embedding a javascript runtime in rust, part 4: faster handles
previously we created our first real abstraction, a Handle type that represents a javascript object in rust, and keeps the object alive until it’s dropped.
but if we benchmark it, we find that creating and destroying a Handle takes well over 1500ns, which is incredibly inefficient. what gives?
src/main.rs
#![cfg_attr(feature = "bench", feature(test))]
#[cfg(feature = "bench")]
extern crate test;
#[cfg(feature = "bench")]
#[bench]
fn bench(bencher: &mut test::bench::Bencher) {
unsafe {
let ctx = Context::create();
ctx.push_c_function(Some(print), DUK_VARARGS);
ctx.put_global_string(c"print".as_ptr());
ctx.eval_string(cr#"
var HANDLES = {};
var NEXT_HANDLE_KEY = 0;
"#.as_ptr());
ctx.pop();
bencher.iter(|| {
ctx.push_string(c"ao!!".as_ptr());
let handle = Handle::new_from_stack(&ctx, -1);
ctx.pop();
});
}
}$ cargo +nightly bench --features bench
test handle_new_drop ... bench: 1,709.24 ns/iter (+/- 14.79)
8. optimising handles with samply
samply is a sampling profiler that integrates with the excellent firefox profiler.
i used to use cargo-flamegraph, and flamegraph.pl before that, but the firefox profiler UI is so much more powerful (and unlike the perfetto UI, i actually understand how to use it effectively). samply itself is also both faster and easier to use, in large part because it resolves stacks and symbols on the fly, no postprocessing needed.
let’s get samply and perf (required by samply on linux), and while we’re at it, let’s set up mold for faster linking, since we’re gonna be iterating a lot.
shell.nix
with import <nixpkgs> {};
(mkShell.override { stdenv = clangStdenv; }) {
name = "duktest-shell";
LIBCLANG_PATH = lib.makeLibraryPath [ llvmPackages.clang-unwrapped.lib ];
buildInputs = [ samply perf mold ];
RUSTFLAGS = "-Clink-arg=-fuse-ld=mold";
}we’ll need a couple of linux kernel settings too. the former will probably be familiar to anyone who has done profiling on linux, but the latter is also needed to avoid a “Failed to start profiling: mmap failed” error when running samply.
$ echo 1 | sudo tee /proc/sys/kernel/perf_event_paranoid
$ sudo sysctl kernel.perf_event_mlock_kb=2048
now let’s take a profile. for each profile i take, i’ll resolve everything and upload it, so you can see what i’m seeing.
$ cargo +nightly bench --no-run --features bench
$ samply record -- cargo +nightly bench --features bench
8.1. avoiding bytecode compilation (1709ns → 331ns)
focusing on the bencher.iter() closure, 88% of the time is spent in duk_eval_raw(), and 80pp of that is in duk_compile_raw(). we’re compiling NEXT_HANDLE_KEY++ over and over, every single time we create a handle!
https://share.firefox.dev/44UWvlj
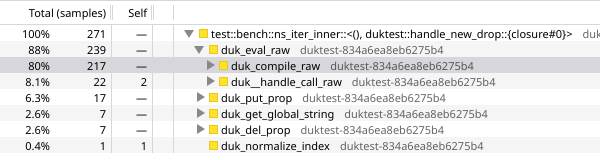
let’s turn that into a function.
diff --git a/src/context.rs b/src/context.rs
index c8090f0..c192483 100644
--- a/src/context.rs
+++ b/src/context.rs
@@ -25,2 +25,5 @@ impl Context {
var NEXT_HANDLE_KEY = 0;
+ function next_handle_key() {
+ return NEXT_HANDLE_KEY++;
+ }
"#.as_ptr());
diff --git a/src/main.rs b/src/main.rs
index 4d13455..7a8ecb4 100644
--- a/src/main.rs
+++ b/src/main.rs
@@ -43,3 +43,4 @@ impl Handle<'_> {
ctx.get_global_string(c"HANDLES".as_ptr());
- ctx.eval_string(c"NEXT_HANDLE_KEY++".as_ptr());
+ ctx.get_global_string(c"next_handle_key".as_ptr());
+ ctx.call(0);
let key = ctx.get_uint(-1);$ cargo +nightly bench --features bench
test handle_new_drop ... bench: 331.94 ns/iter (+/- 3.03)
8.2. caching heap pointers (331ns → 245ns)
now we’re spending 29% of our time in duk_get_global_string(), and 22pp of that in duk_get_prop(). looking up properties is not fast!
https://share.firefox.dev/4gqvc9A
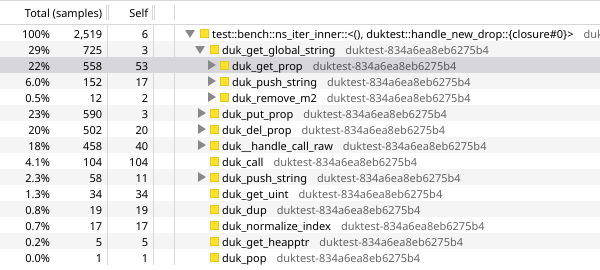
let’s cache the heap pointers for HANDLES and next_handle_key().
diff --git a/src/context.rs b/src/context.rs
index c192483..8d02f0d 100644
--- a/src/context.rs
+++ b/src/context.rs
@@ -7,2 +7,4 @@ pub struct Context {
ctx: *mut duk_context,
+ pub(crate) handles: *mut c_void,
+ pub(crate) next_handle_key: *mut c_void,
}
@@ -31,3 +33,9 @@ impl Context {
- Self { ctx }
+ duk_get_global_string(ctx, c"HANDLES".as_ptr());
+ duk_get_global_string(ctx, c"next_handle_key".as_ptr());
+ let handles = duk_get_heapptr(ctx, -2);
+ let next_handle_key = duk_get_heapptr(ctx, -1);
+ duk_pop_2(ctx);
+
+ Self { ctx, handles, next_handle_key }
}
diff --git a/src/main.rs b/src/main.rs
index ca3c650..07005f1 100644
--- a/src/main.rs
+++ b/src/main.rs
@@ -28,3 +28,3 @@ impl Drop for Handle<'_> {
// `delete HANDLES[rust self.key]`
- self.ctx.get_global_string(c"HANDLES".as_ptr());
+ self.ctx.push_heapptr(self.ctx.handles);
self.ctx.del_prop_index(-1, self.key);
@@ -42,4 +42,4 @@ impl Handle<'_> {
let index = ctx.normalize_index(index);
- ctx.get_global_string(c"HANDLES".as_ptr());
- ctx.get_global_string(c"next_handle_key".as_ptr());
+ ctx.push_heapptr(ctx.handles);
+ ctx.push_heapptr(ctx.next_handle_key);
ctx.call(0);$ cargo +nightly bench --features bench
test handle_new_drop ... bench: 245.00 ns/iter (+/- 8.03)
8.3. avoiding js function calls (245ns → 152ns)
now we’re spending 33% of our time in duk__handle_call_raw(), 33% of our time in duk_put_prop(), and 22% of our time in duk_del_prop().
https://share.firefox.dev/4vmq0qY
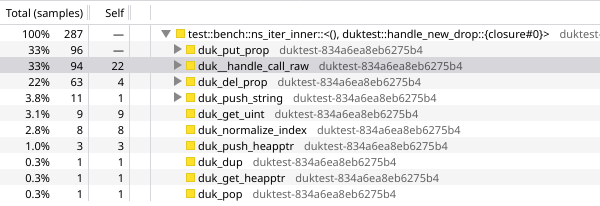
let’s move the steps for generating the next handle key out of javascript entirely. with a u64, we should be able to create 232 new handles per second for 136 years, which is probably good enough. unfortunately duktape doesn’t support bigint yet, so we’ll only be able to create 253 handles without collisions, which comes out to 224 handles per second (59ns each) for 17 years. i don’t feel as comfortable with this, but we’ll replace it with something better soon anyway.
diff --git a/src/context.rs b/src/context.rs
index 8d02f0d..e921295 100644
--- a/src/context.rs
+++ b/src/context.rs
@@ -8,3 +8,3 @@ pub struct Context {
pub(crate) handles: *mut c_void,
- pub(crate) next_handle_key: *mut c_void,
+ pub(crate) next_handle_key: std::sync::atomic::AtomicU64,
}
@@ -26,6 +26,2 @@ impl Context {
var HANDLES = {};
- var NEXT_HANDLE_KEY = 0;
- function next_handle_key() {
- return NEXT_HANDLE_KEY++;
- }
"#.as_ptr());
@@ -34,8 +30,6 @@ impl Context {
duk_get_global_string(ctx, c"HANDLES".as_ptr());
- duk_get_global_string(ctx, c"next_handle_key".as_ptr());
- let handles = duk_get_heapptr(ctx, -2);
- let next_handle_key = duk_get_heapptr(ctx, -1);
- duk_pop_2(ctx);
+ let handles = duk_get_heapptr(ctx, -1);
+ duk_pop(ctx);
- Self { ctx, handles, next_handle_key }
+ Self { ctx, handles, next_handle_key: 0.into() }
}
diff --git a/src/main.rs b/src/main.rs
index 07005f1..3e321e8 100644
--- a/src/main.rs
+++ b/src/main.rs
@@ -20,3 +20,3 @@ struct Handle<'ctx> {
ctx: &'ctx Context,
- key: duk_uint_t,
+ key: u64,
}
@@ -29,3 +29,4 @@ impl Drop for Handle<'_> {
self.ctx.push_heapptr(self.ctx.handles);
- self.ctx.del_prop_index(-1, self.key);
+ self.ctx.push_number(self.key as f64);
+ self.ctx.del_prop(-2);
self.ctx.pop();
@@ -43,5 +44,4 @@ impl Handle<'_> {
ctx.push_heapptr(ctx.handles);
- ctx.push_heapptr(ctx.next_handle_key);
- ctx.call(0);
- let key = ctx.get_uint(-1);
+ let key = ctx.next_handle_key.fetch_add(1, std::sync::atomic::Ordering::SeqCst);
+ ctx.push_number(key as f64);
ctx.dup(index);$ cargo +nightly bench --features bench
test handle_new_drop ... bench: 152.22 ns/iter (+/- 1.02)
8.4. avoiding stringifying integers (152ns → 103ns)
now we’re spending 44% of our time in duk_del_prop() and 39% of our time in duk_put_prop(), with 23pp plus 29pp of that in duk_to_string(). in other words, we’re spending over half of our time stringifying integers in decimal!
https://share.firefox.dev/4ym5iKO
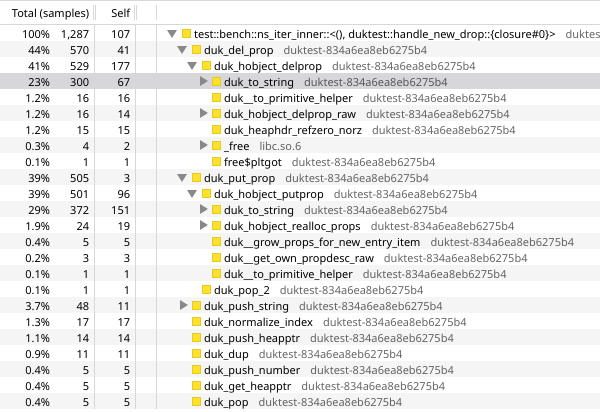
let’s pack the bits of our u64 into a nine-byte string, of the form FF xx xx xx xx xx xx xx xxh. why the leading FFh?
duktape API strings are based on CESU-8, which is like UTF-8 but encodes values above U+FFFF differently and less efficiently (making it not a superset of UTF-8):
// U+10000 LINEAR B SYLLABLE B008 A
duk_eval_string(ctx, cr#""\uD800\uDC00""#.as_ptr());
let mut test_len = 0usize;
let test = duk_get_lstring(ctx, -1, &mut test_len as *mut _);
// CESU-8: `[ed, a0, 80, ed, b0, 80]`
eprintln!("{:02x?}", std::slice::from_raw_parts(test as *const u8, test_len));
duk_pop(ctx);
// UTF-8: `[f0, 90, 80, 80]`
eprintln!("{:02x?}", "\u{10000}".as_bytes());
but they also allow the encoding of:
-
unpaired surrogates, which are necessary to represent javascript strings faithfully. duktape encodes these using the same technique as CESU-8, albeit technically out of spec. the newer, more efficient UTF-8-based counterpart to this approach is WTF-8, created by my (now) colleague Simon Sapin.
-
Symbol values, using byte sequences that are not otherwise valid. for example, Symbol.toPrimitive is
\x81Symbol.toPrimitive\xff.- and “hidden” Symbol values, which can only be created outside javascript, and need not ever be exposed to javascript. notably these have the form
\xfffollowed by any sequence of bytes.
- and “hidden” Symbol values, which can only be created outside javascript, and need not ever be exposed to javascript. notably these have the form
diff --git a/src/main.rs b/src/main.rs
index 3e321e8..61de949 100644
--- a/src/main.rs
+++ b/src/main.rs
@@ -29,3 +29,4 @@ impl Drop for Handle<'_> {
self.ctx.push_heapptr(self.ctx.handles);
- self.ctx.push_number(self.key as f64);
+ let key_symbol = Self::key_to_symbol(self.key);
+ self.ctx.push_lstring(key_symbol.as_ptr() as *const _, key_symbol.len());
self.ctx.del_prop(-2);
@@ -37,2 +38,7 @@ impl Drop for Handle<'_> {
impl Handle<'_> {
+ fn key_to_symbol(key: u64) -> [u8; 9] {
+ let key = key.to_ne_bytes();
+ [0xff, key[0], key[1], key[2], key[3], key[4], key[5], key[6], key[7]]
+ }
+
/// create a handle for the object at `index` on the stack,
@@ -45,3 +51,4 @@ impl Handle<'_> {
let key = ctx.next_handle_key.fetch_add(1, std::sync::atomic::Ordering::SeqCst);
- ctx.push_number(key as f64);
+ let key_symbol = Self::key_to_symbol(key);
+ ctx.push_lstring(key_symbol.as_ptr() as *const _, key_symbol.len());
ctx.dup(index);$ cargo +nightly bench --features bench
test handle_new_drop ... bench: 103.73 ns/iter (+/- 0.67)
8.5. array object fast path (103ns → 79ns)
now we’re spending 39% of our time in duk_push_lstring(), with 37pp of that in duk_heap_strtable_intern(), and we also spend 28% and 16% in duk_put_prop() and duk_del_prop() respectively. in general, javascript property keys are strings, and property accesses require both string interning and hash table lookup.
https://share.firefox.dev/3SWUsdR
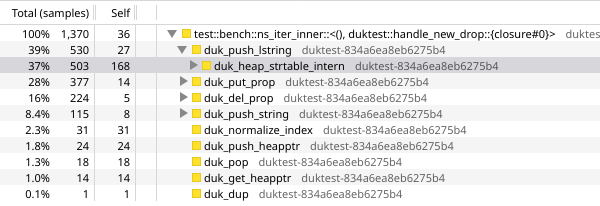
to make most Array objects faster, duktape has a fast path for array index accesses on those objects, which stores values as an array internally. for that fast path to kick in though, we would need to meet a few requirements:
- the object needs to be an Array object
- the array needs to be dense, not sparse (no
deleteholes) - all array index properties need to have default attributes
let’s rework HANDLES to meet these requirements. if we’re gonna store handles as an array, we’ll want to reuse low indices whenever possible, to keep the array only as large as the peak number of concurrent handles.
another reason to reuse low indices is that by definition, an array index is less than 232. my rule of thumb for avoiding collisions in integer id types is that u32 requires reuse to avoid collisions, u64 can be sequentially issued without reuse (up to 232 per second for 136 years), and u128 can be randomly issued without reuse (hence UUIDv4).
when we destroy handles, we can ensure that future handles reuse their keys in constant time and constant extra space, by encoding a free list in their place, and keeping track of the head of that linked list:
-
initial state:
HANDLES = [object, object, object]
head→ none -
destroy handle 1:
HANDLES = [object, null, object]
head→ handle 1 → none -
destroy handle 0:
HANDLES = [1, null, object]
head→ handle 0 → handle 1 → none -
create handle (handle 0):
HANDLES = [object, null, object]
head→ handle 1 → none -
create handle (handle 1):
HANDLES = [object, object, object]
head→ none -
create handle (handle 2):
HANDLES = [object, object, object, object]
head→ none
diff --git a/src/context.rs b/src/context.rs
index e921295..d1f8b65 100644
--- a/src/context.rs
+++ b/src/context.rs
@@ -1,2 +1,2 @@
-use std::{ffi::{CStr, c_char, c_void}, ptr::null_mut};
+use std::{cell::Cell, ffi::{CStr, c_char, c_void}, ptr::null_mut, rc::Rc};
@@ -8,3 +8,4 @@ pub struct Context {
pub(crate) handles: *mut c_void,
- pub(crate) next_handle_key: std::sync::atomic::AtomicU64,
+ pub(crate) next_handle_key: Cell<u32>,
+ pub(crate) free_handle_key: Rc<Cell<Option<u32>>>,
}
@@ -25,3 +26,3 @@ impl Context {
duk_eval_string(ctx, cr#"
- var HANDLES = {};
+ var HANDLES = [];
"#.as_ptr());
@@ -33,3 +34,3 @@ impl Context {
- Self { ctx, handles, next_handle_key: 0.into() }
+ Self { ctx, handles, next_handle_key: 0.into(), free_handle_key: Rc::new(None.into()) }
}
diff --git a/src/main.rs b/src/main.rs
index 61de949..15204c4 100644
--- a/src/main.rs
+++ b/src/main.rs
@@ -20,3 +20,3 @@ struct Handle<'ctx> {
ctx: &'ctx Context,
- key: u64,
+ key: u32,
}
@@ -27,7 +27,10 @@ impl Drop for Handle<'_> {
unsafe {
- // `delete HANDLES[rust self.key]`
+ // `HANDLES[rust self.key] = tombstone`
self.ctx.push_heapptr(self.ctx.handles);
- let key_symbol = Self::key_to_symbol(self.key);
- self.ctx.push_lstring(key_symbol.as_ptr() as *const _, key_symbol.len());
- self.ctx.del_prop(-2);
+ if let Some(old_free_handle_key) = self.ctx.free_handle_key.replace(Some(self.key)) {
+ self.ctx.push_uint(old_free_handle_key);
+ } else {
+ self.ctx.push_null();
+ }
+ self.ctx.put_prop_index(-2, self.key);
self.ctx.pop();
@@ -38,7 +41,2 @@ impl Drop for Handle<'_> {
impl Handle<'_> {
- fn key_to_symbol(key: u64) -> [u8; 9] {
- let key = key.to_ne_bytes();
- [0xff, key[0], key[1], key[2], key[3], key[4], key[5], key[6], key[7]]
- }
-
/// create a handle for the object at `index` on the stack,
@@ -47,10 +45,18 @@ impl Handle<'_> {
unsafe {
- // `HANDLES[NEXT_HANDLE_KEY++] = stack[rust index]`
+ // `HANDLES[key] = stack[rust index]`
let index = ctx.normalize_index(index);
ctx.push_heapptr(ctx.handles);
- let key = ctx.next_handle_key.fetch_add(1, std::sync::atomic::Ordering::SeqCst);
- let key_symbol = Self::key_to_symbol(key);
- ctx.push_lstring(key_symbol.as_ptr() as *const _, key_symbol.len());
+ let key = if let Some(key) = ctx.free_handle_key.get() {
+ ctx.get_prop_index(-1, key.into());
+ let old_free_handle_key = ctx.get_uint(-1);
+ ctx.free_handle_key.set(Some(old_free_handle_key));
+ ctx.pop();
+ key
+ } else {
+ let key = ctx.next_handle_key.get();
+ ctx.next_handle_key.set(key.checked_add(1).expect("too many handles"));
+ key
+ };
ctx.dup(index);
- ctx.put_prop(-3);
+ ctx.put_prop_index(-2, key);
ctx.pop();$ cargo +nightly bench --features bench
test handle_new_drop ... bench: 79.64 ns/iter (+/- 6.64)
https://share.firefox.dev/4pgwq9P
just the beginning
we now have handles that can be created and destroyed in under 80ns.
there’s so much more we can do with handles though! see JSVM, by my friend Alicia, for another duktape binding where the handles:
-
support canonicalisation (at least for java → javascript) – take another handle to the same object, you get the same handle
-
support chaining – drill down into a nested object without creating handles for the intermediate levels, and improve the error messages for type errors