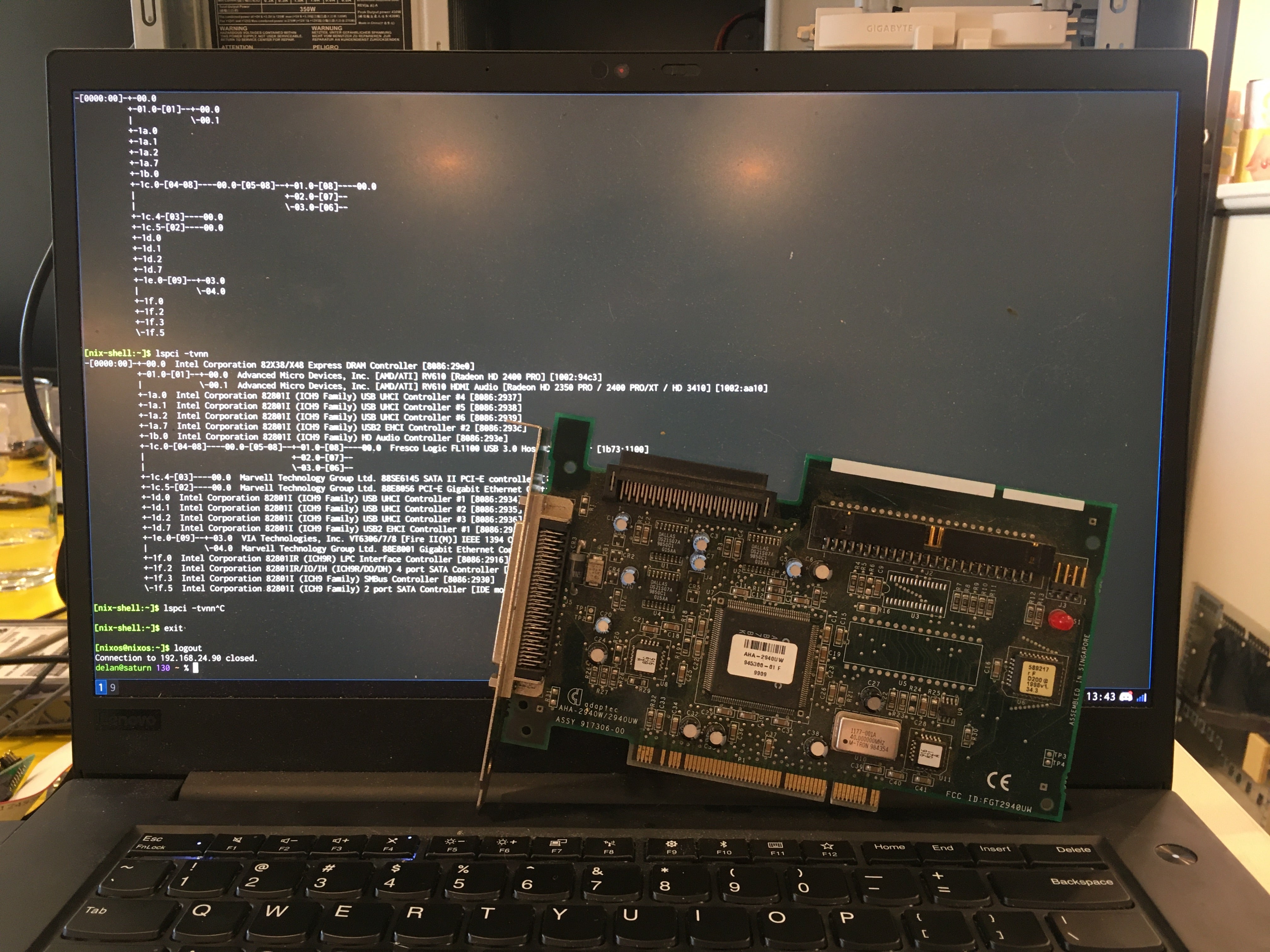

dumping both kinds of disks was pretty straightforward. power down the support machine just to be safe, connect a disk, lsblk, ddrescue. unfortunately the disk in the rusty IPC (serial number 134F2609) failed to spin up or even appear on the bus. one of the SS5 boxes has two disks, so maybe we can give that IPC one of those when we repair it.
% paste <(du -sB 1 *) <(sha256sum * | cut -c 1-64)
212910592 131F2926.img 49fda241d7e1cacccd1738a4401642be22665b6f9c445f0bb142123b47394062
2149761536 507FA05C.img 6527d223b41997cfba0b888de3f4c53d79242dd4b1b575a2a64e4f2e747d24c7
546079232 538F1242.bottom.img 5f3aa1b5ccc2a6069141d9f0a752e59bd508684561a047a1b6c4b3e62cc077ee
546079232 538F1242.top.img d9131ba587bcb29b18c0230fa017d419753821f2dfeaeb56c9bb2840812aa488
4306485760 FW84450552.img 266cb20bf33f9102e587796ee071bc20ade3e2849ee3cbfa5b878f970c136a17
previously this SS5 blew one of its tantalum caps (C0909, 15 µF, 35 V) when we tried to fire it up. nathaniel suggested that it might have been a decoupling cap, run in parallel to some actual functional circuit, so we desoldered it and the machine indeed booted! unlike the other SS5, the nvram battery seems to be dead here.

we weren’t able to boot the existing solaris install, so we tried installing solaris 9, the last version with sun4m support. the installer failed to boot due to insufficient memory, so we tried installing solaris 8 instead.
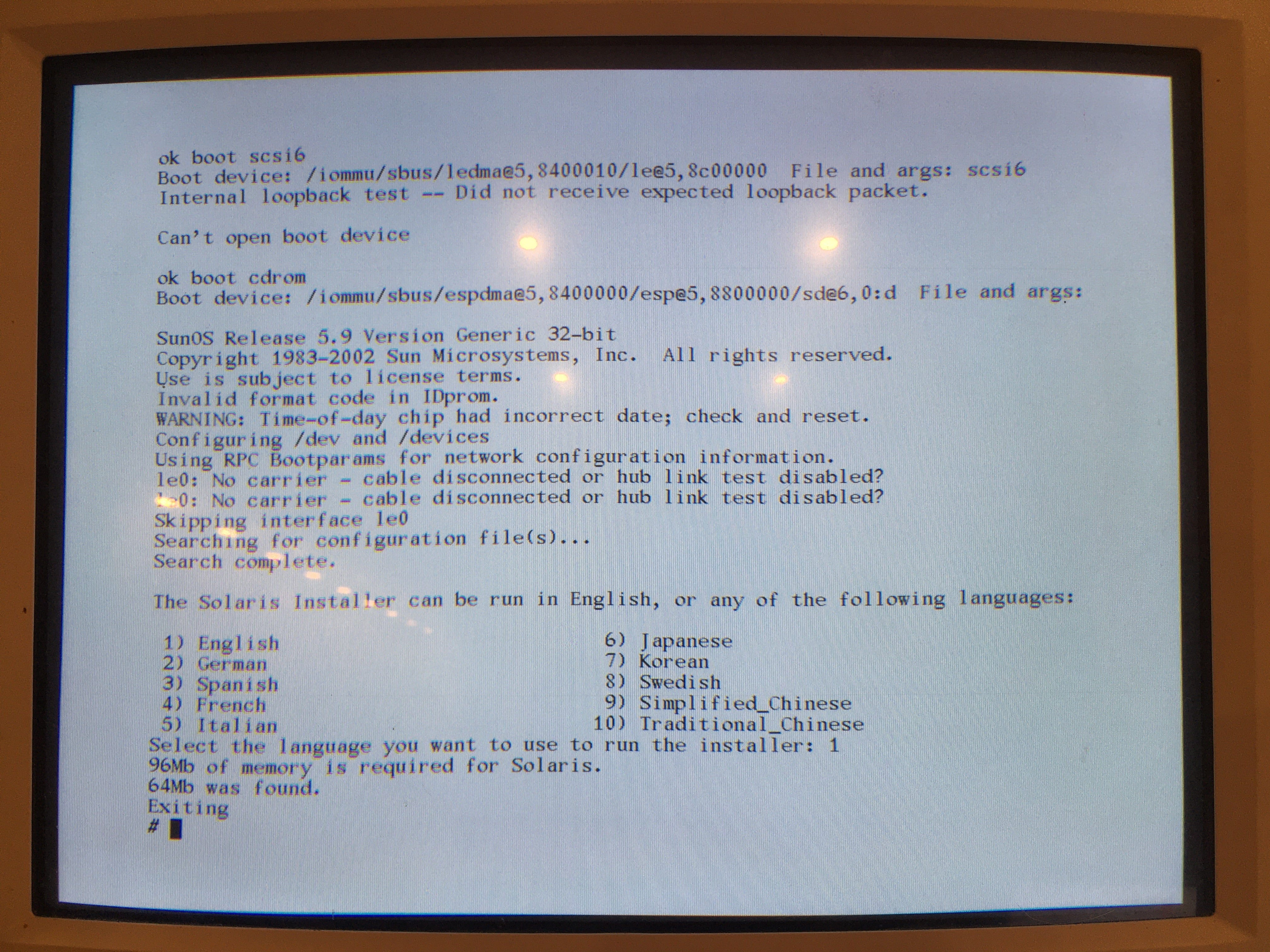
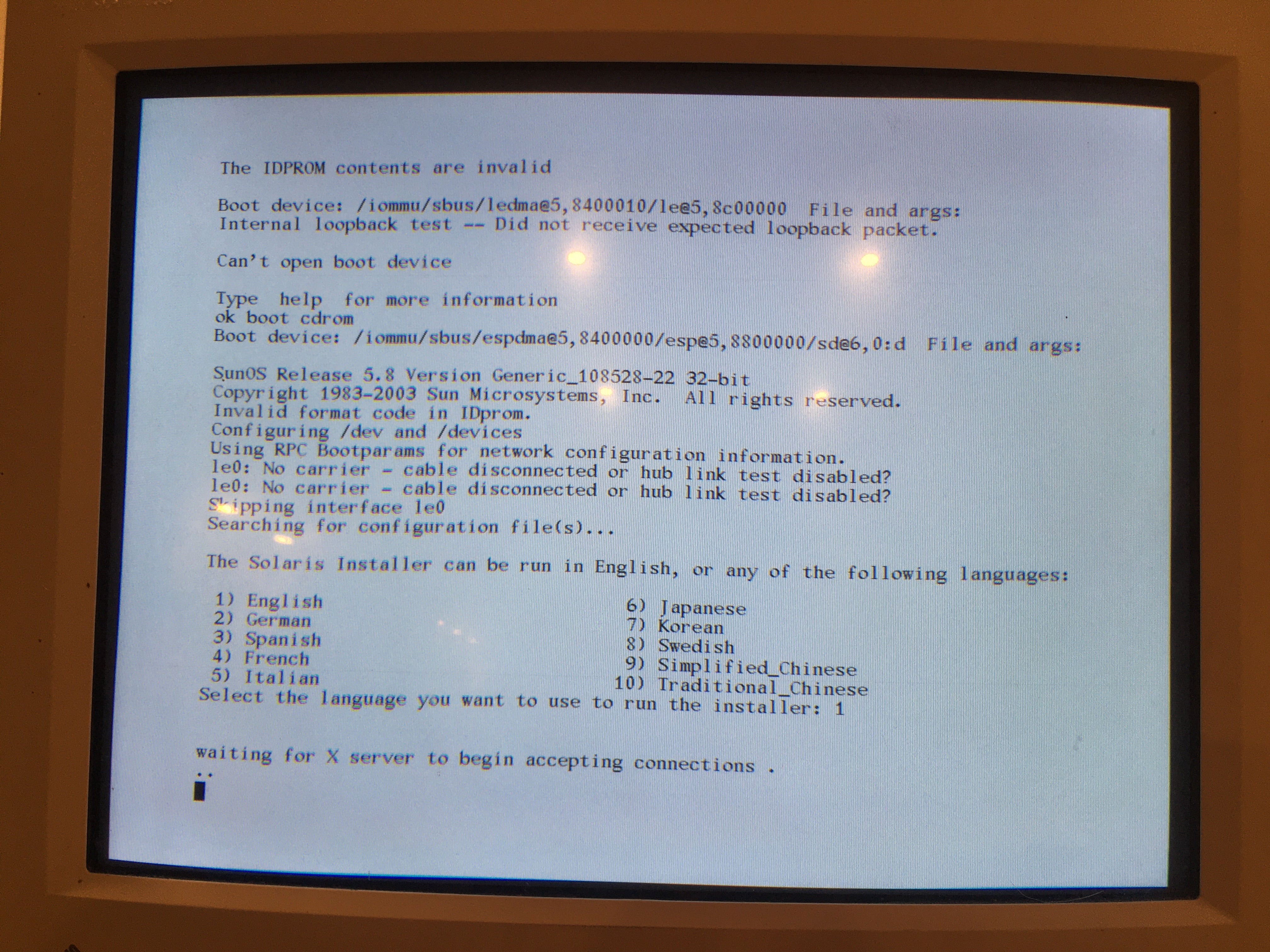
the installer for solaris 8 booted! but no matter what we tried, we couldn’t type in the console. the solaris docs say Alt+Tab can focus windows in cde, but that didn’t help here. i suspect we’re stuck until we can get mouse input working.

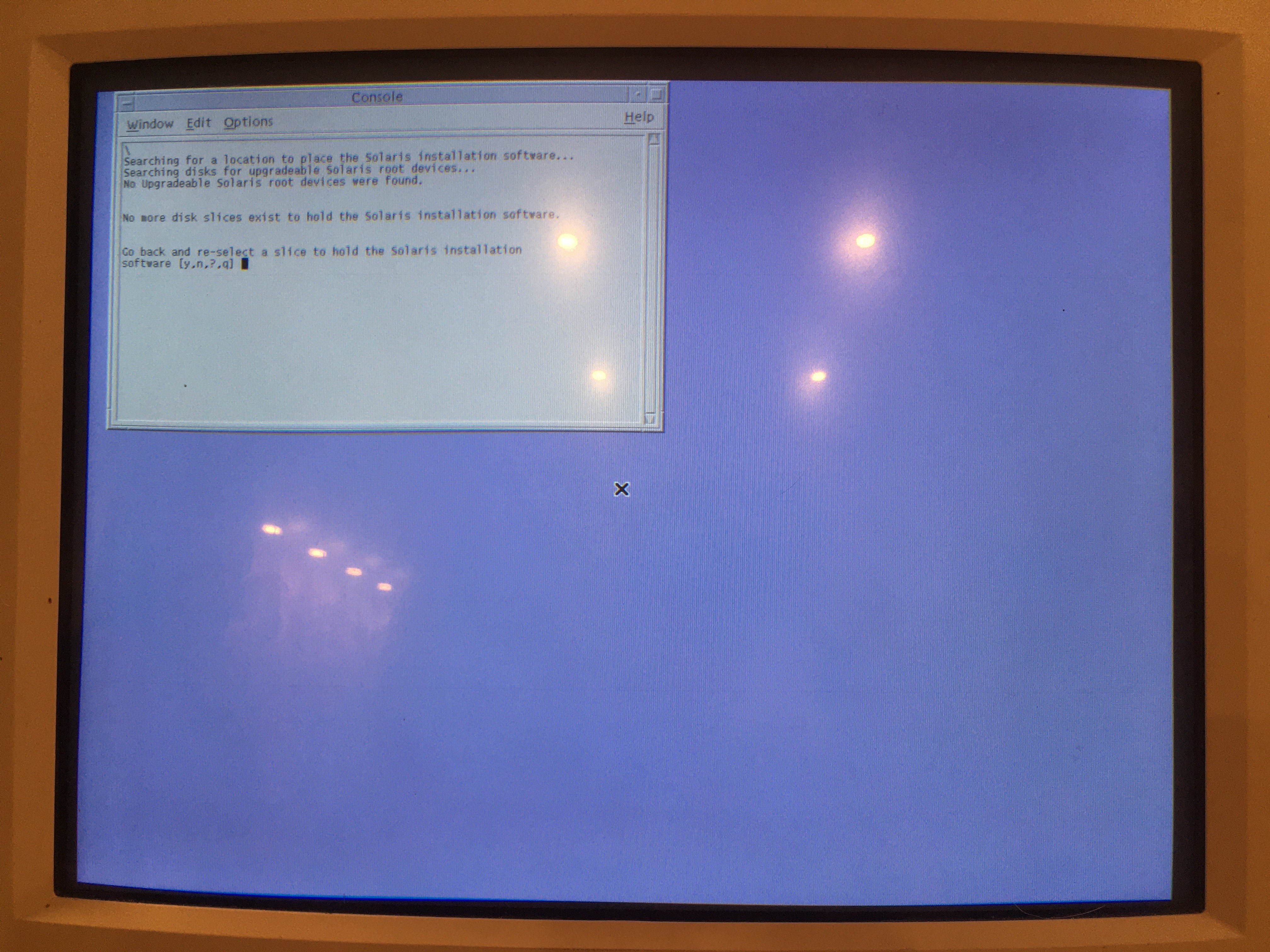
SPARCstations use a single 8-pin mini-din port for keyboard and mouse input. we have one keyboard (sun type 4) but no mouse, and sun mice (and keyboards) are rare and expensive, so wouldn’t it be great if we could somehow use a usb keyboard and mouse?
there are two ground pins, two 5V pins, keyboard rx, keyboard tx, and mouse tx. the data pins are all 5V serial at 1200 8N1 with negative logic, with the SPARC keyboard protocol and five-byte serial mouse protocol (aka Mouse Systems protocol).
unfortunately most sun input adapters are for using sun keyboards and mice with machines with usb or ps/2 ports, which is the exact opposite of what we want. this is wildly surprising to me in 2022, like where the fuck are people finding all these spare sun peripherals?
i had a couple of raspberry pi picos lying around, and i saw that it was possible to bang out low- or full-speed usb hosts over the gpio pins using the rp2040’s “pio” feature. the pico can also do serial, albeit at 3V3 only, so perhaps we can build around that!
code for the kind of adapter we want actually exists (USB2Sun), but due to my inability to use google effectively in the 2020s era, i kept getting results for the opposite kind of adapter before giving up in frustration and deciding to write my own. (the trick that worked, by the way, was googling “usb2sun”, by analogy with “sun2usb”.)
i dug up a pico and some usb ports from my bucket of front panel bits.


i hadn’t worked with microcontrollers before, or really done any electronics irl (this section happened before subamp), so i learned to solder for the very first time, then i spent a couple days messing around with various outputs like leds, a piezo buzzer, and a little i2c display.


i wired up an 8-pin mini-din cable, using a reversible plug that allowed both of the possible mirrored pin layouts, but despite checking and double checking it, i ended up wiring up the wrong layout. i was unable to remove enough of the solder from the side that was supposed to go into the port, so i had to buy a new plug and start over. (i later learned that this was because i had completely oxidised the soldering iron tip, by not keeping it coated in solder, and more importantly, leaving it switched on all weekend. sorry @ariashark.)


after messing around with platformio some more (including reporting a bug in the rp2040 core), i managed to get the usb host working! we can now read hid reports from a WMO and HP usb keyboard, but not a microsoft keyboard for some reason. maybe it has something to do with the usb composite device, or maybe it’s the same reasons that the keyboard is hid-microsoft on linux and not hid-generic, i’m not sure yet.
https://twitter.com/i/status/1591829743149920258
the remaining parts have since arrived, including the very important 5V/3V3 level shifter, so stay tuned!
a real implementation of one of the most bizarre meme formats I have ever seen
what?

reverse engineering is when you do a lot of hex to decimal and decimal to hex conversions. the more conversions you do, the more reverse the engineering is
reverse engineering is when you do a lot of byte swapping. the smaller the endian is, the more reverse the engineering is
nearly every time we talk about how DOCSIS modems, up until relatively recently, encapsulated PPPoE traffic in MPEG Transport Stream format, we have the pleasure of seeing someone go “wait, what?”
 thanks for using eggstrogen
(teggstrosterone coming soon)
thanks for using eggstrogen
(teggstrosterone coming soon)the existence of conjugated eggbug estrogens implies the existence of eggbug pregnancy and eggbug piss
https://www.twitch.tv/videos/1660733060
first time full combo! i always used to get really tense and fatigued, then the flow aim patterns would fuck me, but not this time!



have spent the last few days planning out and executing a sound upgrade to our car. everything was going fine up until we started and step 1 took literally 6 hours lmao
can't wait to have this finished!!! have some Progress Pics
(we stopped taking photos at about 4am when we were so tired and exhausted we just Forgot)
can't be bothered to strip all the EXIF just yet but we're almost there. everything is wired up, no fires, etc. but we're getting some very interesting readings from our multimeter. here's our notes so far
OEM Sub (at the driver)
| Hz | Voltage |
|---|---|
| 20 | .501 |
| 60 | .582 |
| 80 | .191 |
| 150 | .068 |
| 250 | .022 |
| 440 | .008 |
OEM Rear left speaker (at the driver)
| Hz | Voltage |
|---|---|
| 20 | .004 |
| 60 | .067 |
| 80 | .069 |
| 150 | .111 |
| 250 | .052 |
| 440 | .144 |
At the high level input on the amp, tapped from OEM Rear left speaker near the factory amp
| Hz | Voltage |
|---|---|
| 20 | .004 |
| 60 | .058 |
| 80 | .087 |
| 150 | .117 |
| 250 | .054 |
| 440 | .151 |
At 30/40 HU volume, playing a 50hz sine wave
V=P⋅R−−−−√
150W⋅4Ω−−−−−−−−√=24.494V
Target voltage out from amp should be 24.494V
On minimum gain(5V), the amp was outputting 0.6V. On highest gain(0.2V) it was 1.374V.
The high level inputs while playing 50hz sine wave on 30/40 HU volume was:
just got back from jaycar, and bought some of these

after taking yesterdays readings, we decided instead of sending our speaker tap into the sub's high level input, we would send it into the low level input. when the unit was at it's theoretical max volume before distortion, it was only sending 0.277V to the amp. that's well within the low level input range (of about 0-4V?) so we instead hooked it up to a couple rca cables and hey presto, it's not as quiet anymore!
at 30/40 HU volume, playing a 50hz sine wave and measuring the amp output with a multimeter, it was outputting 1.7V!!! which is already higher than yesterday when it was at it's most sensitive. we did the normal thing of slowly turning up the gain until it reached it's target voltage of ~24.49V
150W⋅4Ω−−−−−−−−√=24.494V
our amp goes from 5v all the way up to 0.2V, and we managed to hit the target output at around 0.35V sensitivity.
and that's it, project done! we need to tidy up the boot, tuck the cables away. put some trim back on in the cabin, and flex loom the power cable under the bonnet.
aside from that, an upgrade that needs to be done soon is replacing our flimsy ground connection that we (basically failed to) soldered to the terminal with a screw and square washer. unfortunately the ground's one was missing when we got the amp, but no worries. apparently they are just like M3 or M4 screws.
something to worry about another day! fuck yes! we have a sbamp! sbamp!
subamp! we installed a (bigger) sub and amp!
this counts as css crimes right? ^.^;;
https://www.youtube.com/watch?v=qWTHxQWUreo
live demo (chromium-based browsers only for now)
according to devtools
i’ve fixed it with a tedious combination of imagemagick, seventeen (17) chost drafts, and copying 66 resized image links by hand uphill both ways
it’s now under 15 MB, sorry @staff


yesterday we (+bkn) looked at some sun sparc machines for the first time!
i got these and a bunch of other non-x86 hardware from peter metz (classiccmp.de) in 2015.


before we started, we migrated our support machine from really old spinning rust to a cheap ssd. i had forgotten how unbearably slow windows is without one.

we needed the sun monitor for most of today’s machines, because they use the db13w3 connector, not vga like most of our monitors. opening it while the caps were still drained to check for leaky caps, it was hard to see through the metal inner cage, but it looked ok.



unfortunately, while we were reattaching the base, one of the springs came off the mounting disc that the base clipped into, allowing the disc to move freely even though it shouldn’t.


attempts to fix this through the existing opening were unsuccessful, and we ended up having to take the monitor a lot further apart.




with the base removed, we were able to reattach the spring to the disc, and move the disc back under the tracks it had fallen out of. to keep the disc under the tracks when removing the base, we need to keep the base at the angle where the spring rests naturally.


we noticed that the monitor was designed such that a bundle of wires ran close to a sharp metal edge, so to leave that better than we found it, we wrapped the edge in electrical tape. on the other hand, it was unclear how to safely remove and insert the screw covers in the top case, so i ended up breaking both of them to some extent, one of which required a small amount of double-sided tape to stay attached.


the SPARCstation IPC is the oldest design of the three, and it’s like a lunchbox version of the SPARCstation 1+ pizzabox. it’s a sun4c machine, a direct descendant of the sun4 platform in which sun debuted sparc. the connectors are unfamiliar coming from the pc world, with two db13w3 ports for monitors and an 8-pin mini-din for the keyboard and mouse. notably there’s an aui port for networking, which is the 10-megabit-era counterpart to sfp. the idea behind things like aui and sfp is that you can choose your physical layer medium by providing your own transceiver, which converts the generic port to twisted pair (rj45) or coaxial or fibre optic.



internally they use sbus to connect to expansion cards, not pci or isa like their pc contemporaries. sparcstations also rely on battery-backed nvram to configure the firmware when booting, but annoyingly, many of them use a part for this where the battery and memory are integrated into an enclosed package, expecting you to replace the whole when the battery dies, but more on that in another chost.




the first IPC appeared to be in pretty bad shape, with part of its power supply enclosure being suspiciously rusty.



the cause became more apparent when we disassembled the power supply, revealing that several electrolytic caps were actively leaking, and the traces on the pcb were degraded.





nathaniel taught me how to use a desoldering gun, and together we removed the leaky caps, then (somewhat) cleaned and neutralised the board with ipa. heating the solder near the leaks created an unpleasant fishy smell. eventually we will decide whether to print a new pcb and repair the power supply in its original design, or replace it with something completely new like a picopsu.


the second IPC has what looks like a UWA asset tag carved into it.


unfortunately, it also showed signs of leaking electolytic caps, so we decided not to proceed until we’re able to repair it. and while we reassembled it, the button that releases the right side of the case snapped off the underlying metal leaf. abs is incredibly fragile!


we have not yet looked into dumping the hard drives in either IPC.
the SPARCstation 5 is a pizzabox that runs on the sun4m platform, which is the successor to sun4c and so named because it replaces sbus with the multiprocessing-capable mbus. that said, the SPARCstation 5 itself is still a uniprocessor system with sbus.


the removable storage is interesting, with a cd drive whose tray occupies its entire face, like a laptop drive but thicker, and a floppy drive that’s been modified for software eject, like many macintosh computers.



like the SPARCstation IPC, the top of the case in the SPARCstation 5 opens as if there’s a hinge along the front edge, but unlike the IPC, the top case achieves this with three long fragile tabs. i learned this the hard way, breaking two of the tabs in one of the machines.
in the SPARCstation 5, the top case also wraps the front face of the machine, so with only one tab holding the front of the case closed, we must now be especially careful not to lift the front of the machine by the face. we must hold the bottom of the machine, starting from the back edge if the bottom is unreachable due to the surface underneath.


the first SS5 passed a visual inspection internally, and was labelled “borealis”. its cpu came in a beautiful purple ceramic package and hard-drive-platter-shaped heat sink.


unfortunately, when we tried booting the machine, a tantalum cap near the power supply edge of the mainboard failed, sending a couple of sparks flying and leaving a smell of magic smoke behind. we’ll need to replace the cap, and it would probably be a good idea to test the power supply separately before attempting to boot again.

the second SS5 passed a visual inspection internally, and has a different expansion card installed, allowing the use of a second monitor (if we had one).



the machine starts! but we weren’t able to boot anything installed on it, and when we booted a solaris 9 install cd, we noticed we were only able to read from one of its two hard drives. in both cases, it might have been due to our unfamiliarity with openboot and solaris.
we were also able to boot a debian 3 install cd, and there we were able to mount ufs on both disks (one for /, one for /usr/). the newest mtime in the root was march 2004, and we saw a reference to “news.uwa.edu.au” there too.
we tried to dump the disks in situ, but debian 3 didn’t appear to have a driver for the nic. we also found that we lacked the necessary hardware to connect the disks to another machine, because the disks in both machines use sca (80-pin), whereas our pci scsi hba cards only had 50-pin (0.1″ header) and 68-pin (internal D shell) internal connectors, and we only had 68-pin (idc with internal D shell) cables.
the cable connecting the backplane to the mainboard was interesting too. it has a 50-pin (0.1″ header) connector for the cd drive, as well as a 50-pin connector i’m unable to find any references to, but has similar density to 68-pin (internal D shell).


the Sun Ultra 5 is a much newer pizzabox built around the 64-bit ultrasparc architecture, unlike the 32-bit architecture of the sparcstations. early models in the ultra series used sbus, but later ones switched to pci, and some of those later models even replaced scsi with ide. the Ultra 5 was the first such model.



our Ultra 5 passed a visual inspection internally, and was labelled “andromeda”. the machine started, but complained about corrupt nvram, so the battery is probably dead. that said, we were able to continue booting the installed solaris 2.6 (sunos 5.6) with “ok boot disk”.
pushing the front power button broke out of X and solaris, returning us to openboot.

we dumped the drive with the guts of a usb to ide enclosure connected to a linux machine, and were able to mount ufs on that machine too. we had a nicer looking usb to ide cable, but only found it afterwards.

i like collecting and tinkering with funny computers. here are the adventures i’ve written about on twitter:
when i was like 10 to 15, mum used to drive me around looking for old computers in verge collections [1], where i used to be able to find machines that were more like the ones i had when i was even younger (pentium 1 era). i have installed windows 98 so many times that i can type my product key from muscle memory in eight seconds.
over time, the kinds of computers people threw out moved on to pentium 4 and core 2 era machines, which dominated verge collections in the 2010s. my parents asked me to strip the machines i had collected with mum for parts to save space, so eventually these were all i had. nowadays i know the lga775 platforms inside out, and i’m sick to death of them. they feel like a “solved problem”, everything more or less just works, and you can generally boot cds and flash drives without floppy emulation.
i feel like people threw out way more of their old home computers back then. i’m not sure why, maybe retrocomputing wasn’t the lucrative market™ it is now so the computers weren’t worth anything, maybe people in general were better off back then and didn’t feel the need to sell, maybe desktop computing was evolving a lot faster and not the “solved problem” to the extent it is now, maybe people were less privacy-conscious and worried they needed to destroy their “hard drives” (pars pro toto) lest their bank details got in the wrong hands.
going to university gave me a chance to revive my hobby, because i got to meet other people who had interesting hardware, and this is how i found almost all of the funny computers and unique parts i have now. some notable examples include pOpArOb who gave me my first pentium 2/3 hardware, mike aldred who had a real job™ where they could throw out a bunch of agp video cards in roughly my direction, and peter metz who gave me my first non-x86 machines before they moved to germany.
but in 2017, i graduated and moved to sydney, and i had to leave all of my funny computers in a storage unit, in most cases before i ever had time to play with them. when i moved back to perth in 2021, i had a lot of catching up to do. i’ve had to buy a bunch of tools and equipment that i previously mooched off my parents. i didn’t even have a cd burner for my first month!
i had also forgotten a lot of what i knew about old pc hardware (which probably wasn’t that good anyway), so i’ve been learning a lot along the way. one embarrassing example of this is misremembering which way my debug card plugged into the isa slot and blowing a trace. i started reading mueller’s upgrading and repairing pcs the other day, which seems like it will teach me a lot about at troubleshooting and compatibility.
stay tuned for more funny computer adventures in #funny computer!
So I stumbled a few weeks ago on this video about the world's smallest conlang and I've been thinking about it ever since.

(You will probably have the idea more than fully by the ten minute mark.)
This fascinated me. I think languages are really interesting but I'm also really bad at them. I cannot hack the memorization. I've mostly avoided conlangs (that's Constructed Languages, like Esperanto or Klingon) because like, oh no, now there's even more languages for me to fail at memorizing. So like, a language so minimal you can almost learn it by accident, suddenly my ears perk up.
Toki pona is really interesting, on a lot of different axes. It's a thought experiment in Taoist philosophy that turns out to be actually, practically useful. It's Esperanto But It Might Actually Work This Time¹. It has NLP implications— it's a human language which feels natural to speak yet has such a deeply logical structure it seems nearly custom-designed for simple computer programs to read and write it². Beyond all this it's simply beautiful as an intellectual object— nearly every decision it makes feels deeply right. It solves a seemingly insoluble problem³ and does it with a sense of effortlessness and an implied "LOL" at every step.
So what toki pona is. Toki pona is a language designed around the idea of being as simple as it is possible for a language to be. It has 120 words in its original form (now, at the twenty year mark, up to 123), but you can form a lot of interesting sentences with only around twenty or thirty (I know this because this is roughly the size of my current tok vocabulary). The whole tok->en dictionary fits on seventeen printed pages⁴. There are no conjugations or tenses to memorize. There are no parts of speech, generally: almost every single word can be used as almost any part of speech, drop a pronoun or a preposition⁵ in the right place and it becomes a verb, drop a verb in the right place and it becomes an adjective. There are almost no ambiguities in sentence structure; I've only found one significant one so far (using "of" [pi] twice in the same clause) and the community deals with this by just agreeing not to do that. There's in one sense quite a lot of ambiguity in the vocabulary but in another sense there's none; for example nena is listed in the dictionary as meaning hill, mountain, button, bump, nose, but the official ideology of Toki Pona is that this is not a word with five definitions, it is a word with exactly one definition, that being the concept encompassing all five of hills, mountains, buttons, bumps, and noses. Toki pona words are not ambiguous, they're just broad. I will now teach you enough toki pona to understand most sentences (assuming you consult the dictionary as you go) in a paragraph shorter than this one:
Every sentence has an "verb" or action clause. Most sentences also have a subject clause, which goes before the verb separated by "li". Some sentences also have an "object" or target clause, which goes after the verb clause separated by "e". So "[subject] li [verb] e [object]". All three clauses are any number of words, the first word is the noun (or verb) and the rest are adjectives (or adverbs). If the first word in a sentence is mi or sina you can omit the li in that case only. There is no "is", a sentence like "a flower is red" is just "[a plant] li [red]" because there are no parts of speech and adjectives are verbs. Pronounce everything the way you would in English except "j" sounds like "y". If you see "tawa", "lon", "tan" or "kepeken" in adjective/adverb position that's a preposition, so treat whatever comes after it as a fourth clause. "a" and "n" are interjections and can go anywhere in a sentence. If you see "o", "pi", "la", "taso, "anu" or "en", then you've found one of the few special words (particles) and you should probably either read the book or watch the jan Misali instructional videos on YouTube.
That's like… almost it!⁶ Watch one youtube video, or read a half page of grammar summary and keep the dictionary open on your phone, and you're basically ready to jump into conversations. (You'll need those last six particles to make nuanced sentences, but sentences do not have to be nuanced.) In my own case I watched the Langfocus video linked at the top and then lazily over the next week watched the jan Misali overview and two of their instructional videos then read a few chapters of the book, and was already able to construct a full paragraph and be understood by another person:
o! mi sona e toki pona. mi lukin sona e toki mute... taso mi toki ike e toki ale. toki mute li jo e nimi mute. nimi mute li pona ala tawa mi. toki pona li pona e mi tan ni. toki pona li jo nimi lili. nimi lili li pona e me :)
(Translation: Hello! I am learning toki pona. I've tried to learn many languages… but I speak all of the[m] badly. Most languages have a lot of words. Lots of words is not good for me. Toki pona is good for me because of this. Toki pona has few words. Few words is good for me :)⁷)
So that's week one. By the end of week three (that'll be this past Sunday) I had hit three milestones:
(That last one actually kind of excited me when I realized, after the fact, that it had been happening for several days before I noticed it.)
All of the above happened on the toki pona Discord, which seems to be the largest and healthiest outpost of toki pona community online⁸ and, I assume therefore, the world. Here's my toki pona joke; you'll notice that I begin by preemptively apologizing for it, but by the end it becomes clear I was, at that moment anyway, apparently completely on the Discord's level:⁹
¹ Esperanto was meant to be an auxillary language simple enough the entire world could learn it as a second language. But it does not seem to me to be actually all that simple to learn (the verb tenses may be free of exceptions, but there are still like six of them) and it seems hard to convince myself to study it when I could put that effort toward a more widespread language. Toki Pona on the other hand is a language simple enough the entire world actually could learn it, had it reason to, and the buy-in cost in time is a lot lower. Meanwhile Toki Pona just seems to get certain international-accessibility things right, probably due to the advantage of having over a century of conlang practice largely inspired by Esperanto to draw from. The difference that's most interesting to me, but which I'm also least qualified to evaluate, is that the Toki Pona author had some basic familiarity with, and gave Toki Pona input from, east Asian languages. Both Toki Pona and Esperanto draw roots from a variety of languages but in Esperanto's case this winds up being mostly European languages, mostly Italian, whereas Toki Pona has Mandarin and Cantonese in its mix. Both languages were intended to have a minimal, universal phonology but Esperanto's is not very universal at all and has some consonant sounds that are going to be be totally unfamiliar unless you speak Polish or a language related to Polish. Toki Pona's phonology is actually minimal-- it has the letters in the sentence "mi jan pi ko suwi lete" and nothing else and the legal syllabary is basically hiragana without the combination syllables. Now, what I don't know is whether any of this actually helps speakers of Asian languages in practice or if it just makes surface choices that make it seem that way to a westerner like me. In practice if you find a toki pona speaker their native language is almost certainly English, so there doesn't seem to have been a great deal of testing as to how learnable it is to people from varied regions.
² I kept imagining toki pona as being like LLVM IR for human languages or something.
³ Designing an actually learnable, universal(?) international auxillary language.
⁴ By which I mean if you print the unofficial web version it's 17 pages long. But you can fit it in sixteen if you remove the web-specific introductory paragraph, the "joke word" kijetesantakalu, and the web footer with the "trans rights now!" banner in it.
⁵ There's an awkward nuance in the specific case of prepositions: if you drop a preposition into verb position it still winds up "behaving like" a preposition, it's just that the preposition describes an action. It's probably more accurate to say that the preposition phrase becomes a verb rather than the preposition itself. So for example "mi tawa kalama" means "I went toward the sound" [kamala is a noun and the object of the preposition] not "I went loudly" [as it would be if kamala were an adverb modifying tawa as a verb]. Going into detail on this because I don't want to mislead anyone but "you can form a sentence using an unmodified preposition as a verb" is such a fun fact I wanted to include it.
⁶ I guess I could say "what I'm calling 'clauses' are called 'word groups' in official sources; word groups are always separated by a particle or preposition" but I'm not sure that's interesting unless you're a linguist.
⁷ There's a lot of repetition in this paragraph of both kinds that show what's cool about toki pona and what's kinda impractical about it. Cool, it has some sentences where a single word shows up twice conveying two different clear things based only on where it is in the sentence, like "mi toki ike e toki ale" where toki is a verb ("I speak") the first time and a noun ("language") the second. Less cool, because so much of the meaning of the hyper-versatile toki pona words is based on context, you sometimes wind up having to include multiple sentences saying nearly the same thing just to make sure the reader selects the correct context. I may have overdone it here.
⁸ There's also a low-traffic Mastodon instance, multiple forums including one run by the Merveilles crowd, and something called "Wikipesija"
⁹ Translation/explanation:
on linux and freebsd, with reptyr <pid>
while we’re here, did you know that pv(1) can give you progress meters for files opened by any process, even if you forgot to pipe the program through pv? only on linux though, with pv -d <pid[:fd]>


ill start these are mine
also if you say one of them is more like blue then you lose all of your points and also a bee will fly out of your mouth
I'm a big fan of the more red purples (perhaps they are truly dark pinks?). a certain kind of muted lavender also really fucks.
ooh i already posted my favorite purples a couple months ago so i have my answers ready In css even! it rly is all about the muted lavender and rich wine
"Purples"
#e0b9e0
#d17fcc
#5e1051
#3b1942
#29182e
#1a131a
I know nothing about color
oops this was a disaster on mobile, fixed now
cohost only supports inline styles, hence the need for tooling like prechoster, but code reuse is still possible thanks to the ‘all’ and ‘display’ properties. this can make hand-writing chosts easier, and it could potentially even help reduce the size of generated chosts? here’s how:
<div style="/* common */; display: contents;">/* common */ in that wrapper elementall: inherit; display: /* something */; to each of their stylesthese wrappers can be nested, though for inner wrappers you can use <div style="all: inherit; /* common */"> to save a few characters. for example:
<div style="position: relative; height: 8em;">
<div style="width: 2em; height: 2em; position: absolute; justify-content: center; color: #fff9f2; background: #83254f; display: contents;">
<div style="all: inherit; display: flex; inset: 1em 0 0 1em;">e</div>
<div style="all: inherit; display: flex; inset: 3em 0 0 3em;">g</div>
<div style="all: inherit; display: flex; inset: 5em 0 0 5em;">g</div>
<div style="all: inherit; background: #e56b6f;">
<div style="all: inherit; display: flex; inset: 1em 0 0 4em;">b</div>
<div style="all: inherit; display: flex; inset: 3em 0 0 6em;">u</div>
<div style="all: inherit; display: flex; inset: 5em 0 0 8em;">g</div>
</div>
</div>
</div>
(see also: github testing that i did for my profile readme)
data:image/svg+xml,<?xml version="1.0" encoding="UTF-8"?><svg width="99" height="99" viewBox="0 0 1 1" xmlns="http://www.w3.org/2000/svg"><rect x="0" y="0" width="1" height="1" fill="green"/></svg>supported
all: inherit;)stripped (into its textContent if any)
ooo( nice )
test if single newline yields <br>: foo bar


![“The risk of painful injections can be
minimised by: […]
“• Penetrating the skin quickly with the needle.”](/posts/attachments/imported-21-e174207b9a597a7f97075b0ea739d0abf7a5d3e87188ad10b639188f11e848c6/file.png)
![“Leakage can be minimised by: […]
“Counting ten seconds after the
plunger is fully depressed before
removing the needle from the skin
allows enough time for the injected
medicine to spread out through the
tissue plains resulting in tissue
expansion and stretch — […]
“Pressure should be maintained on the
thumb button of the pen device until
it is withdrawn from the skin to
prevent aspiration of subcutaneous
tissue into the cartridge.”](/posts/attachments/imported-21-213cb6ae6b6c164433fd99446d394c4f70779de92c5d6d541dedb72449cbf226/file.png)


































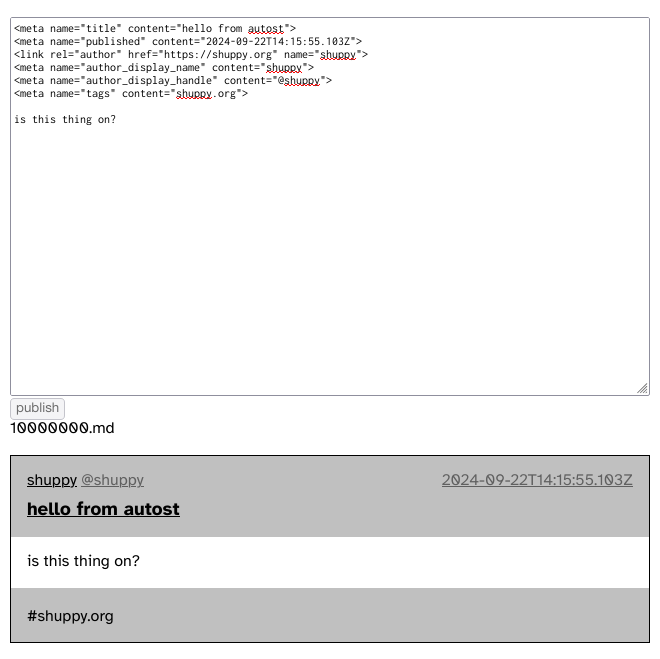


























































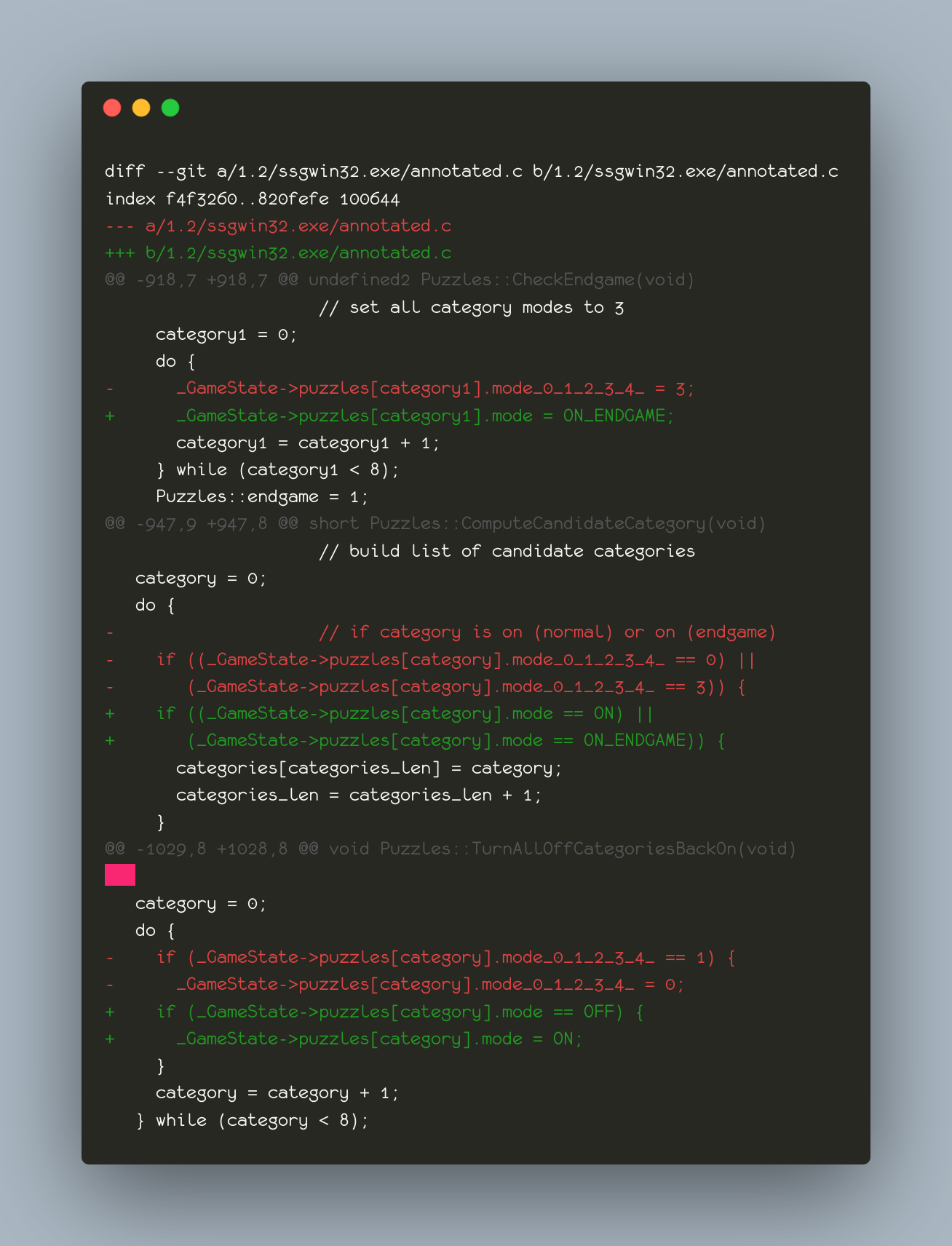
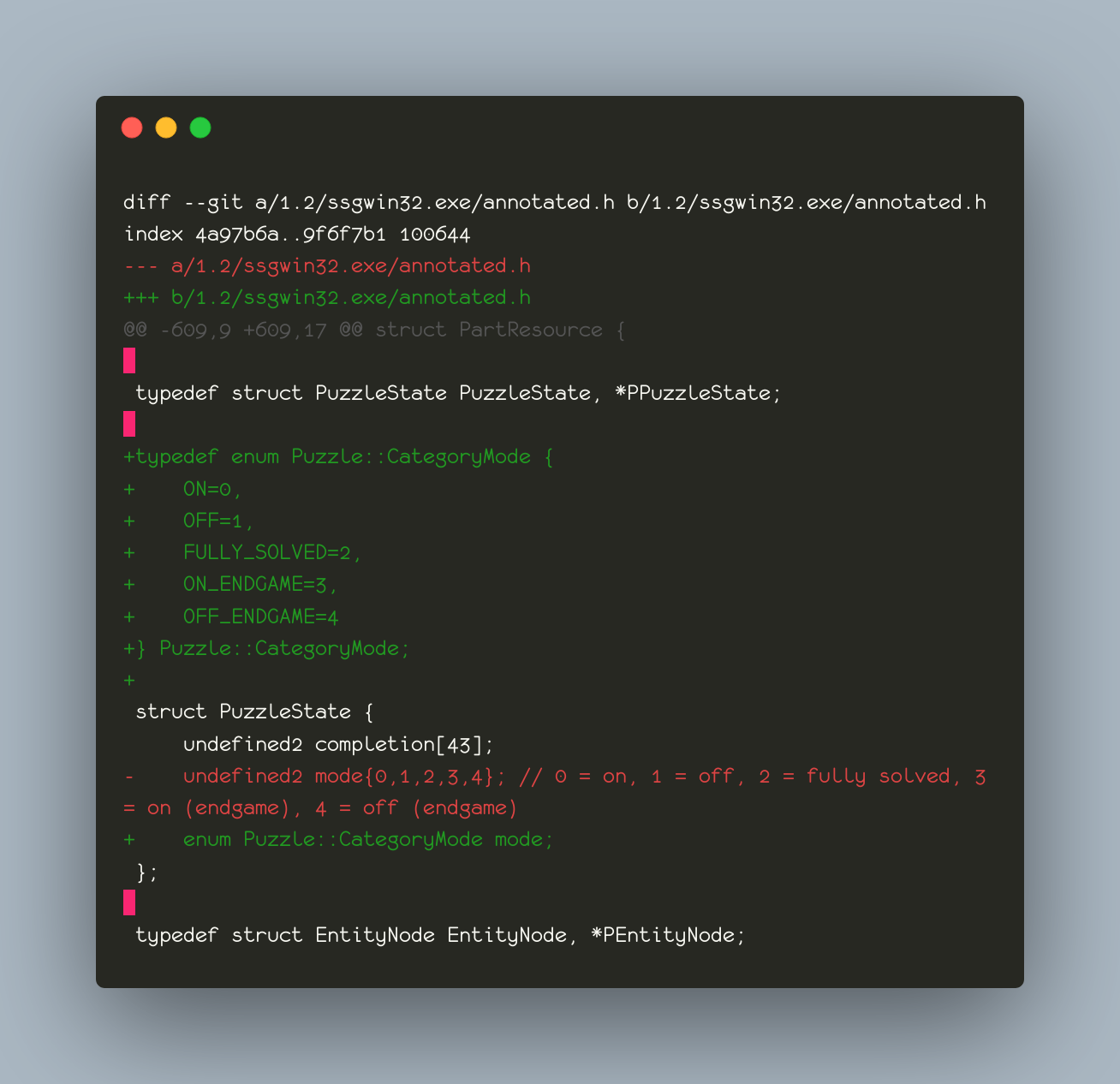


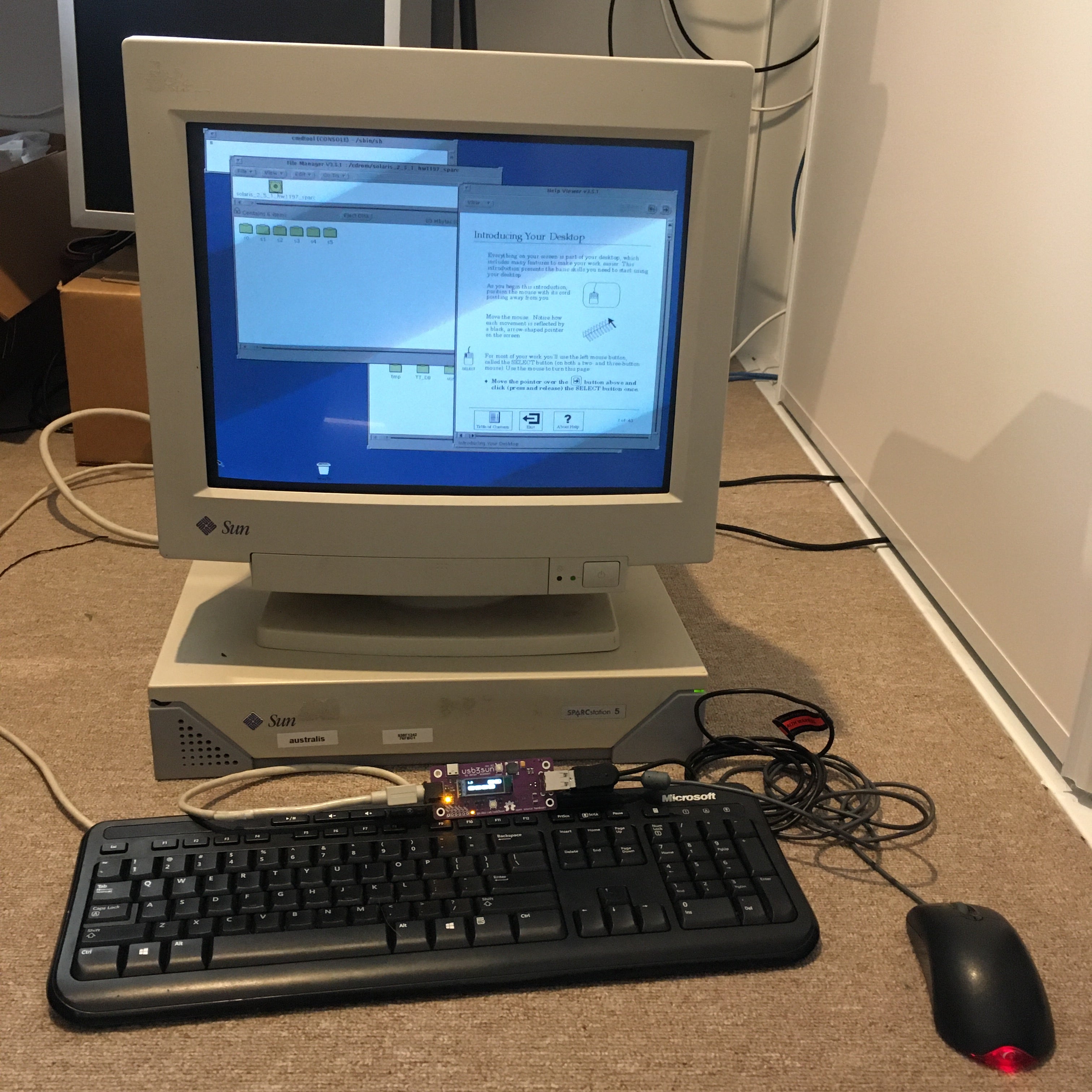





![Robert O'Callahan (:roc), 21 years ago: “This is not an [sic] theoretical question, by the way. Some people where I work have IBM T221 displays, which are 200dpi. […]”](/posts/attachments/72162d3d-dac0-4408-9dc7-d9fd75d53a50/Untitled5063.png)
![IBM T220/T221 LCD monitors — The IBM T220 and T221 are LCD monitors that were sold between 2001 and 2005, with a native resolution of 3840×2400 pixels (WQUXGA) on a screen with a diagonal of 22.2 inches (564 mm). […] Costing around $8,400 in 2003, the displays saw few buyers. […] IBM T220 (9503-DG0) — The IBM T220 was introduced in June 2001 and was the first monitor to natively support a resolution of 3840×2400. […] On the rear of the display are two LFH-60 connectors. A pair of cables supplied with the monitor attaches to the connectors and splits into two single-link DVI connectors each, for a total of four DVI channels. […] IBM T220 came with a Matrox G200 MMS PCI-32 video card and two power supplies. To achieve native resolution the screen is sectioned into four columns of 960×2400 pixels or four tiles of 1920x1200 pixels. The monitor's native refresh rate is 41 Hz.](/posts/attachments/acfd685a-661a-4c86-ab77-ece1fbe362a2/Untitled5064.png)
![IBM T221 — This is a revised model of the original T220. […] Single, double, and quad-link support 13, 25, 41 Hz refresh rates, respectively. […] The 9503-DG5/DGP/DGM model had a native refresh rate of 48 Hz and did not come with a graphics card but included an external converter box that receives a dual-link DVI signal, re-synchronizes, buffers, and splits it into two single-link signals - one carrying odd pixels plus sync, and the other even pixels plus sync. […] Using just one dual-link DVI interface through a converter box allows a refresh rate of 24 Hz or 25 Hz. When the converter box is used in parallel with a third single-link DVI input, a refresh rate of 48 Hz can be achieved. In this mode the dual-link DVI drives the left 2624×2400 portion of the screen and the single-link DVI drives the remaining 1216×2400 portion. Alternatively, two converter boxes can be used simultaneously with two dual-link DVI ports to drive the DG5 as two 1920×2400 stripes at 48 Hz. […]](/posts/attachments/e4f6087d-53f0-419e-ac6f-fdedf280590f/Untitled5065.png)


















{kind=link}
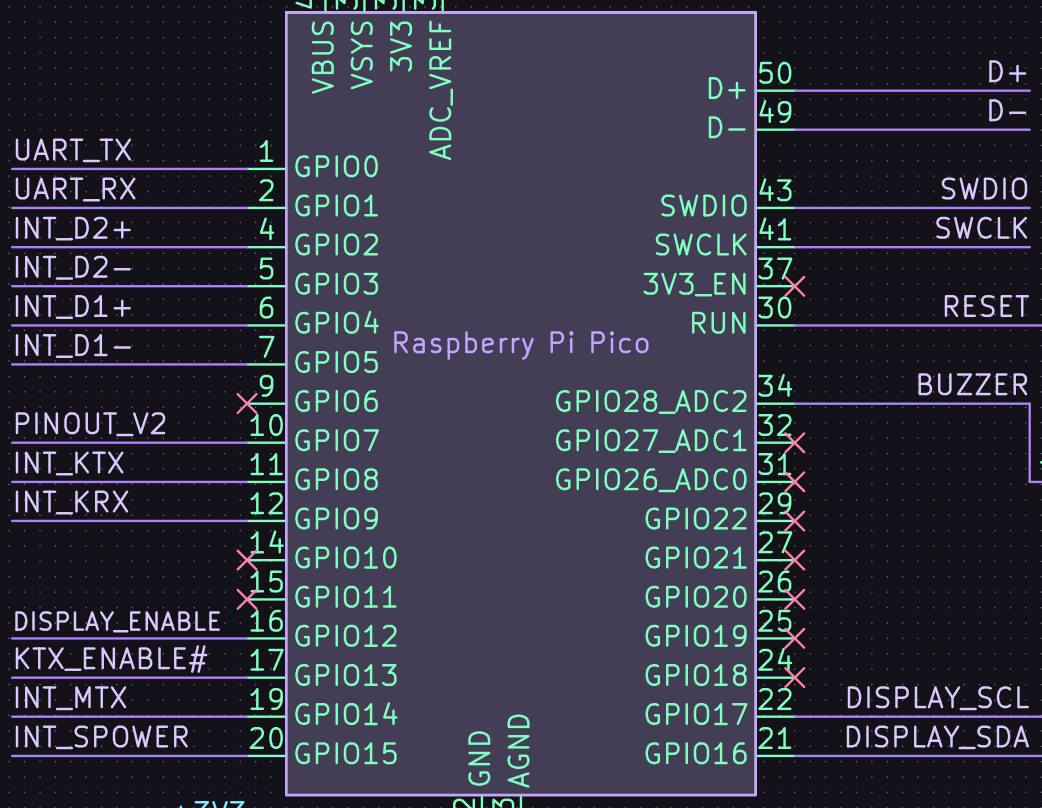{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}