zfs 2.3.1 + feature@device_removal + feature@block_cloning = sadness
tl;dr
there was a bug in zfs 2.2.0 through 2.2.7, and zfs 2.3.0 through 2.3.1, that can cause data corruption if you use both zpool remove and block cloning (anything that calls ioctl(FICLONE) or copy_file_range(2), including cp --reflink=auto). for more details, see zfs#17180, or these two links.
update to zfs 2.2.8+ or 2.3.2+ as soon as possible. if you are still running an affected zfs version, and you have a pool where feature@device_removal and feature@block_cloning are both active (not just enabled), stop writing to the pool and back up your data now, because the pool may get damaged by further writes.
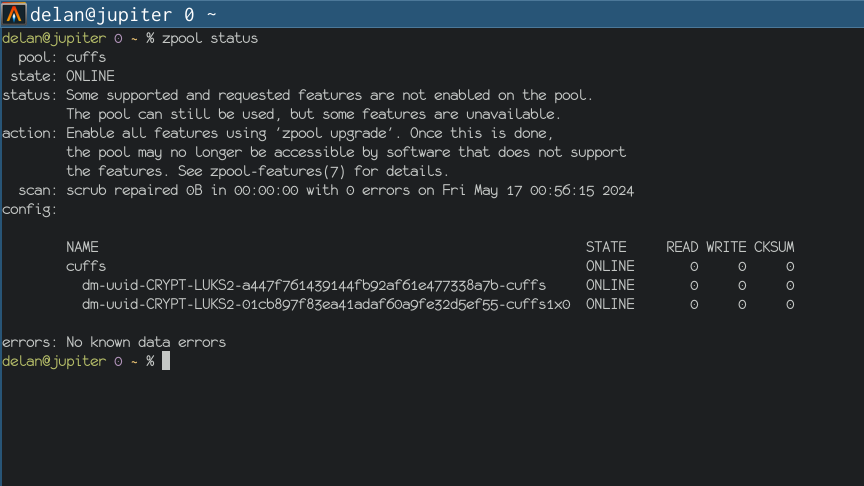
$ zpool get feature@device_removal,feature@block_cloning
NAME PROPERTY VALUE SOURCE
ocean feature@device_removal active local
ocean feature@block_cloning active local
i was affected
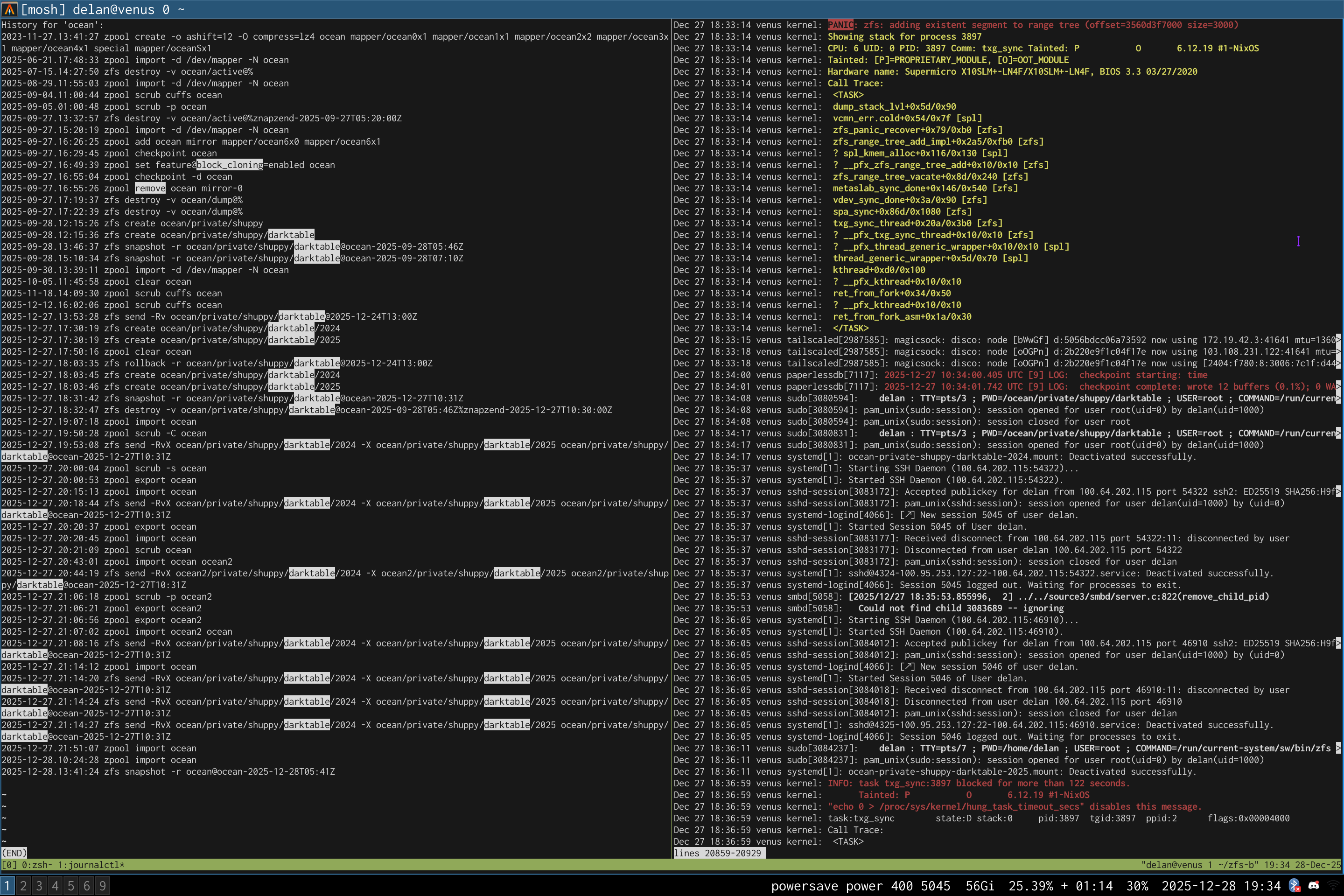
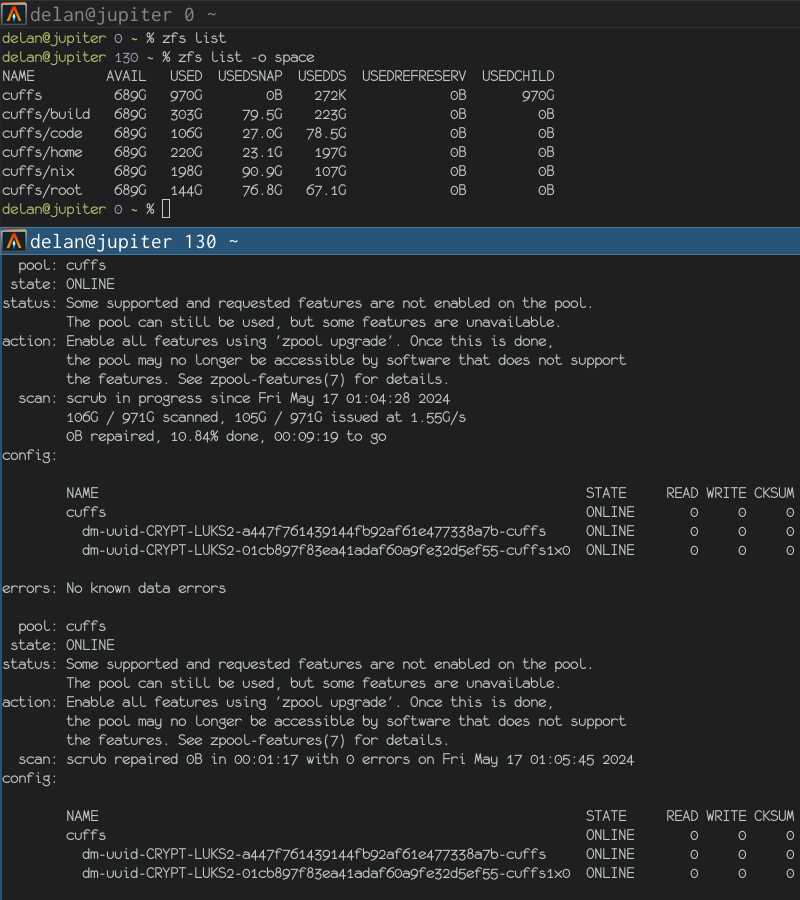
left: zpool history ocean, filtered to the interesting parts.
right: the first PANIC, and the first sign of data corruption.
timeline is as follows:
- 2024-12-21: updated from zfs 2.2.4 to 2.2.7 (zfs#15646)
- 2025-01-04: updated to NixOS 25.05, still on zfs 2.2.7
- 2025-02-19: updated from zfs 2.2.7 to 2.3.0 (probably)
- 2025-03-23: updated from zfs 2.3.0 to 2.3.1 (probably)
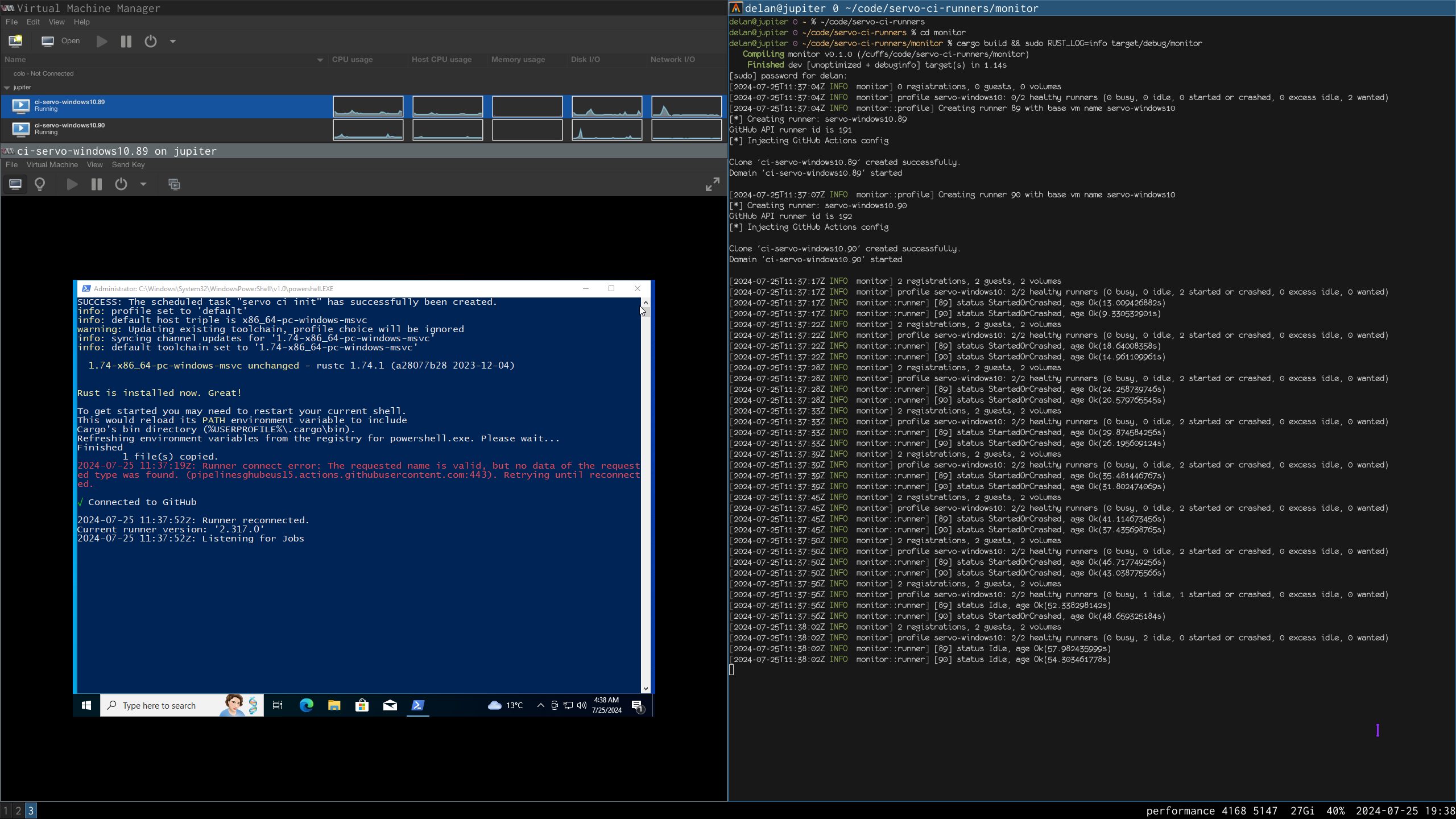
- 2025-09-27:
zpool set feature@block_cloning=enabled ocean - 2025-09-27:
zpool remove ocean mirror-0(mirror ocean0x0 ocean0x1) - 2025-09-27: used block cloning to copy my darktable photo library from
ocean/private(/delan)toocean/private/shuppy/darktable - 2025-12-27: used block cloning to copy most of that data from
ocean/private/shuppy/darktabletoocean/private/shuppy/darktable/2024and.../2025 - 2025-12-27: deleted that data from
ocean/private/shuppy/darktable - 2025-12-27 18:31:42: took a new snapshot of that dataset
- 2025-12-27 18:32:47: deleted all of the older snapshots
- 2025-12-27 18:33:14:
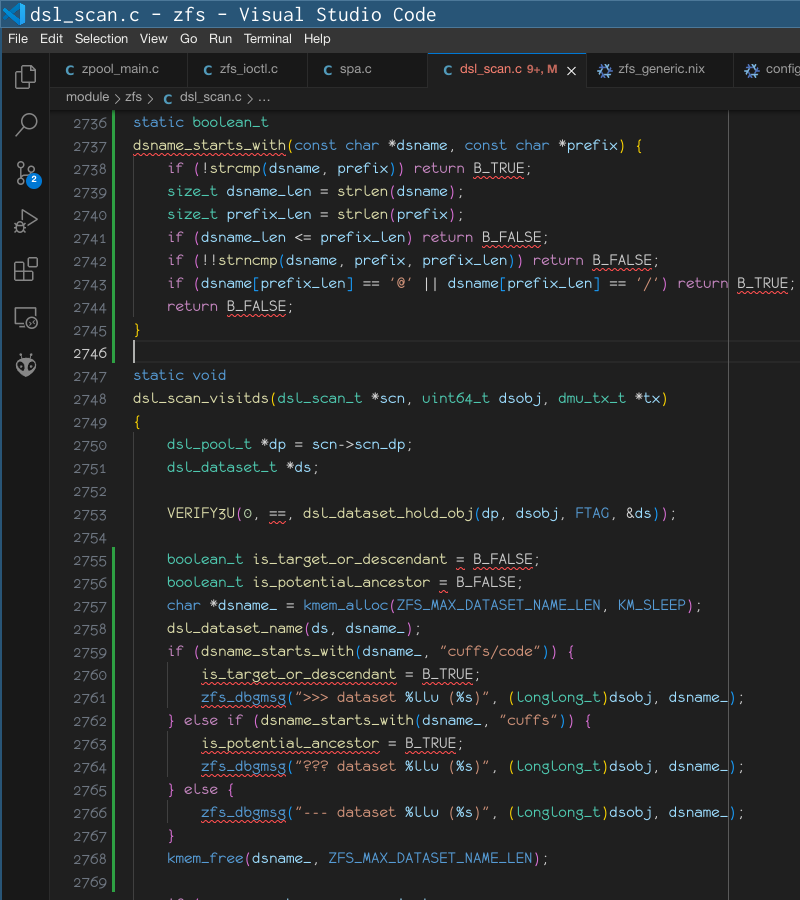
PANIC: zfs: adding existent segment to range tree (offset=3560d3f7000 size=3000)
i have since had consistent checksum errors when trying to send datasets out of this pool, so this is not theoretical.
and i can reproduce it
on a test pool, albeit only on a machine that still runs zfs 2.3.1:
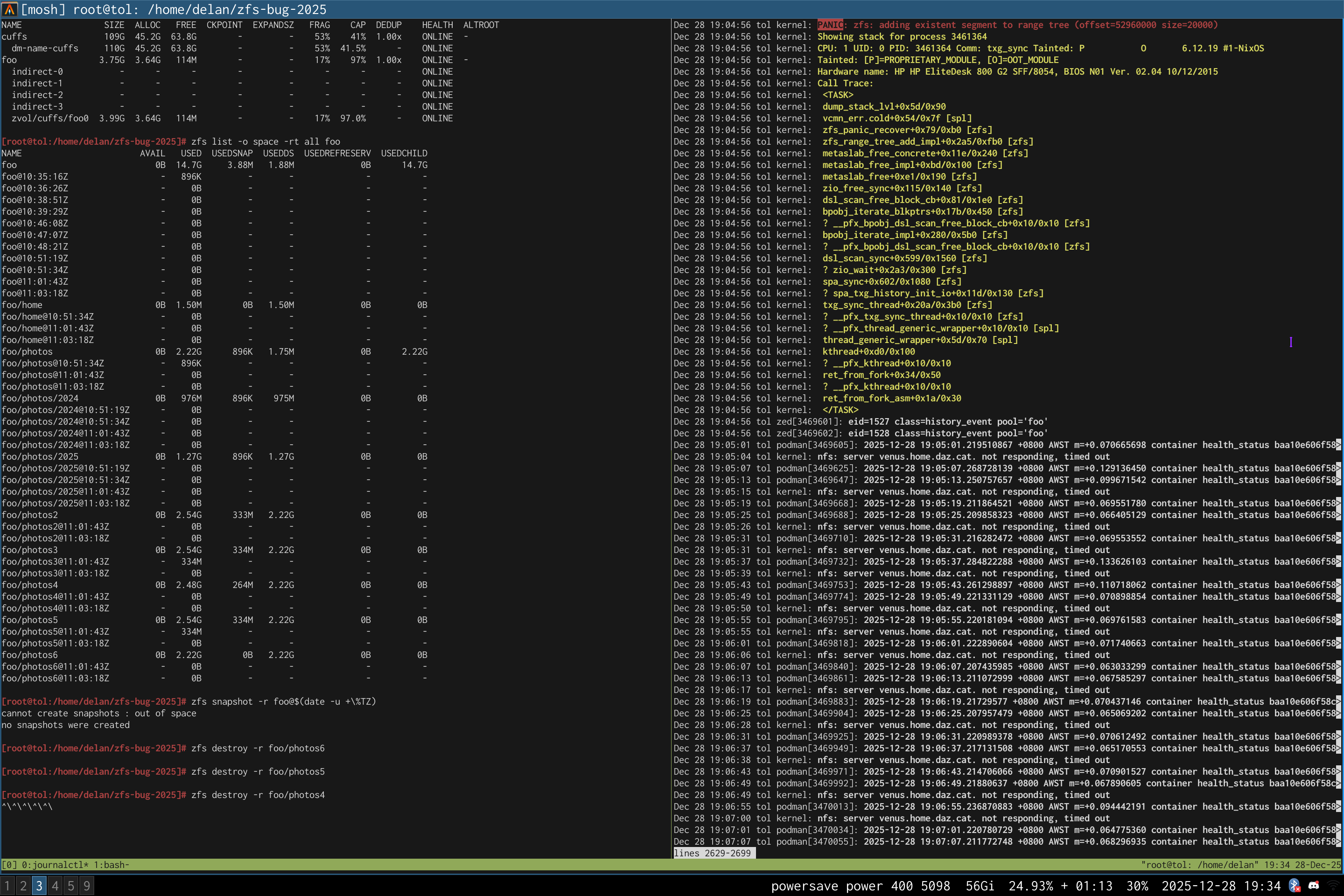
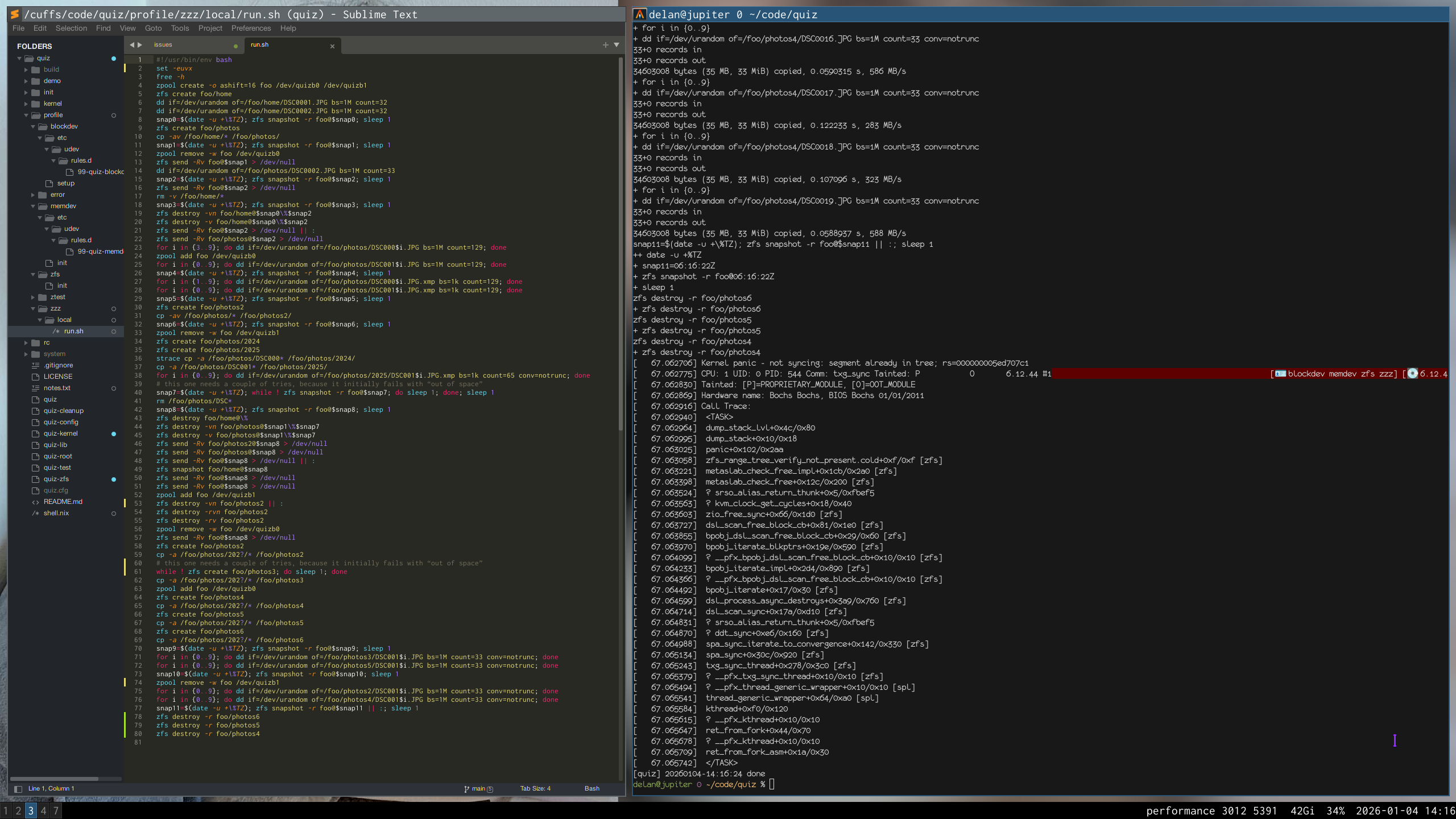
i have a scriptreplay(1) of how i reproduced it, but i would need to clean it up (read: rerecord it) before sharing it publicly. let me know if you need it.
update 2026-01-20: i’ve transcribed the recording and reduced it from over seventy commands to just seven. this is now a regression test in upstream openzfs.
thoughts
on the whole, zfs has been pretty kind to me. it has kept my data safe since 2015, and i have never truly lost any of my data. but it’s not perfect, and i have run into problems with my Big Pool over the years:
-
once or twice i had minor repairable corruption after updating freebsd in my old storage vm (2015–2023), though i don’t remember the cause. i think it was something to do with my hypervisor setup?
-
when migrating my Big Pool from that freebsd vm to the linux host, i went from geli(4) to LUKS2, hitting a gnarly zfs bug that caused tons and tons of minor repairable corruption. this took just over twelve months to fix. many thanks to Rob Norris for getting to the bottom of that one :)
if i were to choose a filesystem to trust, i would choose zfs every time. but no filesystem, no matter how trustworthy it is, can be a substitute for good backup habits and keeping your shit up to date.
this time my backups are older than i would like, so i might lose some of my data. and in general, my approach to computing has been to avoid updating things until i know i need something, because i have too much shit to update and updates often break things, but i could have avoided this by updating to zfs 2.3.2 at any point between may 2025 and september 2025.
you might instead say the lesson is “don’t adopt new features”, because device removal has been around since 2019, but block cloning has only really been around since january 2025 (it first shipped in zfs 2.2.0, but it got killed in 2.2.1). and you probably won’t be surprised to hear that’s what i used to do: as soon as i learned about zpool create -d, i used that whenever i could, carefully deciding which features i wanted on a case-by-case basis and leaving everything else disabled (or even shunning all of those newfangled features with zpool create -o version=28).
but my stance has softened over the last couple years, in part because i now have backups, in part because it turns out solaris-fork-era zfs wasn’t perfect. some bugs took seventeen years to discover and fix!
nothing is perfect. you need backups, and if something is mission critical for you, that something deserves the effort of being kept up to date.